







1. 简介
1.1 定义
Apache™ Hadoop® 是一个开源的, 可靠的(reliable), 可扩展的(scalable)分布式计算和存储框架
1.2 应用场景
- 搭建大型数据仓库
- PB级数据的存储 处理 分析 统计等业务
起源于谷歌的三篇论文
1.3 核心组件
- Hadoop Common: 协调其它Hadoop组件的通用工具
- Hadoop Distributed File System (HDFS™)
- 多块多副本存储数据
- 数据切分、多副本、容错等操作对用户是透明的
- Hadoop MapReduce
- 分布式计算框架
- 把大的问题分解成若干个小问题,分别解决这些小问题,再合并
- Hadoop YARN资源调度系统
- 负责整个集群资源的管理和调度
1.4 Hadoop优势
高可靠
高扩展性
Hadoop生态系统成熟
2. 分布式文件系统 HDFS
2.1 启动
- 来到$HADOOP_HOME/sbin目录下 执行start-dfs.sh
- 通过jps命令查看当前运行的进程
- 访问192.168.19.137:50070 需要配置虚拟机的ip
2.2 shell操作
851 hadoop fs -ls /
853 hadoop fs -text /README.txt
854 hadoop fs -mv /README.txt /uv
856 hadoop fs -ls /uv
858 hadoop fs -put stop-all.sh /
859 hadoop fs -ls /
860 hadoop fs -rm /stop-all.sh
861 hadoop fs -ls /
862 hadoop fs -mkdir /test
863 mkdir test/abc
864 hadoop fs -mkdir /test1/abc
865 hadoop fs -mkdir -p /test1/abc
866 hadoop fs -get /uv/README.txt /tmp
2.3 设计思路
多块多副本存储
可以保证存储的负载均衡
保证数据安全
2.4 架构
主从结构
主节点进程 NameNode(NN)
从节点进程DataNode(DN)
2.5 环境搭建
下载jdk 和 hadoop
配置环境变量
进入到解压后的hadoop目录 修改配置文件
hdfs namenode格式化 来到hadoop的bin目录
启动hdfs 进入到 sbin
./start-dfs.sh
1 资源管理系统YARN
1 YARN的概念和产生背景
- 通用资源管理系统
- 为上层应用提供统一的资源管理和调度,为集群在利用率、资源统一管理和数据共享等方面带来了巨大好处
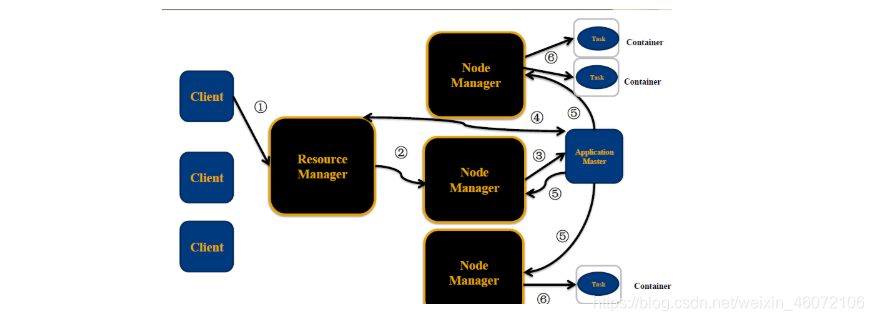
2 YARN的启动
$HADOOP_HOME/sbin/start-yarn.sh
- jps查看进程 ResourceManager NodeManager
- 图形化界面 http://192.168.19.137:8088
2 分布式计算框架MapReduce
1 MapReduce概念 和 MapReduce编程模型
MapReduce分而治之的思想
在hadoop中是编程的框架
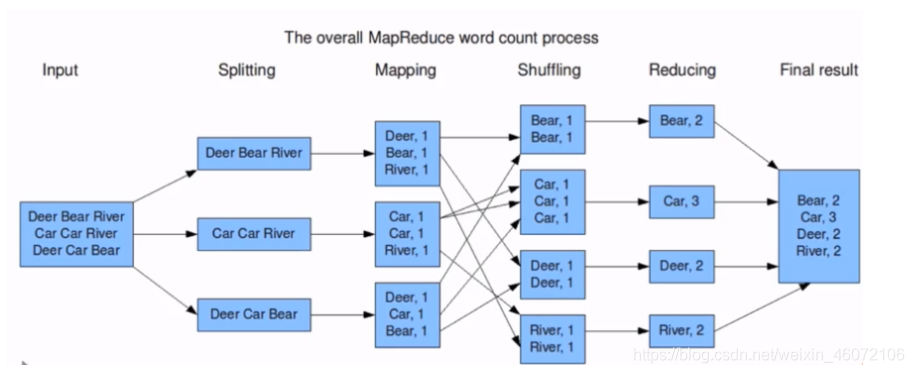
2 应用MRJob编写MapReduce代码
from mrjob.job import MRJob
class MRWordCount(MRJob):
#每一行从line中输入
def mapper(self, _, line):
for word in line.split():
yield word,1
# word相同的 会走到同一个reduce
def reducer(self, word, counts):
yield word, sum(counts)
if __name__ == '__main__':
MRWordCount.run()
python mr_word_count.py README.txt
python mr_word_count.py -r hadoop hdfs:///README.txt -o hdfs:///output2
3 Hadoop生态系统
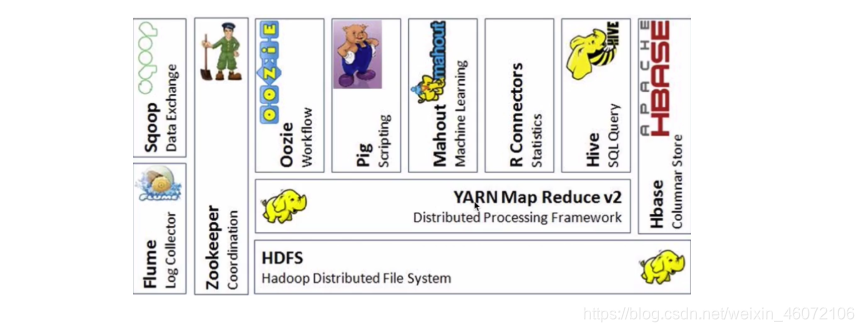
Hadoop发行版的选择
CDH: Cloudera Distributed Hadoop 使用相同的cdh版本不会有兼容性问题














 4736
4736











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









