









目录
简介
哈喽各位技术专家,这次我来分享整理一下我知道的内容,主要是缓存一致性协议和CPU缓存架构
CPU高速缓存
先说一下CPU高速缓存吧,CPU高速缓冲存储器,是位于CPU和主内存中间一块容量很小,但效率很高的存储器,由于CPU的速度远高于主内存,所以如果CPU从主内存取数据的话,需要等待一定的时间周期,所以,可以在缓冲存储器中,保存一部分CPU刚使用过或者循环使用的数据,当CPU需要用的时候,直接从缓存取用,减少CPU的等待时间,提高系统效率
给大家看一下不同的空间CPU的取用速度
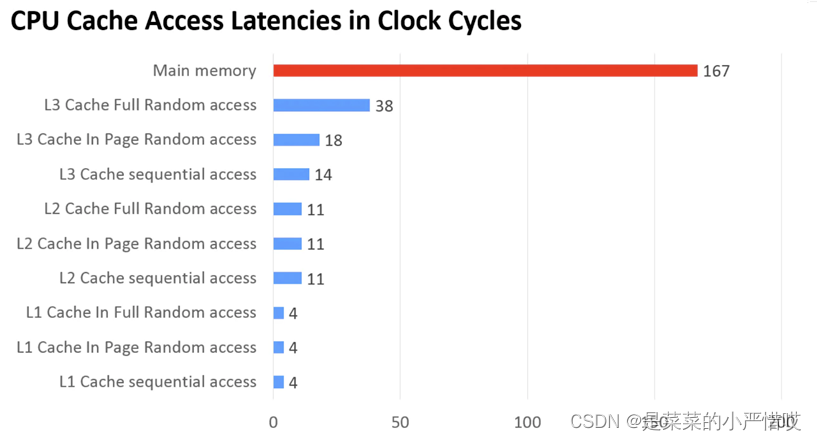
可以看到,主内存的耗时比缓存的耗时大得多得多
现在CPU为了提高效率,减少CPU和内存的交互,一般都在CPU上集成了多级缓存,常见的就是三级
比如上面的耗时对比图,下面的L1、L2、L3就是不同级别的缓存,现在大部分机器都有三级缓存,不过也有部分机器是二级缓存,第三级缓存,可以用在多核共享,当然,可以看到,L1速度最快,L3速度最慢,不过相应的,L1容量最小,L3容量最大
大家可以看看自己电脑的配置,是什么样的,这是我的那台windows电脑(怪我土狗,不知道mac怎么看)
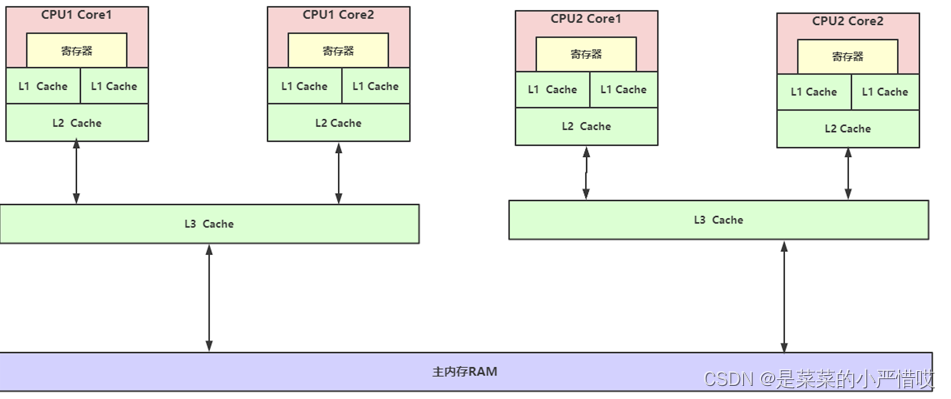
给大家画一张图,以图来看缓存的分布
为什么要有CPU高速缓存
有两个目的,所以要有CPU高速缓存
1、提高效率,这个我们上面已经说了
2、局部性原理
局部性原理
局部性原理有两个,一个,是时间局部性原理,一个,是空间局部性原理
时间局部性原理:如果一个信息项正在被访问,那么在近期它很可能还会被再次访问
空间局部性原理:如果一个存储器的位置被引用,那么将来它附近的位置也会被引用
缓存一致性
在计算机体系结构中,缓存一致性是共享资源数据的一致性,这些数据最后会存储在多个本地缓存中,当系统维护公共内存资源的缓存时,就可能出现数据不一致的情况,尤其是多处理器共享内存的系统
在共享内存多处理器系统中,每个处理器都有一个单独的缓存内存,共享数据可能有多个副本:一个副本在主内存中,一个副本在请求它的每个处理器的本地缓存中
当数据的一个副本发生更改时,其他副本必须反映该更改,缓存一致性是确保共享操作数据的变化能够及时地在整个系统中传播的规程
比如说,CPU两个核心,A核心和B核心,都用了 age=10 这个数据,A核心在自己的高速缓存中,对 age 进行了加一,如果没有将这个变更同步给B核心,那么B核心用 age 减二,得出的结果就是8,而不是9
所以问题的根本在于,缓存不一致,只要解决了缓存不一致的问题,就ok
缓存一致性的要求
缓存一致性有自己的要求
写传播,即,对任何缓存中数据的更改,都必须传播到对等缓存中的其他副本,也就是该缓存的副本
事务串行化,即,对单个内存未知的读写,必须被所有处理器以相同的顺序所看到确保一致性最常用的机制有两种,窥探机制和基于目录的机制;两种机制各有优缺点
如果,有足够的带宽可以用,那么基于协议的窥探机制往往更快,因为所有事务都是所有处理器看到的请求和响应,但缺点是,窥探是不可扩展的,每个请求都必须广播到系统的每一个节点,这意味着系统越大,逻辑或物理总线的大小和带宽也必须增加
