









1. 互联网金融风控体系
1.1 信贷审批业务基本流程
- 四要素认证:银行卡持有人的姓名、身份证号、银行卡号、手机号
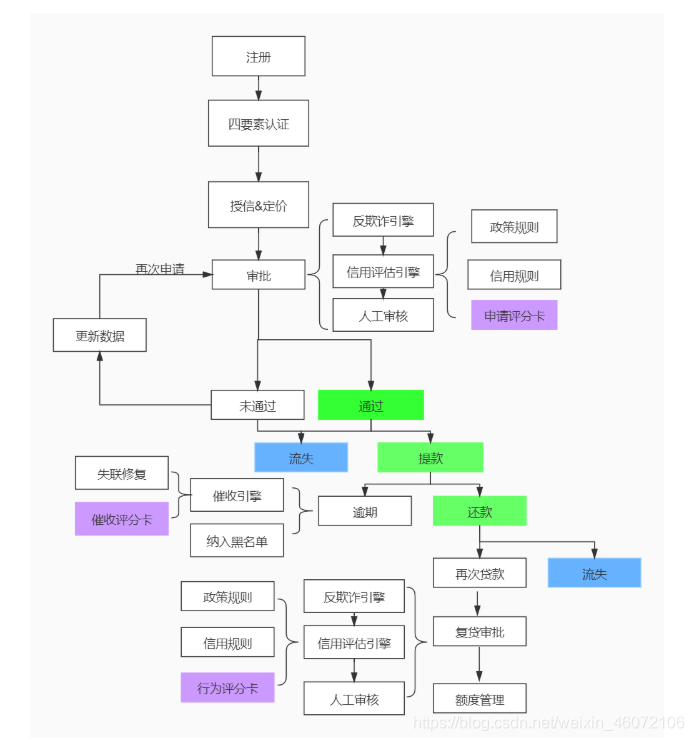
1.2 组成
1. 用户数据
1.1 分类
- 用户基本信息(联系人,通讯录,学历…)
- 用户行为信息(操作APP时的行为,注册,点击位置…)
- 用户授权信息(运营商,学信网,设备IMEI…)
- 外部接入信息(P2P信贷,其它金融机构如芝麻信用分…)
1.2 获取
- 数据采集会涉及到埋点和爬虫技术,基本上业内的数据都大同小异。
- 免费的运营商数据
- 安卓可爬的手机内部信息(app名称,手机设备信息,部分app内容信息)
- 收费的征信数据、各种信息校验、外部黑名单之类的
- 特定场景的现金贷和消费金融会有自有的数据可供使用
- 比如阿里京东自己的电商数据
- 滴滴的司机数据、顺丰中通的快递数据
2. 策略体系
- 反欺诈规则
- 准入规则
- 运营商规则
- 风险名单
- 网贷规则
3. 机器学习模型
- 欺诈检测模型
- 准入模型
- 授信模型
- 风险定价
- 额度管理
- 流失预警
- 失联修复

2. 风控建模流程
2.1 ABC评分卡
- 风控模型其中包含了A/B/C卡
- 模型可以采用相同算法,一般以逾期天数来区分正负样本,也就是目标值Y的取值(0或1)
- 贷前 申请评分卡 Application score card
- 贷中 行为评分卡 Behavior score card
- 贷后 催收评分卡 Collection score card
- A B逾期的客户是正样本
- C卡因为用途不同Y的取值可能有区别
- 公司有内催,有外催。外催回款率低,单价贵
- 可以根据是否被内催催回来定义C卡的Y
- C 能够被内催催回来的客户
2.2 机器学习模型的完整工程流程
- 准备
- 明确需求
- 模型设计
- 业务抽象成分类/回归问题
- 定义标签(目标值)
- 样本设计
- 特征工程
- 数据处理,选取合适的样本,并匹配出全部的信息作为基础特征
- 特征构建
- 特征评估
- 模型
- 模型训练
- 模型评价
- 模型调优
- 上线运营
- 模型交付
- 模型部署
- 模型监控
2.3 项目准备期
1. 明确需求
- 目标人群:新客,优质老客,逾期老客
- 给与产品:额度,利率
- 市场策略:冷启动,开拓市场,改善营收
- 使用时限:紧急使用,长期部署
- 举例
