







追风赶月莫停留,平芜尽处是春山。
好久没更新了,今天来更新一波。
今天继续使用新版微博
一、网页分析
依旧是女神迪丽热巴😍
找到热巴的主页,依旧先打开开发者模式,然后刷新网页。
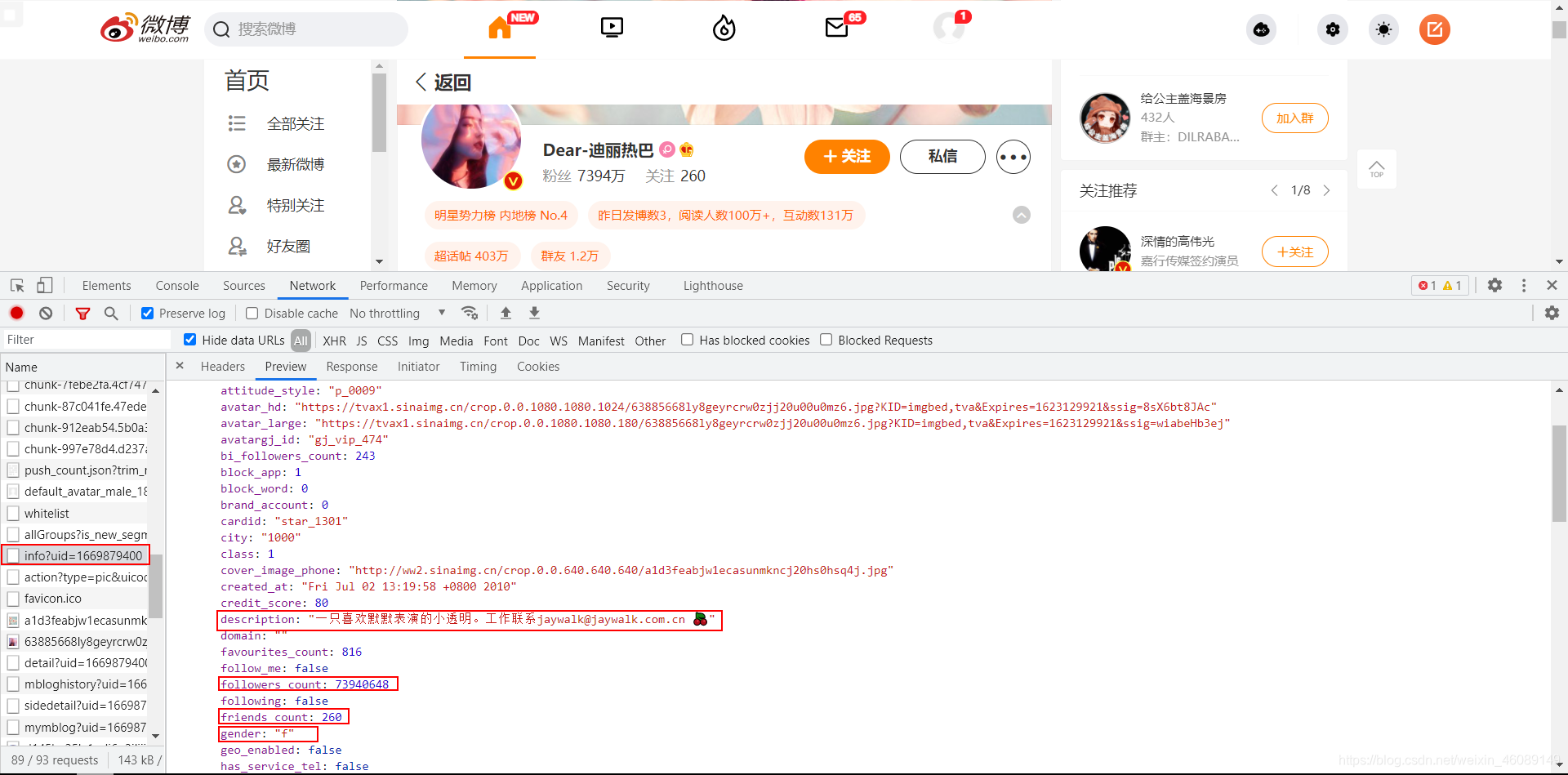
在这个请求中你可以得到:昵称、关注数、粉丝数、博文数、个人简介、性别、是否通过微博认证、认证信息、地区、微博等级、会员等级等等。
另外一个请求:
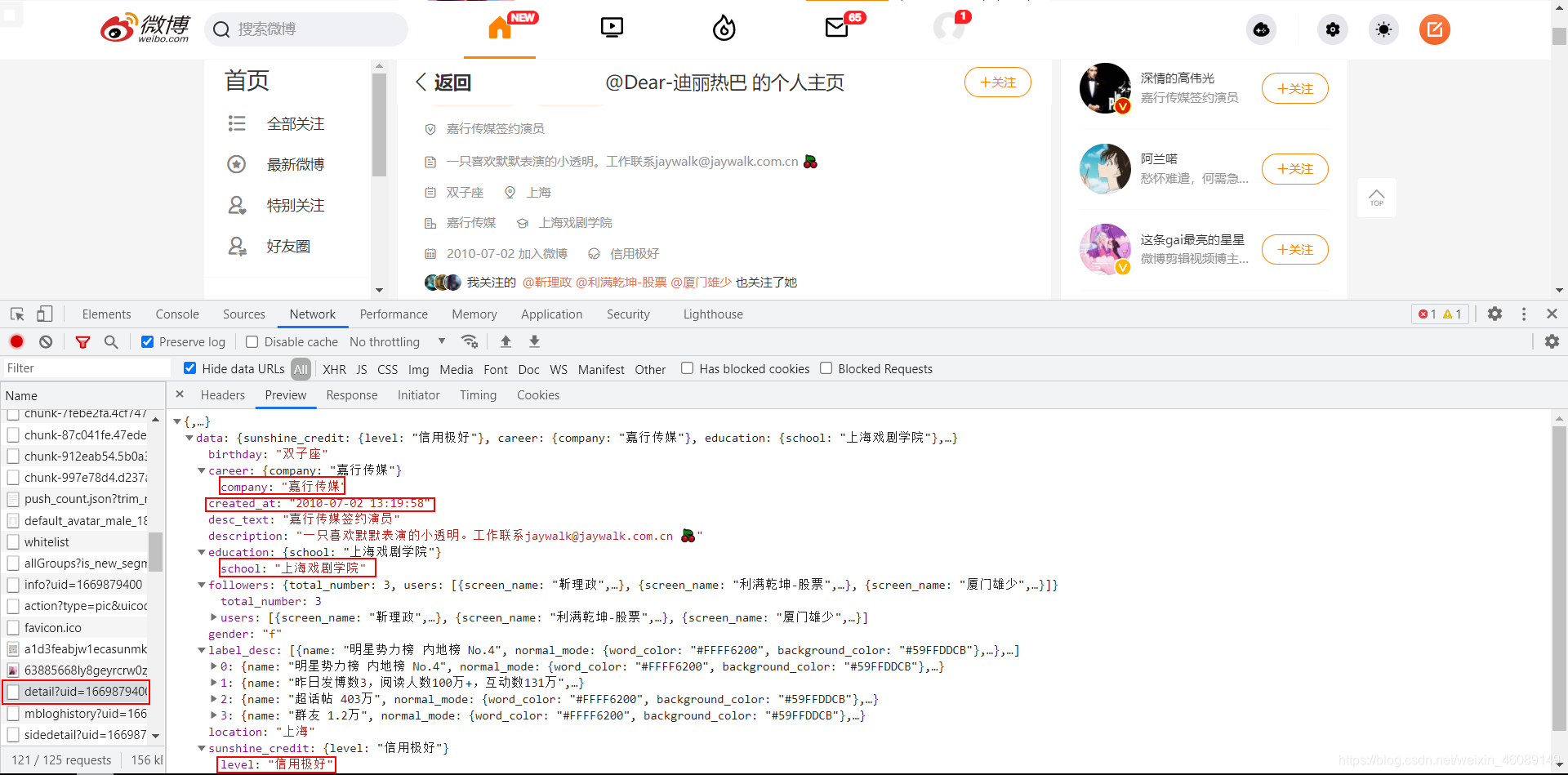
可以得到:生日、公司、学校、加入微博的时间、阳光信用等等。
二、接口分析
url分析
https://weibo.com/ajax/profile/info?uid=1669879400
很显然只有uid这一个参数,对应的是博主的id
https://weibo.com/ajax/profile/detail?uid=1669879400
同上
所以我们只要知道了博主的uid就可以获得他的相关信息了。
返回数据分析
两个接口大同小异,都是get请求,返回数据格式都是json格式
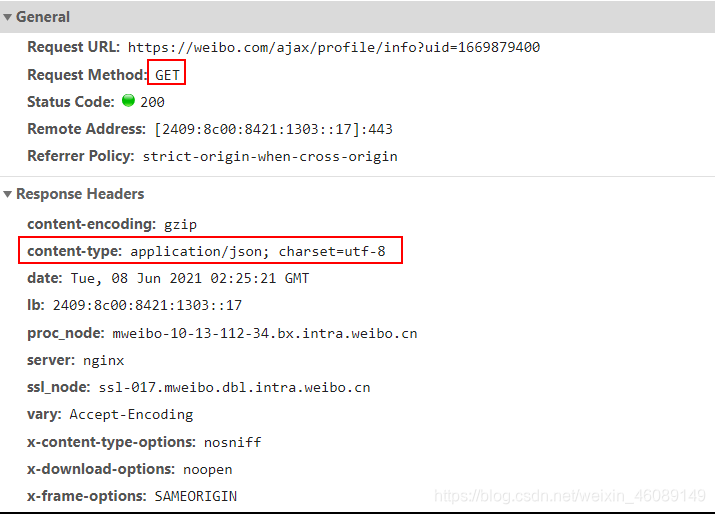
三、编写代码
知道了url规则,以及返回数据的格式,那现在咱们的任务就是构造url然后请求数据
uid = ['1669879400']
for id in uid:
url1 = "https://weibo.com/ajax/profile/info?uid={}".format(id)
url2 = "https://weibo.com/ajax/profile/detail?uid={}".format(id)
只要在uid这个列表里添加用户id,这样就可以实现多个用户信息的抓取了。
对于每个url我们都要去用requests库中的get方法去请求数据:
所以我们为了方便就把请求网页的代码写成了函数get_html(url),传入的参数是url返回的是请求到的内容。
def get_html(url):
headers = {
"User-Agent": "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/89.0.4389.82 Safari/537.36",
"Referer": "https://weibo.com"
}
cookies = {
"cookie": "你的cookie"
}
response = requests.get(url, headers=headers, cookies=cookies)
time.sleep(3) # 加上3s 的延时防止被反爬
return response.text
注意这里一定要把你的cookie替换掉,不然请求不到内容。
cookies获取方式
获取数据
我把它封装成了一个函数,传入uid。
def get_data(id):
url1 = "https://weibo.com/ajax/profile/info?uid={}".format(id)