而基于目录的机制,有更长的延时,因为有3跳,请求、转发、响应,但是用的带宽更少,毕竟消息是点对点的,不是广播的,许多大于64核的系统就用的基于目录的机制
总线窥探
总线窥探是缓存中的一致性控制器监视或者窥探总线事务的一种方案,目标是在分布式共享内存系统中,维护缓存一致性
工作原理
当特定数据被多个处理器共享时,处理器如果修改了共享数据的值,更改必须传播到所有其他啊具有共享数据副本的缓存中,这种传播行为,可以避免系统违反缓存一致性
数据变更的通知,可以通过总线窥探来完成,所有的窥探者都在监视总线上的每一个事务,如果一个修改共享缓存块的事务出现在总线上,所有的窥探者都会检查他们的缓存是否有共享块的相同副本,如果缓存中有共享块的副本,则相应的窥探者执行一个动作以确保缓存一致性
而这个动作,可以是刷新缓存,也可以是使得自己的缓存失效,这块还涉及到了缓存状态的改变,所以具体如何,得看对应的缓存一致性协议
窥探协议
根据管理写操作的本地副本的方式,可以分为两种窥探协议
Write-invalidate:写-失效协议,当处理器写入一个共享缓存块时,其他缓存中的所有共享副本都会通过总线窥探失效,这种方法确保处理器只能读写一个数据的一个副本,其他缓存中的其他副本都无效,这是最常用的窥探协议,MSI、MESI、MOSI、MOESI和MESIF协议属于该类型
Write-update:写-更新协议,当处理器写入一个共享缓存块时,其他缓存的所有共享副本都会通过总线窥探更新,这个方法将写数据广播到总线上的所有缓存中,它比write-invalidate协议引起更大的总线流量,这也是为什么这种方法不怎么常见
一致性协议
上面,提到了一致性协议,一致性协议在多处理器系统中,应用于高速缓存的一致性,目前设计出了很多种模型和协议,如MSI、MESI(又名Illinois)、MOSI、MOESI、MERSI、MESIF、write-once、Synapse、Berkeley、Firefly和Dragon协议,最常用的,就是MESI协议
MESI协议
MESI协议,是基于写-失效的一种缓存一致性协议,是支持回写缓存的最常用协议,与写通过(穿透)缓存相比,回写缓存能节约很大的带宽,总是有“脏”状态表示缓存中的数据与主内存中的数据不同,MESI协议要求在缓存不命中,且数据块在另一个缓存中时,允许缓存到缓存之间的直接复制,与MSI协议相比,MESI协议减少了主内存的事务数量,极大改善了性能
这其中,提到了回写和写通过(穿透),它们分别是什么呢?
其实就是指的CPU在向缓存写入数据时的操作
回写:CPU在更新缓存时,只是把更新的缓存区进行标记,并不会同步更新主内存,只不过在缓存区要被新进入的数据取代的时候,才会更新主内存
写通过(穿透):CPU在更新缓存时,除了向缓存写入,还会向主内存也写入,保持缓存和主内存的数据一致就像你买东西,写通过(穿透),就相当于你自己去买,买完了就实实在在在你手里;回写,就相当于你让别人帮你买,你把钱给他,他说我给你买到了,但是实际上并没有
这两种方法各有利弊,回写的优点是CPU执行效率高,但实现起来技术会比较复杂,写通过(穿透)的优点是简单,但缺点是每次都要访问主内存,速度比较慢
说到这儿,还有一个很重要的地方,上面我们说了MESI协议比MSI协议好,从表面就可以看出来,多了一个E,那这M、E、S、I分别是什么呢?