- 业务需要针对全新客户开放一个小额现金贷产品,抢占新市场
- 针对高风险薄数据新客的申请评分卡
2. 模型设计
2.1 业务抽象成分类/回归问题
- 风控场景下问题通常都可以转化为二分类问题:
- 信用评分模型期望用于预测一个用户是否会逾期,逾期用户1
- 营销模型期望用于预测一个用户被营销后是否会来贷款,没贷用户1
- 失联模型期望用于预测一个用户是否会失联,失联用户1
- 风控业务中,只有欺诈检测不是二分类问题
2.2 模型算法
- 规则模型
- 逻辑回归
- 集成学习
- 融合模型
2.3 模型输入
- 数据源
- 时间跨度
2.4 Y标签定义
- 在构建信贷评分模型时,原始数据中只有每个人的当前逾期情况,没有负样本,负样本需要人为构建
- 通常选一个截断点(阈值),当逾期超过某个阈值时,就认定该样本是一个负样本,未来不会还钱
- 比如逾期15天为正负样本的标记阈值,Y = 1的客户均是逾期超过15天的客户
- 只会将按时还款和逾期较少的那一部分人标记为Y = 0。如:将逾期<5天和没有逾期的人作为正样本
- 逾期5~15天的数据(灰样本)会从样本中去掉,去掉“灰样本”,会使样本分布更趋于二项分布,对模型学习更加有利。
- “灰样本”通常放入测试集中,用于确保模型在训练结束后,对该部分样本也有区分能力。
2.5 样本选取
1. 样本特性
- 代表性:样本必须能够充分代表总体。如消费贷客群数据不能直接用到小额现金贷场景
- 充分性:样本集的数量必须满足一定要求。评分卡建模通常要求正负样本的数量都不少于1500个。随着样本量的增加,模型的效果会显著提升
- 时效性:在满足样本量充足的情况下,通常要求样本的观测期与实际应用时间节点越接近越好。如银行等客群稳定的场景,观察期可长达一年半至两年。
- 排除性(Exclusion):虽然建模样本需要具有代表整体的能力,但某些法律规定不满足特定场景贷款需求的用户不应作为样本,如对行为评分卡用户、无还款表现或欺诈用户均不应放入当前样本集。
- 评分卡建模通常要求正负样本的数量>=1500,但当总样本量超过50000个时,许多模型的效果不再随着样本量的增加而有显著提升,而且数据处理与模型训练过程通常较为耗时。
2. 样本数量
- 如果样本量过大,会为训练过程增加不必要的负担,需要对样本做欠采样(Subsampling)处理。由于负样本通常较少,因此通常只针对正样本进行欠采样。
- 常见的欠采样方法分为:
- 随机欠采样:直接将正样本欠采样至预期比例
- 分层抽样:保证抽样后,开发样本、验证样本与时间外样本中的正负样本比例相同。
