






K-means算法简述
1.K-means算法,也称为K-平均或者K-均值,一般作为掌握聚类算法的第一个算法。
2.这里的K为常数,需事先设定,通俗地说该算法是将没有标注的 M 个样本通过迭代的方式聚集成K个簇。
3.在对样本进行聚集的过程往往是以样本之间的距离作为指标来划分。
简单Demo说明
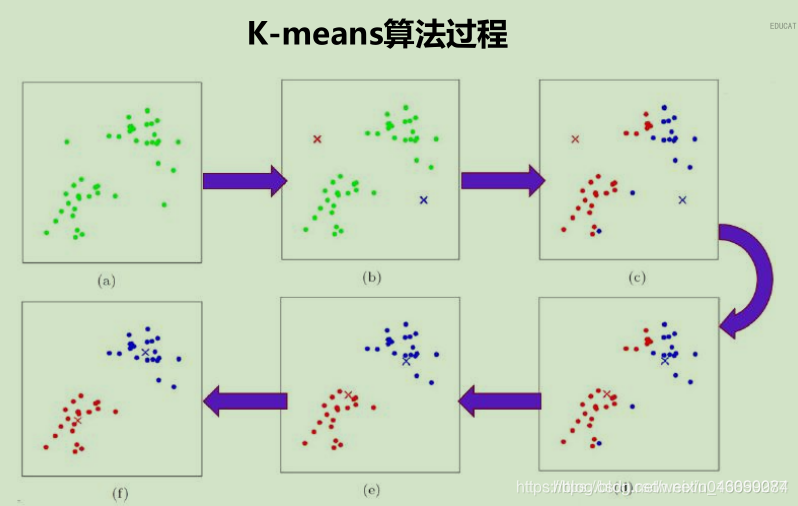
如上图以 K 为2,样本集为M 来描述KMean算法,算法执行步骤如下:
选取K个点做为初始聚集的簇心(也可选择非样本点);
分别计算每个样本点到 K个簇核心的距离(这里的距离一般取欧氏距离或余弦距离),找到离该点最近的簇核心,将它归属到对应的簇;
所有点都归属到簇之后, M个点就分为了 K个簇。之后重新计算每个簇的重心(平均距离中心),将其定为新的“簇核心”;
反复迭代 2 - 3 步骤,直到达到某个中止条件。
注:常用的中止条件有迭代次数、最小平方误差MSE、簇中心点变化率;
由上述Demo可知,对于KMean算法来说有三个比较重要的因素要考虑,分别如下所述;
K-means算法思考
1.K值的选择: k 值对最终结果的影响至关重要,而它却必须要预先给定。给定合适的 k 值,需要先验知识,凭空估计很困难,或者可能导致效果很差。
2.异常点的存在:K-means算法在迭代的过程中使用所有点的均值作为新的质点(中心点),如果簇中存在异常点,将导致均值偏差比较严重。 比如一个簇中有2、4、6、8、100五个数据,那么新的质点为24,显然这个质点离绝大多数点都比较远;在当前情况下,使用中位数6可能比使用均值的想法更好,使用中位数的聚类方式叫做K-Mediods聚类(K中值聚类)。
3.初值敏感:K-means算法是初值敏感的,选择不同的初始值可能导致不同的簇划分规则。为了避免这种敏感性导致的最终结果异常性,可以采用初始化多套初始节点构造不同的分类规则,然后选择最优的构造规则。针对这点后面因此衍生了:二分K-Means算法、K-Means++算法、K-Means||算法、Canopy算法等。
常用的几种距离计算方法
通常情况下,在聚类算法中,样本的属性主要由其在特征空间中的相对距离来表示。
这就使得距离这个概念,对于聚类非常重要。以下是几种最常见的距离计算方法。
欧式距离(又称 2-norm 距离)
在欧几里德空间中,点 x=(x1,…,xn) 和 y=(y1,…,yn) 之间的欧氏距离为:
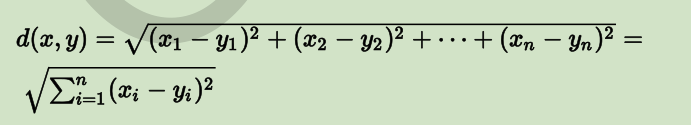
在欧几里德度量下,两点之间线段最短。
余弦距离(又称余弦相似性)
两个向量间的余弦值可以通过使用欧几里德点积公式求出:
a⋅b=∥a∥∥b∥cosθ
所以
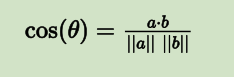
也就是说,给定两个属性向量 A 和 B,其余弦距离(也可以理解为两向量夹角的余弦)由点积和向量长度给出,如下所示:
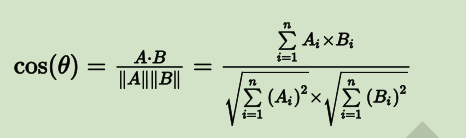
这里的 Ai 和 Bi 分别代表向量 A 和 B 的各分量。
曼哈顿距离(Manhattan Distance, 又称 1-norm 距离)
曼哈顿距离的定义,来自于计算在规划为方型建筑区块的城市(如曼哈顿)中行车的最短路径。
假设一个城市是完备的块状划分,从一点到达另一点必须要按照之间所隔着的区块的边缘走,没有其他捷径(如下图):
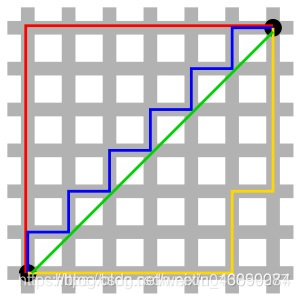
因此,曼哈顿距离就是:在直角坐标系中,两点所形成的线段对 x 和 y 轴投影的长度总和。
从点 (x1,y1) 到点 (x2,y2),曼哈顿距离为:
|x1−x2|+|y1−y2|
KMean 简单编码样例
import matplotlib.pyplot as plt
from sklearn.datasets import make_blobs # 导入产生模拟数据的方法
from sklearn.cluster import KMeans
# 1. 产生模拟数据
k = 5
X, Y = make_blobs(n_samples=1000, n_features=2, centers=k, random_state=1)
# 2. 模型构建
km = KMeans(n_clusters=k, init='k-means++', max_iter=30)
km.fit(X)
# 获取簇心
centroids = km.cluster_centers_
# 获取归集后的样本所属簇对应值
y_kmean = km.predict(X)
# 呈现未归集前的数据
plt.scatter(X[:, 0], X[:, 1], s=50)
plt.yticks(())
plt.show()
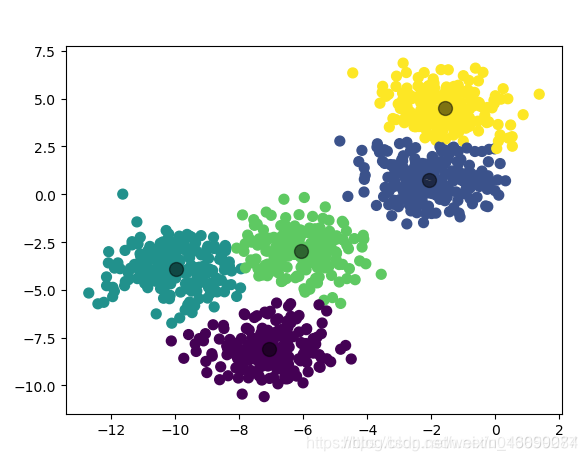
plt.scatter(X[:, 0], X[:, 1], c=y_kmean, s=50, cmap='viridis')
plt.scatter(centroids[:, 0], centroids[:, 1], c='black', s=100, alpha=0.5)
plt.show()

