







Java传家宝:微信公众号(Java传家宝)、Java传家宝-B站、Java传家宝-知乎、Java传家宝-CSND
JMM-->线程安全
java内存模型的主要目标就是定义程序中各个变量的访问细节,即在虚拟机中将变量存储到内存,在从内存取出变量的底层细节。

Java线程
线程比进程更加轻量,线程可以把一个进程的资源分配和任务调度分开,线程既可以共享进程资源,又可以独立调度,线程是cpu调度的基本单位。首先说一下线程的实现方式:
-
使用内核线程实现:由操 作系统支持的线程称为内核线程。线程操作时需要在 用户态和内核态来回切换,代价较高。 -
使用用户线程实现: 非内核线程,线程操作都 在用户态完成,效率很快,但缺少内核支持,需要处理很多问题,包括线程的创建、切换和调度等等。 -
使用用户线程和内核线程结合实现:两者线程实现都存在。
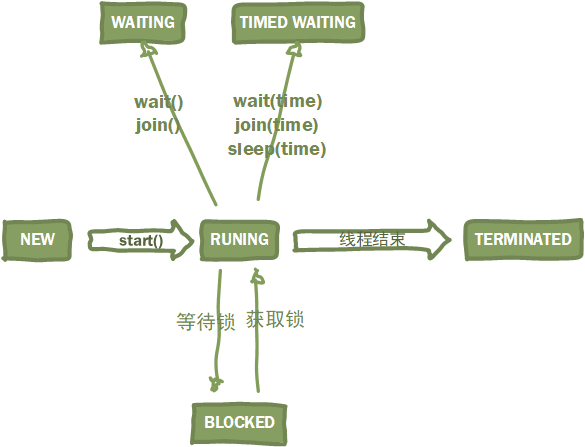
在说回Java线程的实现,通过操作系统的原生线程模型实现。最后,说一下Java线程的各个状态,如图
-
新建(NEW):线程被创建出来,还未启动 -
运行(RUNING):线程正在执行或者等待CPU为其分配执行时间 -
无限期等待(WAITING):CPU不会为其分配执行时间,需要其他线程 唤醒,造成该状态的操作有: -
Object.wait() -
Thread.join() -
LockSupport.park()
-
-
限期等待(TIMED WAITING):CPU不会为其分配执行时间,需要等待 一定时间自动苏醒,造成该状态的操作有: -
Object.wait(time) -
Thread.join(time) -
Thread.sleep() -
LockSupport.parkNanos() -
LockSupport.parkUntil()
-
-
阻塞(BLOCKED):线程在等待获取锁的过程中处于这个状态,获取到锁后解除。 -
结束(TERMINATED):线程结束执行。
工作内存和主内存
-
工作内存:用于存储Java线程用到的 主内存的变量的副本,Java线程对变量的操作都在工作内存进行,每个Java线程都有一个对应的工作内存,且不对其他线程可见。 -
主内存: 虚拟机内存的一部分,存储了线程共享的数据。可以与Java堆的实例数据对应。
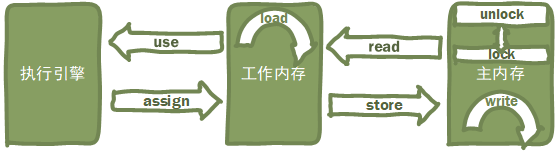
工作内存和主内存如何通信呢?主要通过这八种操作:
| 操作 | 效果 |
|---|---|
| lock/unlock | 为主内存变量加锁/解锁 |
| read/load | 将主内存变量加载到工作内存的变量副本。细分为:read从主内存读取变量到工作内存,load将该变量载入工作内存的变量副本 |
| store/write | 将工作内存变量刷新到主内存。细分为:store将工作内存变量传送到主内存,write将该变量写入工作内存的变量 |
| use/assign | 将工作内存的变量传递给执行引擎/将执行引擎的值赋给工作内存的变量 |
可能结合图解更清晰:
volatile变量
对于寻常变量来说,volatile变量比较特殊,它属于Java虚拟机提供的一种轻量级的同步机制。它包含两两种特性:
-
可见性: volatile变量的变化是对所有线程可见的。即当一个线程对volatile变量进行操作后,对其他线程是立即可见的。 -
