







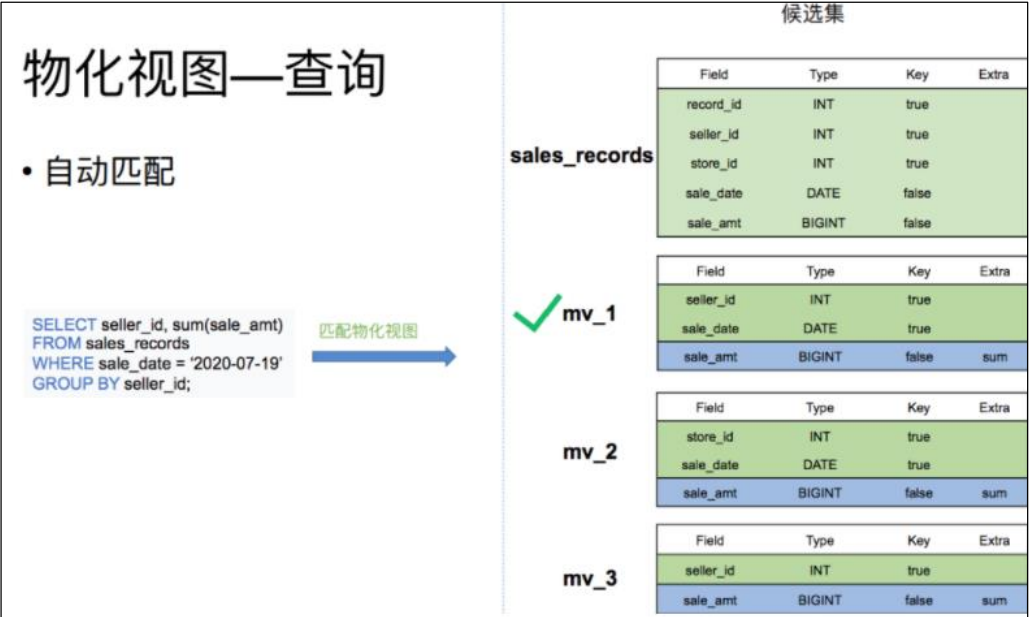
物化视图创建完成后,用户的查询会根据规则自动匹配到最优的物化视图。
比如我们有一张销售记录明细表,并且在这个明细表上创建了三张物化视图。一个存储了不同时间不同销售员的售卖量,一个存储了不同时间不同门店的销售量,以及每个销售员的总销售量。
当查询7月19日,各个销售员都买了多少钱的话。就可以匹配 mv_1 物化视图。直接对 mv_1 的数据进行查询。
查询自动匹配
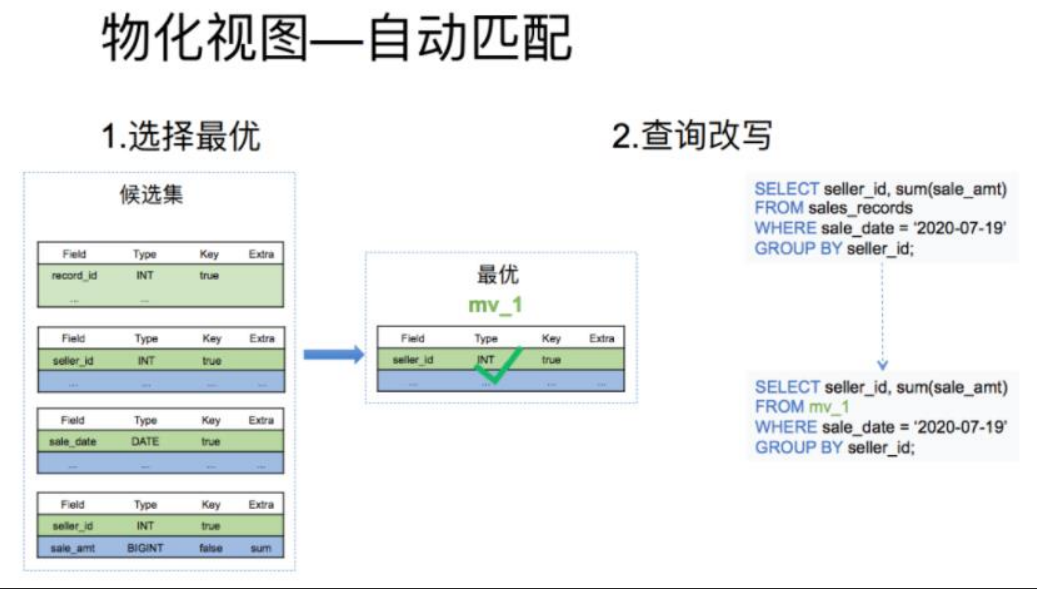
物化视图的自动匹配分为下面两个步骤:
(1)根据查询条件删选出一个最优的物化视图:这一步的输入是所有候选物化视图表的元数据,根据查询的条件从候选集中输出最优的一个物化视图
(2)根据选出的物化视图对查询进行改写:这一步是结合上一步选择出的最优物化视图,进行查询的改写,最终达到直接查询物化视图的目的。