url2 = "https://weibo.com/ajax/profile/detail?uid={}".format(id)
html1 = get_html(url1)
html2 = get_html(url2)
responses1 = json.loads(html1)
data1 = responses1['data']['user']
responses2 = json.loads(html2)
data2 = responses2['data']
data = {} # 新建个字典用来存数据
data['name'] = data1['name'] # 名字
data['description'] = data1['description'] # 个人简介
data['followers_count'] = data1['followers_count'] # 粉丝数量
data['friends_count'] = data1['friends_count'] # 关注数量
data['statuses_count'] = data1['statuses_count'] # 博文数量
data['location'] = data1['location'] # 所在地区
data['gender'] = data1['gender'] # 性别:f:女, m:男
data['verified'] = data1['verified'] # 是否认证
data['verified_reason'] = data1['verified_reason'] # 认证信息
try:
data['birthday'] = data2['birthday'] # 生日
except KeyError:
data['birthday'] = ""
try:
data['created_at'] = data2['created_at'] # 注册时间
except KeyError:
data['created_at'] = ""
try:
data['sunshine_credit'] = data2['sunshine_credit']['level'] # 阳光信用
except KeyError:
data['sunshine_credit'] = ""
try:
data['company'] = data2['career']['company'] # 公司
except KeyError:
data['company'] = ""
try:
data['school'] = data2['education']['school'] # 学校
except KeyError:
data['school'] = ""
注意:这里第二个接口之所以写try-except的原因是因为可能博主设置了权限,看不到他的一些相关信息。
保存数据
封装一个函数:
def save_data(data):
