






在开发过程中,当项目投入使用时,经常会遇到单表数据库过大,导致查询性能变慢,应用程序的性能变下降等等。可以使用表分区的方法来进行优化;
分区是在物理层面将一个表按照某种方式分成多块,逻辑上还是一张表;多个分区可以单独管理,甚至存放在不同的磁盘/文件系统上,提升效率。
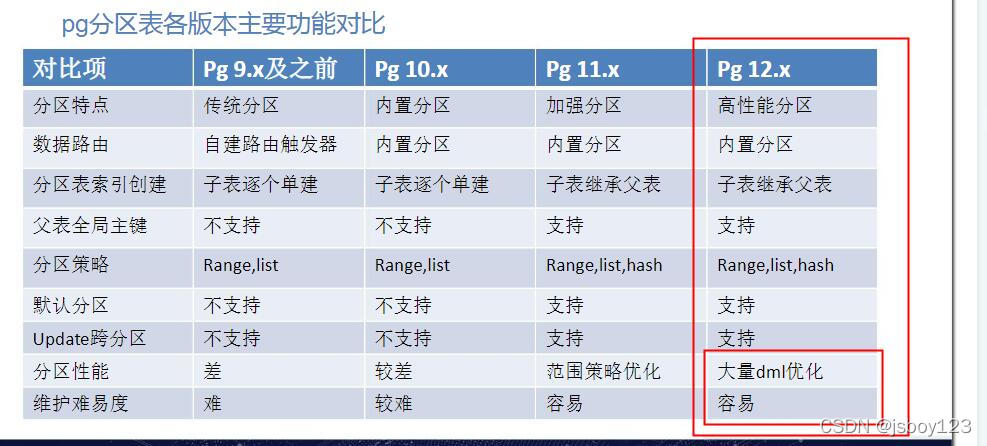
这里我们使用的是pgstgresql,不同的版本针对表分区的功能不同。
- pg10.x 以前只能通过继承+触发器的方式创建分区表
- postgresql版本在10.x之后提供了内置分区表,只支持range和list分区,11.x版本支持hash分区
- pg11之前只能单独为每个分区表建立索引,且不能在父表上建立主键,索引等。pg11后可以对父表建立索引,分区子表自动创建。
- 分区表不允许其他表作为外键引用
- 分区表的数据是通过操作父表进行插入操作的
range 范围分区
通过值的范围来进行分区, 例如时间, 数字等. 不过要注意数据范围是左闭右开;
根据id进行分表
create table test(
id int not null primary key,
name varchar not null
) partition by range (id);创建子分区
create table test1 partition of test for values from (1) to (5);
create table test2 partition of test for values from (5) to (10);
create table test3 partition of test for values from (10) to (15);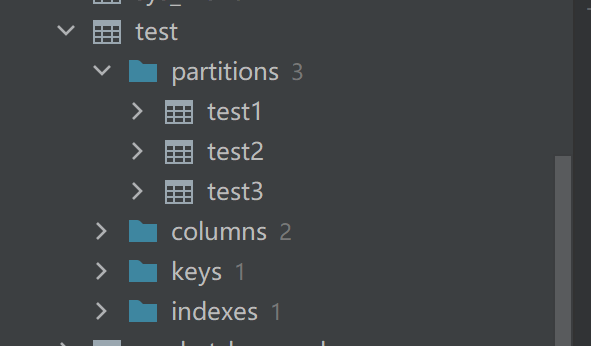
插入数据
insert into test(id, name) values (5, '张三');查询主表能查询到所有的数据,而查询字表就只能查询到该字表的数据;因为插入的 id = 5 ,只有在子表test2中有数据,test1和test3 是没有的;
select * from test2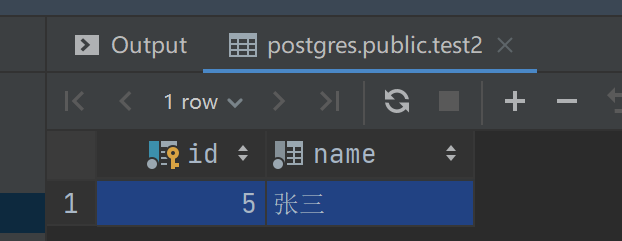
高版本:
- 分区表的数据,只需要对父表进行操作处理即可。
- 子分区表会自动继承父表,添加索引等信息的时候,无需单独分别对分区表进行操作。
- 通过DDL信息查看分区表权限授予也是和父表的一样。
list 列表分区
通过固定列表里的值进行分区
create table test(
id int not null primary key,
name varchar not null
) partition by list (id);创建字表
create table test1 partition of test for values in(1,2,3,4);
create table test2 partition of test for values in(5,6,7,8);