- 等比例抽样:将正样本欠采样至正负样本比例相等,即正样本量与负样本量之比为1:1。 需要注意的是,采样后需要为正样本添加权重。如正样本采样为原来的1/4,则为采样后的正样本增加权重为4,负样本权重保持为1。因为在后续计算模型检验指标及预期坏账时,需要将权重带入计算逻辑,才可以还原真实情况下的指标估计值,否则预期结果与实际部署后的结果会有明显偏差。
- 而当负样本较少的时候,需要进行代价敏感加权或过采样(Oversampling)处理
3. 样本时期
- 观察期是指用户申请信贷产品前的时间段
- 表现期是定义好坏标签的时间窗口,如果在该时间窗口内触发坏定义就是坏样本,反之就是好样本。
- 举例: 要建立A卡模型, 观察期12个月,表现期3个月
- 用户贷款前12个月的历史行为表现作为变量,用于后续建模
- 如设定用户在到期3个月内未还款,即认为用户为负样本,则称表现期为3个月
- 举例: 要建立A卡模型, 观察期12个月,表现期3个月

4. 样本划分
- 开发样本(Develop):开发样本与验证样本使用分层抽样划分,保证两个数据集中负样本占比相同
- 验证样本(Valuation): 开发样本与验证样本的比例为6:4
- 时间外样本(Out of Time,OOT): 通常使用整个建模样本中时间最近的数据, 用来验证模型对未来样本的预测能力,以及模型的跨时间稳定性。
5. 应用

3. 样本设计
- 选取客群:新客,未逾期老客,逾期老客
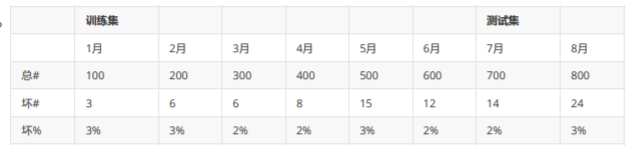
- 客群描述:首单用户、内部数据丰富、剔除高危职业、收入范围在XXXX
- 客群标签:好: FPD<=30 坏: FPD>30
2.4 特征工程
1. 数据调研
- 明确对目标人群有哪些可用数据, 明确数据获取逻辑
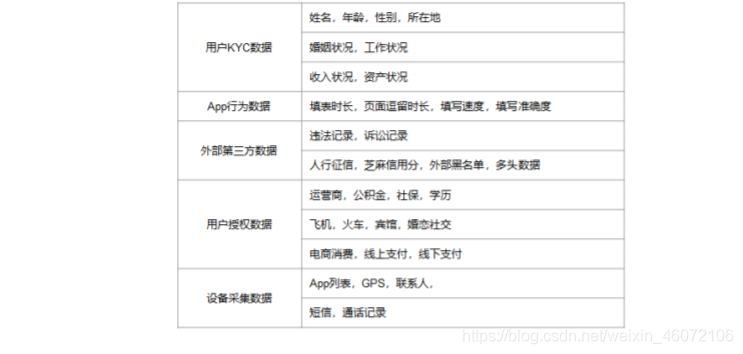
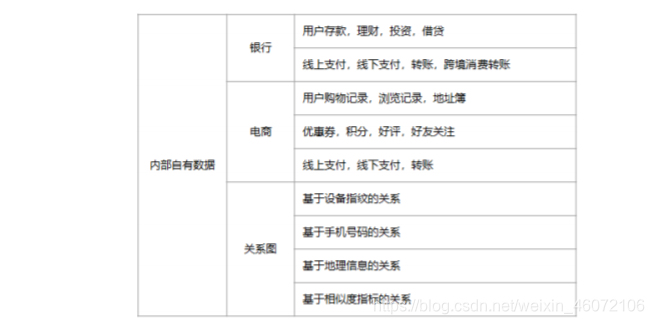
- 明确数据的质量,覆盖度,稳定性
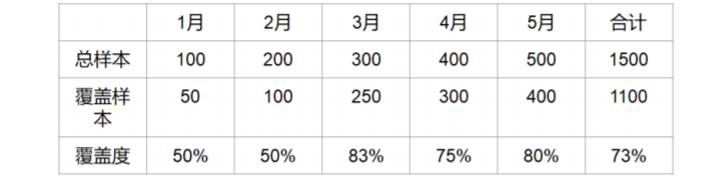
2. 特征构建
1. 构建特征之前注意事项
- 明确数据源对应的具体数据表
- 明确数据是从哪里来的: (DE Data Engineer 数仓工程师)

- 数据分析师拿到的数据可能是:
数仓原始表
数仓重构表 - 数仓原始表和数仓重构表可能数据量有差异,因为更新时间不同!
