









1. 简介
1.1 定义
- XGBoost的全称是
eXtreme Gradient Boosting
1.2 原理
- 原理与GBDT相同
1.3 特点
- 是经过优化的分布式梯度提升库,旨在高效、灵活且可移植
- XGBoost是大规模并行boosting tree的工具,比GBDT更高效
1.4 XGBoost与GDBT的区别
1. 泰勒展开级数不同
- XGBoost是拟合上一轮损失函数的二阶导展开,也就是二级泰勒展开式
- GDBT是拟合上一轮损失函数的一阶导展开,也就是一级泰勒展开式
- 因此,XGBoost的准确性更高,且满足相同的训练效果,需要的迭代次数更少。
2. 树的复杂度
- XGBoost生成CART树考虑了树的复杂度
- GDBT未考虑,GDBT在树的剪枝步骤中考虑了树的复杂度。
3. 多线程
- XGBoost与GDBT都是逐次迭代来提高模型性能
- 但是XGBoost在选取最佳切分点时可以开启多线程进行,大大提高了运行速度。
2. 应用
2.1 数据说明
- 皮马印第安人糖尿病数据集(预测是否会得糖尿病) :
- Pregnancies:怀孕次数
- Glucose:葡萄糖
- BloodPressure:血压 (mm Hg)
- SkinThickness:皮层厚度 (mm)
- Insulin:胰岛素 2小时血清胰岛素(mu U / ml )
- BMI:体重指数 (体重/身高)^2
- DiabetesPedigreeFunction:糖尿病谱系功能
- Age:年龄 (岁)
- Outcome:目标值 (0或1)
#加载数据
import pandas as pd
data = pd.read_csv('Pima-Indians-Diabetes.csv')
data.head()

2.2 使用Xgboost 的 Sklearn接口
1. xgboost参数
n_estimators:梯度提升树的棵数,也就是拟合几次残差learning rate:一般情况下,学习速率的值为0.1。但是,对于不同的问题,理想的学习速率有时候会在0.05到0.3之间波动。- 正则化参数
reg_alphaL1正则化系数reg_lambdaL2正则化系数
max_depth [default=6]- 用于设置树的最大深度
range: [1,∞]
subsample [default=1]- 表示观测的子样本的比率,将其设置为0.5意味着xgboost将随机抽取一半观测用于数的生长,这将有助于防止过拟合现象
range: (0,1]
min_child_weight [default=1]- 表示子树观测权重之和的最小值,如果树的生长时的某一步所生成的叶子结点,其观测权重之和小于min_child_weight,那
么可以放弃该步生长,在线性回归模式中,这仅仅与每个结点所需的最小观测数相对应。该值越大,算法越保守 range: [0,∞]
- 表示子树观测权重之和的最小值,如果树的生长时的某一步所生成的叶子结点,其观测权重之和小于min_child_weight,那
colsample_bytree [default=1]- 表示用于构造每棵树时变量的子样本比率
range: (0,1]
import warnings
warnings.filterwarnings("ignore")
import numpy as np
import pandas as pd
import pickle
import xgboost as xgb
from sklearn.model_selection
import train_test_split
from sklearn.externals import joblib
# 用pandas读入数据
data = pd.read_csv('Pima-Indians-Diabetes.csv')
# 做数据切分
train, test = train_test_split(data)
# 取出特征X和目标y的部分
feature_columns = ['Pregnancies', 'Glucose', 'BloodPressure', 'SkinThickness', 'Insulin', 'BMI', 'DiabetesPedigreeFunction', 'Age']
target_column = 'Outcome'
train_X = train[feature_columns].values
train_y = train[target_column].values
test_X = test[feature_columns].values
test_y = test[target_column].values
# 初始化模型
xgb_classifier = xgb.XGBClassifier(n_estimators=20,\ max_depth=4, \ learning_rate=0.1, \ subsample=0.7, \ colsample_bytree=0.7)
# 拟合模型
xgb_classifier.fit(train_X, train_y)
# 使用模型预测
preds = xgb_classifier.predict(test_X)
# 判断准确率
print ('错误类为%f' %((preds!=test_y).sum()/float(test_y.shape[0])))
# 模型存储
joblib.dump(xgb_classifier, '2.model')
# 错误类为0.229167
结果显示:
['0002.model']
early-stopping 早停:在训练集上学习模型,一颗一颗树添加,在验证集上看效果,当验证集效果不再提升,停止树的添加与生长
import xgboost as xgb
from sklearn.model_selection import train_test_split
from sklearn import datasets
digits = datasets.load_digits(n_class=2)
X = digits['data']
y = digits['target']
X_train, X_test, y_train, y_test = train_test_split(X, y, random_state=0)
clf = xgb.XGBClassifier()
clf.fit(X_train, y_train, early_stopping_rounds=10, eval_metric="auc", eval_set=[(X_test, y_test)])
显示结果:
[0] validation_0-auc:0.99950
Will train until validation_0-auc hasn’t improved in 10 rounds.
[1] validation_0-auc:0.99975
[2] validation_0-auc:0.99975
[3] validation_0-auc:0.99975
[4] validation_0-auc:0.99975
[5] validation_0-auc:0.99975
[6] validation_0-auc:1.00000
[7] validation_0-auc:1.00000
[8] validation_0-auc:1.00000
[9] validation_0-auc:1.00000
[10] validation_0-auc:1.00000
[11] validation_0-auc:1.00000
[12] validation_0-auc:1.00000
[13] validation_0-auc:1.00000
[14] validation_0-auc:1.00000
[15] validation_0-auc:1.00000
[16] validation_0-auc:1.00000
Stopping. Best iteration:
[6] validation_0-auc:1.00000
XGBClassifier(base_score=0.5, booster='gbtree', colsample_bylevel=1, colsample_bynode=1,
colsample_bytree=1, gamma=0, learning_rate=0.1,
max_delta_step=0, max_depth=3, min_child_weight=1, missing=None,
n_estimators=100, n_jobs=1, nthread=None,
objective='binary:logistic', random_state=0,
reg_alpha=0,
reg_lambda=1, scale_pos_weight=1, seed=None, silent=None,
subsample=1, verbosity=1)
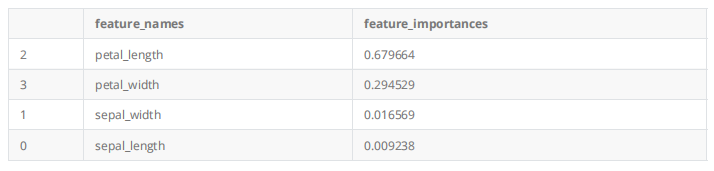
4. 使用Xgboost输出特征重要程度
import xgboost as xgb
from sklearn.model_selection import train_test_split
from sklearn import datasets
iris = datasets.load_iris()
y = iris['target']
X = iris['data']
xgb_model = xgb.XGBClassifier().fit(X,y)
temp = pd.DataFrame()
temp['feature_names'] = ['sepal_length', 'sepal_width', 'petal_length', 'petal_width']
temp['feature_importances'] = xgb_model.feature_importances_
temp = temp.sort_values('feature_importances',ascending = False)
temp
输出结果:
temp.set_index('feature_names').plot.bar(figsize=(16,8),rot=0)
显示结果:
<matplotlib.axes._subplots.AxesSubplot at 0x1a308a3150>

- 不同算法解决不同的问题,但是首先需要确定的是问题本身(分类还是回归)
















 4万+
4万+











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