归集后的数据图:
KMeans类的主要参数有:
1.n_clusters: 即k值,一般需要多试一些值以获得较好的聚类效果。k值好坏的评估标准在下面会讲。
2.max_iter: 最大的迭代次数,一般如果是凸数据集的话可以不管这个值,如果数据集不是凸的,可能很难收敛,此时可以指定最大的迭代次数让算法可以及时退出循环。
3.n_init:用不同的初始化质心运行算法的次数。由于K-Means是结果受初始值影响的局部最优的迭代算法,因此需要多跑几次以选择一个较好的聚类效果,默认是10,一般不需要改。如果你的k值较大,则可以适当增大这个值。
4.init: 即初始值选择的方式,可以为完全随机选择’random’,优化过的’k-means++’或者自己指定初始化的k个质心。一般建议使用默认的’k-means++’。
5.algorithm:有“auto”, “full” or “elkan”三种选择。”full”就是我们传统的K-Means算法, “elkan”是elkan K-Means算法。默认的”auto”则会根据数据值是否是稀疏的,来决定如何选择”full”和“elkan”。一般数据是稠密的,那么就是 “elkan”,否则就是”full”。一般来说建议直接用默认的”auto”
6.random_state:表示产生随机数的方法。默认情况下的缺省值为None,此时的随机数产生器是np.random所使用的RandomState实例。


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