禁止指令重排序:即在 volatile变量读写前后都添加内存屏障,如图
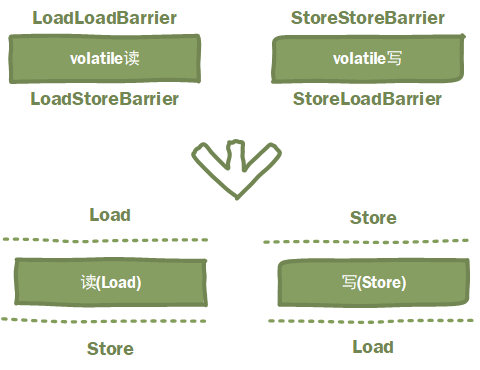
Load表示读,Store表示写,虚线表示内存屏障,内存屏障前后的的操作不能够重排序。
说白了,volatile读就是上读下写不能重排序,volatile写就是上写下读不能重排序。
另外举个经典的例子,说明一下volatile变量的作用:
//双重检验单例模式
class Singleton{
private static volatile Singleton instance = null;
public Singleton getInstance(){
if(instance == null){
synchronized(Singleton.class){
if(instance == null){
instance = new Singleton();
}
}
}
return instance;
}
}
说到这先说一下为什么需要两次判断instance == null的操作:
第一次判断是当还没有实例时,线程进入同步块创建实例。
第二次判断是为了避免线程A进入到同步块后,还没来得及创建实例,切换到线程B执行,此时实例未创建,仍然能进入第一个if判断语句,停止在同步块外等待,直到线程A创建完对象退出同步块后,线程B会进入同步块,如果此时没有第二次判断,那么线程B也会创建一个实例,出现错误。
再说回volatile变量的作用,在上述双重判断后,仿佛已经没有什么问题了。但是如果在深入推敲一下,还存在一个比较严重的问题:
**instance = new Singleton()**分为三部分:
-
为instance对象分配内存 -
初始化instance -
将instance指向分配的内存空间
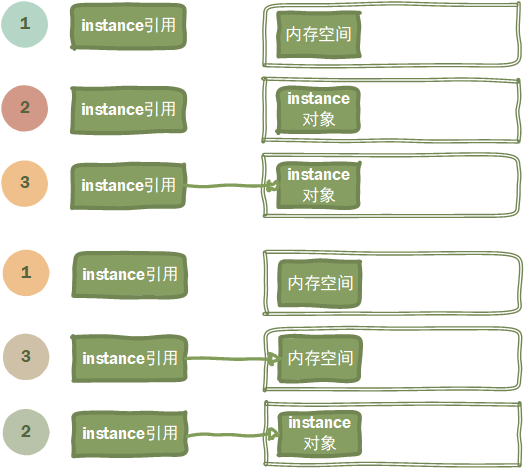
但是在虚拟机中,并不一定按照顺序1==>2==>3执行,也有可能是1==>3==>2,如果是后者,那么就会出现问题:当线程A进入同步块,创建对象,执行到1==>3,还未执行2,此时,切换到线程B,线程B发现instance已经不为空了,直接返回未初始化的对象,出现错误。
而通过volatile修饰后,虚拟机就一定按照1==>2==>3执行,不会出现上述问题。
线程并发安全
首先说一下并发三大特征:
-
原子性:表示一个操作不能够在分割。在 Java中,对于主内存和工作内存的八大操作、基本类型的访问读写(除Long,Double)都是原子性的。还可以通过 synchronized实现范围性的原子操作。 -
可见性:指当一个线程修改了共享变量的值,其他线程能够立即得知这个修改。 在Java中,volatile、final和synchronized实现了可见性。 -
有序性:指线程操作都是有序的。 Java中,volatile和synchronized实现了有序性。
实现并发安全分为互斥同步(阻塞同步)、非阻塞同步和无同步方案。
互斥同步
表示在多个线程在并发访问同一个共享数据时,保证共享数据在同一个时刻只能被一个线程使用。在Java中,通过synchronized和ReentrantLock实现。
Synchronized
Synchronized同步块经过编译后,会在同步块前后生成monitorenter和monitorexit指令,如图