尽量使用数仓工程师加工好的重构表,确保逻辑统一
实时预测要确保生产数据库和数据仓库数据一致 (很难)
- 画出类ER图 数据关系 一对一,一对多,多对多

- 写SQL查询时要从 用户列表出发, Join其它表
- 不能出现SELECT DISTINCT user_id FROM order_table
- 明确评估特征的样本集
- 新申请客户没有内部信贷数据
- 未逾期老客户当期没有逾期信息
- 逾期老客户和未逾期老客的还款数据一定差别很大
- 如何从原始数据中构建特征:指定特征框架,确保对数据使用维度进行了全面思考
- 每个属性都可以从R(Recency) F(Frequency) M(Monetary)三个维度思考,来构建特征
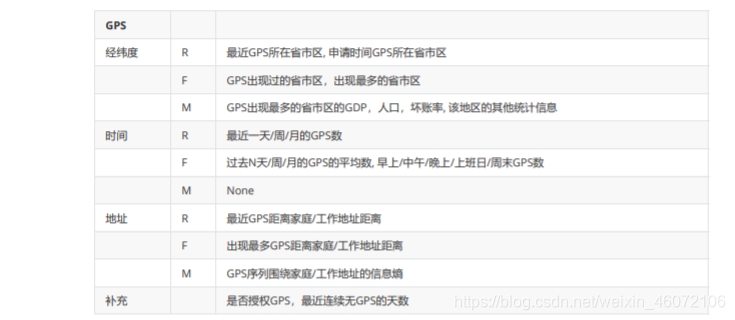
5. 特征构建方法
- 用户静态信息特征:用户的姓名,性别,年龄
- 用户时间截面特征:
- 截面时点电商购物GMV
- 截面时点银行存款额
- 截面时点逾期最大天数
- 用户时间序列特征 用户过去一个月的GPS数据 用户过去六个月的银行流水 用户过去一年的逾期记录
3. 特征评估
3.1 条件
- 评估指标 覆盖度高
- 很多用户都能使用稳定,在后续较长时间可以持续使用PSI (Population Stability Index)
- 区分度好,好坏用户的特征值差别大IV (Information Value)
- 用模型的评估指标来评估特征:单特征AUC, 单特征KS
- 可以拿效果最好的单特征的AUC,KS来估计模型的效果
3.2 特征评估报表
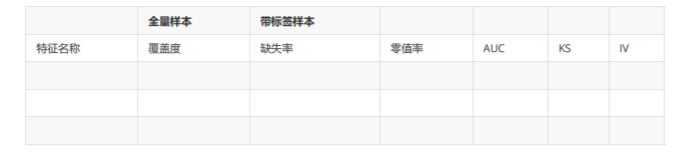
- 全量样本—覆盖度:全量样本上,有多少用户有这个特征
- 全量样本:包含不带标签的样本
- 缺失率:带标签样本缺失率,与全量样本覆盖度作对比,看差距是不是很大,选择差距不大的特征
- 零值率:好多特征是计数特征,比如电商消费单数,通信录记录数,GPS数据,如零值太多,特征不好
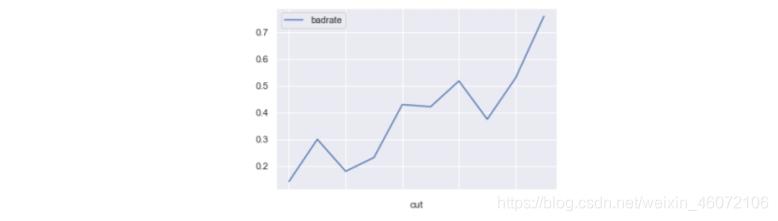
- 剔除风险趋势不合逻辑的特征,用常识和业务逻辑去评估
2.5 模型构建
1. 设计实验
- 训练模型时有很多可能的因素会影响模型效果
- 需要通过设计实验去验证哪些因素是会提升模型效果的
2. 模型评估
- 好的模型需要满足的条件:稳定,在后续较长时间可以持续使用PSI (Population Stability Index)区分度好,好坏用户的信用分差别大AUC, KS, GINI
- 报表一:区分度,抓坏人能力在不同分段的表现
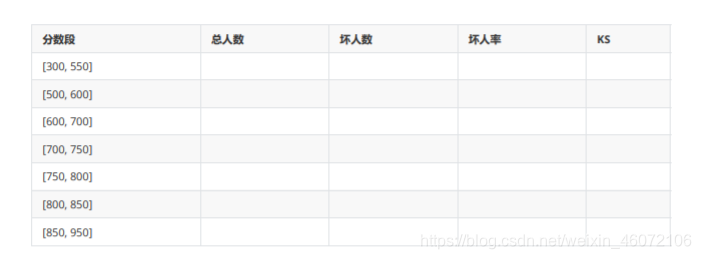
- 报表二:跨时间稳定性

2.6 上线运营
1. 模型交付
1.1 交付流程
- 提交特征和模型报表
- 离线结果质量复核 (无缺失,无重复,存储位置正确,文件名规范)
- 保存模型文件,确定版本号,提交时间
- 老大审批,通知业务方
- 线上部署,案例调研, 持续监控
1.2 特征报告
- 特征项目需求
- 特征项目任务列表
- 特征项目时间表
- 类ER图
- 样本设计
- 特征框架
- 每周开发进度和结果
- 每周讨论反馈和改进意见笔记
- 特征项目交付说明
- 特征项目总结
1.3 模型报告
- 模型项目需求
- 模型项目任务列表
- 模型项目时间表
- 模型设计
- 样本设计
- 模型训练流程和实验设计
- 每周开发进度和结果
- 每周讨论反馈和改进意见笔记
- 模型项目交付说明
- 模型项目总结
2. 模型部署
- 确保开发环境和生产环境一致性
- 使用PMML文件或Flask API进行部署
- 一定要做:对一批客户进行离线打分和线上打分,确保离线结果和线上结果一致
3. 模型监控
- 特征监控:特征稳定性
- 模型监控:模型稳定性
3. 业务规则挖掘
3.1 简介
1. 风险规避手段
- AI模型
- 规则
2. 使用规则进行风控
- 使用一系列判断逻辑对客户群体进行区分,不同群体逾期风险有显著差别
- 举例:多头借贷数量是否超过一定数量