其实,这四个字母代表着缓存行的四种不同状态
已修改Modified (M)
缓存行是脏的(dirty),与主存的值不同。如果别的CPU内核要读主存这块数据,该缓存行必须回写到主存,状态变为共享(S).
独占Exclusive (E)
缓存行只在当前缓存中,但是干净的--缓存数据同于主存数据。当别的缓存读取它时,状态变为共享;当前写数据时,变为已修改状态。
共享Shared (S)
缓存行也存在于其它缓存中且是未修改的。缓存行可以在任意时刻抛弃。
无效Invalid (I)
缓存行是无效的任意的一对缓存,对应的缓存行关系为
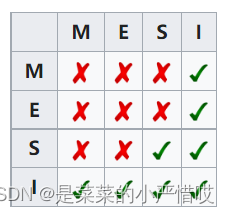
举个栗子~ 哒哒哒
哥!我错了,你把你手上的凳子放下,我好好说话

假设CPU两个核,core1把变量通过总线加载到自己的缓存中,此时缓存为E-独占状态,当core2再加载同样变量,由于总线窥探,缓存变为S-共享状态
当core1修改了变量值,core2的缓存就会进入I-无效状态,core2如果要使用,就只能从主存加载,但我们不能一直等待core1把变量刷回主存,所以缓存一致性协议就该干活了,要让修改立刻刷新回主存
当core1回写,因为窥探,core1的缓存变为E-独占状态,当core2加载,core1和core2的缓存状态都变为S-共享状态
注意!!!
当core1和core2同时进行了变量修改,只要他们两个其中任何一个执行了回写,另一个的回写就失效
比如用volatile修饰一个 int 的变量,多线程执行了 ++ 操作,volatile不能保证原子性,因为它不能保证不同线程的执行结果是否都能有效
当然,也有两种情况下无法保证缓存一致性
1、跨缓存行
2、早期的处理器,根本没有实现缓存一致性协议(当然,早期的处理器虽然没有实现缓存一致性协议,但它们可以使用总线锁定来保证缓存一致性)
总线事务
在上面,我们很多地方都提到了总线事务,所以,这究竟是个什么玩意,我们必须搞明白
总线事务,在计算机中,数据通过总线在处理器和内存之间传递,每次处理器和内存之间的数据传递都是通过一系列的步骤来完成的,这一系列的步骤,就称为总线事务,实在不行,你类比一下DB的事务
总线事务包括了读事务和写事务,读事务从内存传递数据到处理器,写事务从处理器传递数据到内存,每个事务会读或写内存中一个或多个物理上连续的字
总线会同步试图并发使用总线的事务,在一个处理器执行总线事务期间,总线会禁止其他处理器和IO设备执行内存的读或写
总线仲裁
总线仲裁,听名字,仲裁,决定者,总线仲裁和总线事务是有关的
假设A和B是两个处理器,他们同时向总线发起总线事务,这个时候,总线仲裁会对竞争做出裁决,总线仲裁会确保所有处理器都能够公平访问内存,如果仲裁后判定了一个处理器获胜,那么别的处理器都要等待获胜的这个处理器执行完它的总线事务才能再次访问内存,而这个处理器执行总线事务期间,如果再有别的处理器请求总线事务,都会被禁止掉
总线这种工作机制可以把所有处理器对内存的访问串行化来执行,并且,在任意的时间点,之多只有一个处理器可以访问内存,这个特性确保了单个总线事务之中的内存读写操作具有原子性
但!注意!!!
但是不一定是可靠的,在跨总线的时候,是不行的,比如 long 类型,64位,在32位机器的处理中,分为高32位和低32位两步处理,两个请求
所以,这种情况下为了保证原子性,可以采用缓存锁定和总线锁定的办法
总线锁定
什么是总线锁定呢?
总线锁定,就是使用处理器提供的 LOCK# 信号(总线锁定信号),当一个处理器在总线上输出此信号,其他处理器的请求将被阻塞,该处理器可以独享内存
LOCK前缀指令 + LOCK#信号 串行化
缓存锁定
什么是缓存锁定呢?