title = ['name', 'description', 'followers_count', 'friends_count', 'statuses_count', 'location', 'gender', 'verified', 'verified_reason', 'birthday', 'created_at', 'sunshine_credit', 'company', 'school']
with open("data.csv", "a", encoding="utf-8", newline="")as fi:
fi = csv.writer(fi)
fi.writerow([data[k] for k in title])
完整代码
# -*- coding:utf-8 -*-
# @time: 2021/6/8 10:00
# @Author: 韩国麦当劳
# @Environment: Python 3.7
import json
import requests
import csv
import time
def get_html(url):
headers = {
"User-Agent": "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/89.0.4389.82 Safari/537.36",
"Referer": "https://weibo.com"
}
cookies = {
"cookie": "你的cookie"
}
response = requests.get(url, headers=headers, cookies=cookies)
time.sleep(3) # 加上3s 的延时防止被反爬
return response.text
def save_data(data):
title = ['name', 'description', 'followers_count', 'friends_count', 'statuses_count', 'location', 'gender', 'verified', 'verified_reason', 'birthday', 'created_at', 'sunshine_credit', 'company', 'school']
with open("data.csv", "a", encoding="utf-8", newline="")as fi:
fi = csv.writer(fi)
fi.writerow([data[k] for k in title])
def get_data(id):
url1 = "https://weibo.com/ajax/profile/info?uid={}".format(id)
url2 = "https://weibo.com/ajax/profile/detail?uid={}".format(id)
html1 = get_html(url1)
html2 = get_html(url2)
responses1 = json.loads(html1)