- 如果一条规则将用户划分到高风险组,则直接拒绝,如果划分到低风险组则进入到下一规则
3. 规则 和 AI模型的优缺点
- 规则,可以快速使用,便于业务人员理解,但判断相对简单粗暴一些,单一维度不满足条件直接拒绝
- AI模型,开发周期长,对比使用规则更复杂,但更灵活,用于对风控精度要求高的场景
3.2 应用
1. 案例背景
- 某互联网公司拥有多个业务板块,每个板块下都有专门的贷款产品
- 外卖平台业务的骑手可以向平台申请“骑手贷”
- 电商平台业务的商户可以申请“网商贷”
- 网约车业务的司机可以向平台申请“司机贷”
- 公司有多个类似的场景,共用相同的规则引擎及申请评分卡,贷款人都是该公司的兼职人员
- 近期发现,“司机贷”的逾期率较高
- 整个金融板块30天逾期率为1.5%
- “司机贷”产品的30天逾期达到了5%
2. 期望解决方案
- 现有的风控架构趋于稳定
- 希望快速开发快速上线,解决问题
- 尽量不使用复杂的方法
- 考虑使用现有数据挖掘出合适的业务规则
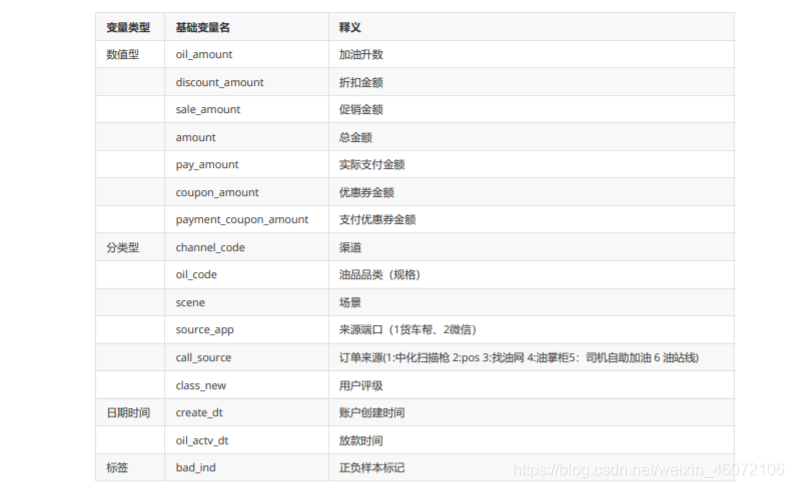
3. 数据字典
4. 实现
4.1 加载数据
import pandas as pd
import numpy as np
data = pd.read_excel('data/rule_data.xlsx')
data.head()
4.2 查看数据分布情况
- 查看class_new
data.class_new.unique()
-
原始数据的特征太少,考虑在原始特征基础上衍生出一些新的特征来,将特征分成三类分别处理
- 数值类型变量:按照id分组后,采用多种方式聚合,衍生新特征
- 分类类型变量,按照id分组后,聚合查询条目数量,衍生新特征
- 其它:日期时间类型,是否违约(标签),用户评级等不做特征衍生处理
org_list = ['uid','create_dt','oil_actv_dt','class_new','bad_ind']
agg_list =['oil_amount','discount_amount','sale_amount','amount','pay_amount','coupon_amount','payment_coupon_amount']
count_list = ['channel_code','oil_code','scene','source_app','call_source']
- 创建数据副本,保留底表,并查看缺失情况
df = data[org_list].copy()
df[agg_list] = data[agg_list].copy()
df[count_list] = data[count_list].copy()
df.isna().sum()
- 查看数值型变量的分布情况
df.describe()
- 缺失值填充
- 对creat_dt做补全,用oil_actv_dt来填补
- 截取申请时间和放款时间不超过6个月的数据据(考虑数据时效性)
def time_isna(x,y):
if str(x) == 'NaT':
x = y
return x
df2 = df.sort_values(['uid','create_dt'],ascending = False)
df2['create_dt'] = df2.apply(lambda x: time_isna(x.create_dt,x.oil_actv_dt),axis = 1)
df2['dtn'] = (df2.oil_actv_dt - df2.create_dt).apply(lambda x :x.days)
df = df2[df2['dtn']<180]
df.head()
- 将用户按照id编号排序,并保留最近一次申请时间,确保每个用户有一条记录
base = df[org_list]
base['dtn'] = df['dtn']
base = base.sort_values(['uid','create_dt'],ascending = False)