由于总线锁定阻止了被阻塞处理器和所有内存之间的通信,而输出LOCK#信号的CPU可能只需要锁住特定的一块内存区域,因此总线锁定开销较大
缓存锁定,是指内存区域如果被缓存在处理器的缓存行中,并且在 LOCK 操作期间被锁定,那么当它执行锁操作回写到内存时,处理器不会在总线上输出 LOCK# 信号(总线锁定信号),而是修改内部的内存地址,并允许它的缓存一致性机制来保证操作的原子性,因为缓存一致性机制会阻止同时修改由两个以上处理器缓存的内存区域数据,当其他处理器回写已被锁定的缓存行的数据时,会使缓存行无效
当然,缓存锁定也有它不能使用的情况
1、当操作的数据不能被缓存在处理器内部,或操作的数据跨多个缓存行时,处理器会调用总线锁定
2、有写处理器不支持缓存锁定
伪共享问题
加油,这是最后一个地方了,伪共享问题,伪共享问题,其实就是涉及到缓存行的问题
如果多个核的线程在操作同一个缓存行中的不同变量数据,那么就会出现频繁的缓存失效,即使,在代码层面看这两个线程操作的数据之间完全没有关系,这种不合理的资源竞争,就是伪共享
举个例子,long 类型,64位,也就是8个字节,现在缓存行64个字节,也就是说,一个long类型,占不满这一个缓存行,我还有另一个long类型,那这两个long类型就在一个缓存行内了,根据缓存一致性协议,如果这两个long类型,分别一直更新,那这个缓存就不断失效
这块我们上个简单的代码演示一下
static class UserInfo {
long adminAge = 0;
long rootAge = 0;
}这是一个简单的属性类
现在,我们开两个线程,对他们分别进行递增,我们来看耗时
public static void main(String[] args) throws InterruptedException {
UserInfo userInfo = new UserInfo();
long beginTime = System.currentTimeMillis();
CountDownLatch countDownLatch = new CountDownLatch(2);
Thread t1 = new Thread(() -> {
for (int i = 0; i < 1000000000; i++) {
userInfo.adminAge++;
}
countDownLatch.countDown();
});
Thread t2 = new Thread(() -> {
for (int i = 0; i < 1000000000; i++) {
userInfo.rootAge++;
}
countDownLatch.countDown();
});
t1.start();
t2.start();
countDownLatch.await();
System.out.println(System.currentTimeMillis() - beginTime);
}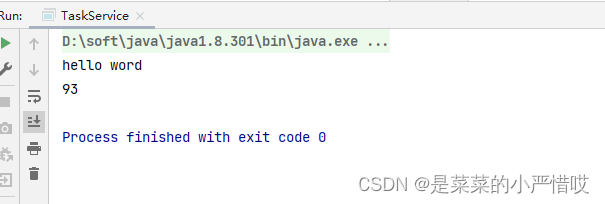
看,93,是不是很快
好,我们对这两个 long 属性,加上 volatile 修饰,根据我上一篇文章讲的,volatile 将保证可见性,插入load屏障,会触发缓存一致性协议,那缓存失效了,就得重新加载
注意,这块本身不存在线程安全问题,毕竟自己线程操作自己的变量,我们加volatile就只是为了说明伪共享的问题
static class UserInfo {
volatile long adminAge = 0;
volatile long rootAge = 0;
}我们再来看一下执行耗时 (说实话,我的电脑风扇转的挺快)
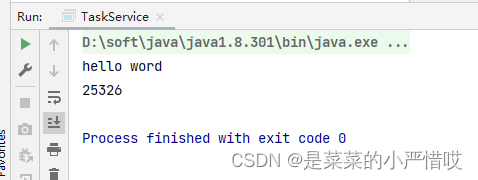
来,看这个时间差
所以,我们有没有办法避免这个问题呢?
当然有,否则你不得捶我啊
既然是同一个缓存行的问题,那我们不让它同一个缓存行不就行了?
我们试试,填充7个无用的long类型,用来占用缓存行空间
static class UserInfo {
volatile long adminAge = 0;
long l0, l1, l2, l3, l4, l5, l6;
volatile long rootAge = 0;
}我们运行试试
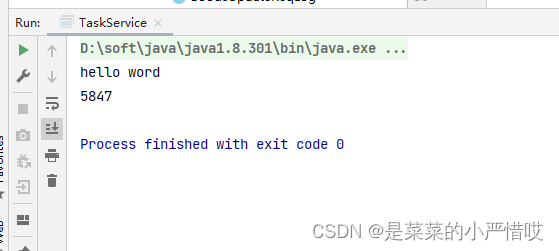
可以看到,有提升,但是不如不加volatile那么快,这是当然的,虽然填充了缓存行,但,volatile还是会触发缓存一致性协议的,所以快,也是相对来说
那,我们在开发中难道都要这么写吗?
no no no,java当然有帮我们想过这个,也提供了方法
那就是 @sun.misc.Contended 注解,不过我们在使用的时候,不止要使用这个注解,还要加一个JVM启动参数 -XX:-RestrictContended
OK~ 本期分享总结到此为止,如果觉得有帮助,可以点个赞哦~ 也是我继续努力的动力,如果觉得哪儿不对,欢迎评论或站内戳我,我很乐意向您学习
















 552
552











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