在执行monitorenter指令时,首先需要尝试获取对象锁,如果获取到了,那么锁的计数器就+1,同样的,monitorexit指令会使锁计数器-1,当锁的计数器为0时,锁就被释放。
总结一下Synchronized的特点:
-
可重入 -
阻塞和唤醒线程,需要操作系统介入,就需要从用户态转到内核态,耗费大量时间
ReentrantLock
与Synchronized很相似,可重入,只是代码层面写法有区别,如下
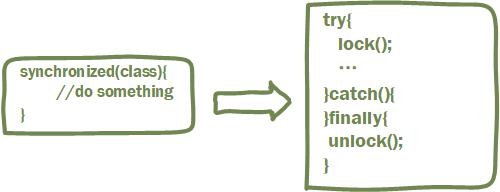
另外,ReentrantLock还有其他几个特点:
-
等待可中断:正在等待的线程可以放弃等待,改为处理其他事情 -
公平锁:按照申请锁的顺序依次获得锁 -
锁绑定多个条件
非阻塞同步
互斥同步属于一种悲观并发策略,无论数据是否会出现竞争,都会进行加锁。而非阻塞同步则属于一种乐观并发策略,只要数据不处于竞争状态,就不加锁。
CAS
Compare And Swap(CAS)比较并交换,需要三个操作数,内存位置V,旧值A,新值B。当CAS执行时,会先判断内存位置上的值是否是旧值A,如果不是,就不做任何操作,如果是,就将值更新为新值B。
//伪代码
if(V == A){
V = B;
}
存在问题:ABA问题,即旧值A更新为B后又更新为A,那么此时进行CAS,他会认为旧值没有做过更改。
无同步方案
并不是所有的并发都需要同步操作实现并发安全,同样存在无同步的方案,包括可重入代码和线程本地存储。
可重入代码
可重入代码是指可以在代码执行的任何时刻中断他,转而去执行另外一段代码。
线程本地存储
在Java中,通过线程本地变量ThreadLocal实现。《深入理解JAVA虚拟机》这样解释:每一个Thread对象中都有一个ThreadLocalMap对象,这个对象存储了一组以ThreadLocal为键,以ThreadLocal.set(Value)中的Value为值得K-V键值对,ThreadLocal对象就是当前线程的ThreadLocalMap访问入口。
其实我们可以通过翻看源码得到更加透彻的认知。首先给个简单的操作示例,ThreadLocal的get(),set()操作的效果:
//最终效果输出:1
public class ThreadLocalLearn {
public static void main(String[] args) {
ThreadLocal<Integer> threadLocal = new ThreadLocal<>();
threadLocal.set(1);
System.out.println(threadLocal.get());
}
}
要弄懂ThreadLocal只要弄明白ThreadLocal的get和set过程:
SET
public void set(T value) {
//1 拿到当前的线程
Thread t = Thread.currentThread();
//2 获取当前线程的ThreadLocalMap对象
ThreadLocalMap map = getMap(t);
if (map != null) {
//3 不为空就直接set
map.set(this, value);
} else {
//4 为空先创建一个ThreadLocalMap对象
createMap(t, value);
}
}
第1步就不说了,看第2步,拿到当前线程的ThreadLocalMap对象,首先看一下ThreadLocalMap对象的结构
// 可以看懂ThreadLocalMap内部采用Entry键值对存储数据,类似一个简易的HashMap
static class ThreadLocalMap {
static class Entry extends WeakReference<ThreadLocal<?>> {
Object value;
Entry(ThreadLocal<?> k, Object v) {
// 键为ThreadLocal对象,使用父类构造器,弱引用
super(k);
// 值为强引用
value = v;
}
}
}
再看第二步**getMap()怎么执行,第四步creatMap()**也顺便解析了:
// ThreadLocalMap默认为空
ThreadLocal.ThreadLocalMap threadLocals = null;
// 直接返回ThreadLocalMap对象
ThreadLocalMap getMap(Thread t) {
return t.threadLocals;
}
// 直接new ThreadLocalMap对象,键为当前线程Thread,值为需要set的值。
void createMap(Thread t, T firstValue) {
t.threadLocals = new ThreadLocalMap(this, firstValue);
}
现在看第三步,ThreadLocalMap.set()操作如何执行:
private Entry[] table;
private void set(ThreadLocal<?> key, Object value) {
// 1 获取当前的key对应索引位置
Entry[] tab = table;
int len = tab.length;
int i = key.threadLocalHashCode & (len-1);
// 2 以索引位置为起点,遍历table后面的数据:
for (Entry e = tab[i]; e != null; e = tab[i = nextIndex(i, len)]) {
// 2.1 不为空 获取当前位置存储的key
ThreadLocal<?> k = e.get();
// 2.1.2 如果当前key与传入的key相同,更新值返回即可
if (k == key) {
e.value = value;
return;
}
// 2.1.3 如果key为null,说明当前位置的key已经被回收了,更新key和value返回
if (k == null) {
replaceStaleEntry(key, value, i);
return;
}
// 2.1.4 如果都没返回,通过nextIndex(i, len)线性探测,找下一个索引位置
}
// 2.2 如果为空 以传入的KV创建Entry对象
tab[i] = new Entry(key, value);
int sz = ++size;
if (!cleanSomeSlots(i, sz) && sz >= threshold)
rehash();
}
GET
public T get() {
// 1 获取当前线程
Thread t = Thread.currentThread();
// 2 获取当前线程的ThreaLocalMap对象
ThreadLocalMap map = getMap(t);
if (map != null) {
// 3 不为空 获取其Entry对象
ThreadLocalMap.Entry e = map.getEntry(this);
if (e != null) {
// 4 不为空 直接返回值
@SuppressWarnings("unchecked")
T result = (T)e.value;
return result;
}
}
// 5 ThreadLocalMap或者Entry为空,返回设置初始值并返回
return setInitialValue();
}
第一步和第二步与set一致,不在赘述。现在看第三步,获取ThreadLocalMap的Entry对象的过程:
private Entry getEntry(ThreadLocal<?> key) {
// 拿到索引
int i = key.threadLocalHashCode & (table.length - 1);
// 取到Entry对象
Entry e = table[i];
if (e != null && e.get() == key)
// 如果不为空,且取到的Entry存储的key与传入的key一致,直接返回值
return e;
else
// key!=null否则线程探测向下查找与传入的key一致为止
// key==null,将该位置的值设置为null,rehash调整
return getEntryAfterMiss(key, i, e);
}
/*
为什么存在于key不一致呢?
1是因为在set时,通过线性探测解决了hash冲突key的hash值不一定就是它真正的索引
2是因为可能被回收了,此时该位置的key==null
*/
最后放一张示意图,更好的理解ThreadLocal:
















 643
643











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