base = base.drop_duplicates(['uid'],keep = 'first')
base.shape
- 特征衍生
- 对连续统计型变量进行函数聚合
- 方法包括对历史特征值计数、求历史特征值大于0的个数、求和、求均值、求最大/小值、求最小值、求方差、求极差等
gn = pd.DataFrame()
for i in agg_list:
tp = df.groupby('uid').apply(lambda df:len(df[i])).reset_index()
tp.columns = ['uid',i + '_cnt']
if gn.empty:
gn = tp
else:
gn = pd.merge(gn,tp,on = 'uid',how = 'left')
#求历史特征值大于0的个数
tp = df.groupby('uid').apply(lambda df:np.where(df[i]>0,1,0).sum()).reset_index()
tp.columns = ['uid',i + '_num']
if gn.empty:
gn = tp
else:
gn = pd.merge(gn,tp,on = 'uid',how = 'left')
#求和
tp = df.groupby('uid').apply(lambda df:np.nansum(df[i])).reset_index()
tp.columns = ['uid',i + '_tot']
if gn.empty:
gn = tp
else:
gn = pd.merge(gn,tp,on = 'uid',how = 'left')
#求平均值
tp = df.groupby('uid').apply(lambda df:np.nanmean(df[i])).reset_index()
tp.columns = ['uid',i + '_avg']
if gn.empty:
gn = tp
else:
gn = pd.merge(gn,tp,on = 'uid',how = 'left')
#求最大值
tp = df.groupby('uid').apply(lambda df:np.nanmax(df[i])).reset_index()
tp.columns = ['uid',i + '_max']
if gn.empty:
gn = tp
else:
gn = pd.merge(gn,tp,on = 'uid',how = 'left')
#求最小值
tp = df.groupby('uid').apply(lambda df:np.nanmin(df[i])).reset_index()
tp.columns = ['uid',i + '_min']
if gn.empty:
gn = tp
else:
gn = pd.merge(gn,tp,on = 'uid',how = 'left')
#求方差
tp = df.groupby('uid').apply(lambda df:np.nanvar(df[i])).reset_index()
tp.columns = ['uid',i + '_var']
if gn.empty:
gn = tp
else:
gn = pd.merge(gn,tp,on = 'uid',how = 'left')
#求极差
tp = df.groupby('uid').apply(lambda df:np.nanmax(df[i]) -np.nanmin(df[i]) ).reset_index()
tp.columns = ['uid',i + '_ran']
if gn.empty:
gn = tp
else:
gn = pd.merge(gn,tp,on = 'uid',how = 'left')
- 查看衍生结果
gn.columns
- 对dstc_lst变量求distinct个数
gc = pd.DataFrame()
for i in count_list:
tp = df.groupby('uid').apply(lambda df: len(set(df[i]))).reset_index()
tp.columns = ['uid',i + '_dstc']
if gc.empty:
gc = tp
else:
gc = pd.merge(gc,tp,on = 'uid',how = 'left')
- 将变量组合在一起
fn = pd.merge(base,gn,on= 'uid')
fn = pd.merge(fn,gc,on= 'uid')
fn.shape
- merge过程中可能会出现缺失情况,填充缺失值
fn = fn.fillna(0)
fn.head(100)
- 训练决策树模型
x = fn.drop(['uid','oil_actv_dt','create_dt','bad_ind','class_new'],axis = 1)
y = fn.bad_ind.copy()
from sklearn import tree
dtree = tree.DecisionTreeRegressor(max_depth = 2,min_samples_leaf = 500,min_samples_split = 5000)
dtree = dtree.fit(x,y)
- 输出决策树图像,并作出决策
- 需要安装 Graphviz 软件,下载地址http://www.graphviz.org/download/
- 下载之后需要配置环境变量,把安装目录如‘C:/Program Files (x86)/Graphviz2.38/bin/’
- 需要安装两个python库
- pip install graphviz
- pip install pydotplus
- 需要安装 Graphviz 软件,下载地址http://www.graphviz.org/download/
import pydotplus
from IPython.display import Image
from six import StringIO
import os
# os.environ["PATH"] += os.pathsep + 'C:/Program Files (x86)/Graphviz2.38/bin/'
with open("dt.dot", "w") as f:
tree.export_graphviz(dtree, out_file=f)
dot_data = StringIO()
tree.export_graphviz(dtree, out_file=dot_data,
feature_names=x.columns,
class_names=['bad_ind'],
filled=True, rounded=True,
special_characters=True)
graph = pydotplus.graph_from_
- 利用结果划分用户
group_1 = fn.loc[(fn.amount_tot<=48077.5)&(fn.sale_amount_cnt>3.5)].copy()
group_1['level'] = 'past_A'
group_2 = fn.loc[(fn.amount_tot>48077.5)&(fn.sale_amount_cnt<=3.5)].copy()
group_2['level'] = 'past_B'
group_3 = fn.loc[fn.amount_tot<=48077.5].copy()
group_3['level'] = 'past_C'
根据决策进行决策,可是保证逾期率比较低
- 如果拒绝past_C类客户,则可以使整体负样本占比下降至0.021
- 如果将past_B也拒绝掉,则可以使整体负样本占比下降至0.012
- 至于实际对past_A、past_B、past_C采取何种策略,要根据利率来做线性规划,从而实现风险定价

















 1万+
1万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