create table test3 partition of test for values in(9,10,11,12);插入数据
insert into test(id, name) VALUES (9, '李四');查询子表
select * from test3;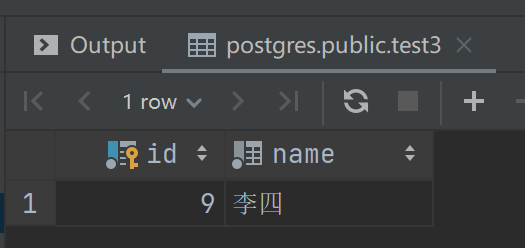
hash 哈希分区
根据 hash 算法进行分区,字段取哈希值后再分区;
create table test(
id int not null primary key,
name varchar not null
) partition by hash(id);create table test1 partition of test for values with (modulus 3, remainder 0);
create table test2 partition of test for values with (modulus 3, remainder 1);
create table test3 partition of test for values with (modulus 3, remainder 2);插入数据
insert into test(id, name) VALUES (3, '李四');select * from test2;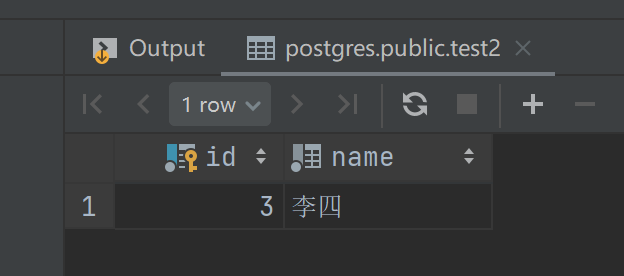
Multi-level 多级分区
分区的分区, 可以将上述 3种分区方式混合使用. 例如: 先对表按照时间分区, 再对子表按照状态再次分区
创建主表,以range根据id分区
create table test(
id int not null primary key,
name varchar not null
) partition by range (id);创建子表,并以list根据id再次分区
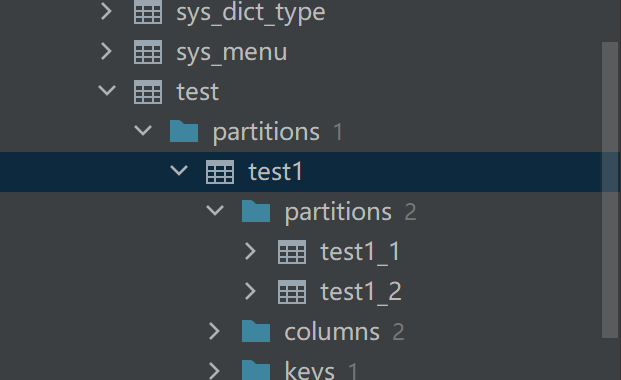
create table test1 partition of test for values from (1) to (5) partition by list(id);创建子子表
create table test1_1 partition of test1 for values in (1,2);
create table test1_2 partition of test1 for values in (3,4,5);
如果数据量大,手动分区比较麻烦,我们可以使用插件进行分区;
pg_partman
当我们创建分区后,数据量比较大,甚至超过了我们定义的字表范围时,在插入数据时,就会报错,因为并没有对应的字表,这时就需要自动创建表;
- 触发器:为主表创建触发器。
- 定时任务:每隔一段时间创建字表,可以使用pgsql中的pg_cron 定时任务。















 4153
4153











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