data1 = responses1['data']['user']
responses2 = json.loads(html2)
data2 = responses2['data']
data = {} # 新建个字典用来存数据
data['name'] = data1['name'] # 名字
data['description'] = data1['description'] # 个人简介
data['followers_count'] = data1['followers_count'] # 粉丝数量
data['friends_count'] = data1['friends_count'] # 关注数量
data['statuses_count'] = data1['statuses_count'] # 博文数量
data['location'] = data1['location'] # 所在地区
data['gender'] = data1['gender'] # 性别:f:女, m:男
data['verified'] = data1['verified'] # 是否认证
data['verified_reason'] = data1['verified_reason'] # 认证信息
try:
data['birthday'] = data2['birthday'] # 生日
except KeyError:
data['birthday'] = ""
try:
data['created_at'] = data2['created_at'] # 注册时间
except KeyError:
data['created_at'] = ""
try:
data['sunshine_credit'] = data2['sunshine_credit']['level'] # 阳光信用
except KeyError:
data['sunshine_credit'] = ""
try:
data['company'] = data2['career']['company'] # 公司
except KeyError:
data['company'] = ""
try:
data['school'] = data2['education']['school'] # 学校
except KeyError:
data['school'] = ""
save_data(data)
if __name__ == '__main__':
uid = ['1669879400']
for id in uid:
get_data(id)
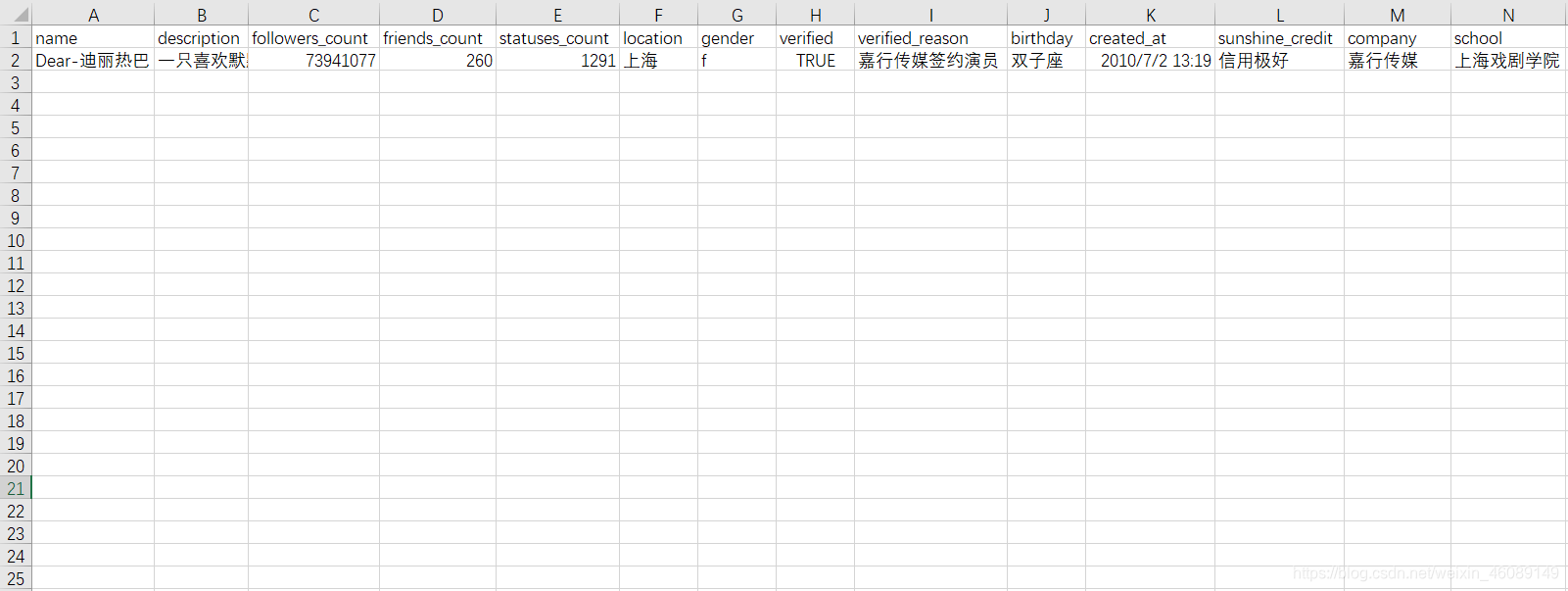
获得的部分数据截图
欢迎一键三连哦!
还想看哪个网站的爬虫?欢迎留言,说不定下次要分析的就是你想要看的!


















 1565
1565

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