其中 bitmap 和 hll 的聚合函数在查询匹配到物化视图后,查询的聚合算子会根据物化视图的表结构进行一个改写。
最优路径选择
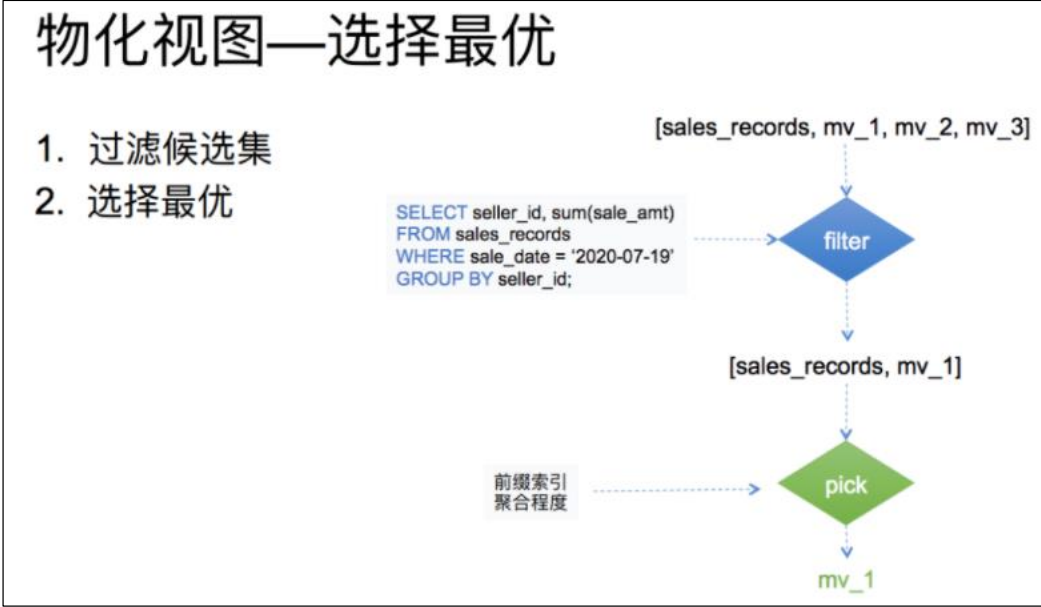
这里分为两个步骤:
(1)对候选集合进行一个过滤。只要是查询的结果能从物化视图数据计算(取部分行,部分列,或部分行列的聚合)出都可以留在候选集中,过滤完成后候选集合大小>=1。
(2)从候选集合中根据聚合程度,索引等条件选出一个最优的也就是查询花费最少物化视图。
这里再举一个相对复杂的例子,来体现这个过程:

候选集过滤目前分为 4 层,每一层过滤后去除不满足条件的物化视图。
比如查询 7 月 19 日,各个销售员都买了多少钱,候选集中包括所有的物化视图以及 base表共 4 个:
第一层过滤先判断查询 where 中的谓词涉及到的数据是否能从物化视图中得到。也就是销售时间列是否在表中存在。由于第三个物化视图中根本不存在销售时间列。所以在这一层过滤中,mv_3 就被淘汰了。
第二层是过滤查询的分组列是否为候选集的分组列的子集。也就是销售员 id 是否为表中分组列的子集。由于第二个物化视图中的分组列并不涉及销售员 id。所以在这一层过滤中,mv_2 也被淘汰了。
第三层过滤是看查询的聚合列是否为候选集中聚合列的子集。也就是对销售额求和是否能从候选集的表中聚合得出。这里 base 表和物化视图表均满足标准。
最后一层是过滤看查询需要的列是否存在于候选集合的列中。由于候选集合中的表均满足标准,所以最终候选集合中的表为 销售明细表,以及 mv_1,这两张。
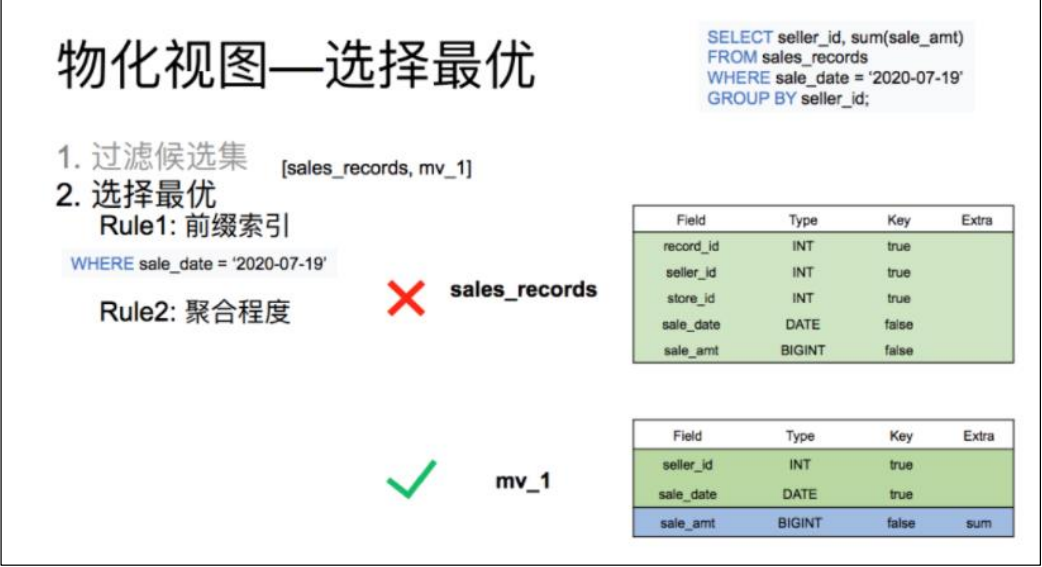
候选集过滤完后输出一个集合,这个集合中的所有表都能满足查询的需求。但每张表的查询效率都不同。这时候就需要再这个集合根据前缀索引是否能匹配到,以及聚合程度的高低来选出一个最优的物化视图。
从表结构中可以看出,base 表的销售日期列是一个非排序列,而物化视图表的日期是一个排序列,同时聚合程度上 mv_1 表明显比 base 表高。所以最后选择出 mv_1 作为该查询的最优匹配。

最后再根据选择出的最优解,改写查询。
刚才的查询选中 mv_1 后,将查询改写为从 mv_1 中读取数据,过滤出日志为 7月19日的 mv_1 中的数据然后返回即可。
查询改写

有些情况下的查询改写还会涉及到查询中的聚合函数的改写。
比如业务方经常会用到 count distinct 对 PV UV 进行计算。
例如:
广告点击明细记录表中存放哪个用户点击了什么广告,从什么渠道点击的,以及点击的时间。并且在这个 base 表基础上构建了一个物化视图表,存储了不同广告不同渠道的用户bitmap 值。
由于 bitmap union 这种聚合方式本身会对相同的用户 user id 进行一个去重聚合。当用户查询广告在 web 端的 uv 的时候,就可以匹配到这个物化视图。匹配到这个物化视图表后就需要对查询进行改写,将之前的对用户 id 求 count(distinct) 改为对物化视图中 bitmap union列求 count。
所以最后查询取物化视图的第一和第三行求 bitmap 聚合中有几个值。
使用及限制

(1)目前支持的聚合函数包括,常用的 sum,min,max count,以及计算 pv ,uv, 留存率,等常用的去重算法 hll_union,和用于精确去重计算 count(distinct)的算法bitmap_union。
(2)物化视图的聚合函数的参数不支持表达式仅支持单列,比如: sum(a+b)不支持。
(3)使用物化视图功能后,由于物化视图实际上是损失了部分维度数据的。所以对表的 DML 类型操作会有一些限制:
如果表的物化视图 key 中不包含删除语句中的条件列,则删除语句不能执行。 比如想要删除渠道为 app 端的数据,由于存在一个物化视图并不包含渠道这个字段,则这个删除不能执行,因为删除在物化视图中无法被执行。这时候你只能把物化视图先删除,然后删除完数据后,重新构建一个新的物化视图。
(4)单表上过多的物化视图会影响导入的效率:导入数据时,物化视图和 base 表数据是同步更新的,如果一张表的物化视图表超过 10 张,则有可能导致导入速度很慢。这就像单次导入需要同时导入 10 张表数据是一样的。
(5)相同列,不同聚合函数,不能同时出现在一张物化视图中,比如:select sum(a), min(a) from table 不支持。
(6)物化视图针对 Unique Key 数据模型,只能改变列顺序,不能起到聚合的作用,所以在 Unique Key 模型上不能通过创建物化视图的方式对数据进行粗粒度聚合操作。















 1039
1039











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









