






 本文介绍了InnoDB数据库如何使用数据页和页目录来提高查询速度,通过页作为基本交互单位,以及页目录的分组规则,减少IO操作,优化数据查找流程,从而提升查询性能。
本文介绍了InnoDB数据库如何使用数据页和页目录来提高查询速度,通过页作为基本交互单位,以及页目录的分组规则,减少IO操作,优化数据查找流程,从而提升查询性能。
介绍Page页之前我们先来说一下页主要用来干什么?
每当我们进行一次查询的时候,实际上就是一次IO的过程,因为数据库数据是存储在磁盘当中,所以我们在进行大量查询的时候,因为IO次数太多,所以速度会超级慢,所以Page就出现了。但是Page(页)为什么会增加查询速度呢?比如我们要查询ID=1的数据时,数据库会返给内存一个Page,这个Page中就包含了ID=1的数据,当然它不可能只包含ID=1的数据,假设它包含了ID为1至110的数据,当我们想查询ID=20的数据时,就不会进入到数据库中去查询,而是去到内存当中的Page中去查询,这样查询的速度就会快了。
一、InnoDB数据页极其结构
为了避免一条条的去数据库磁盘中去读取数据,InnoDB采用页的方式,作为磁盘和内存交互的基本单位,一般一个页的大小为16Kb。
InnoDB为了不同的目的而设计了许多不同类型的页。比如:存放表空间头部信息的页、存放undo日志信息的页等等,我们把存放表中数据的页,成为索引页或者数据页。
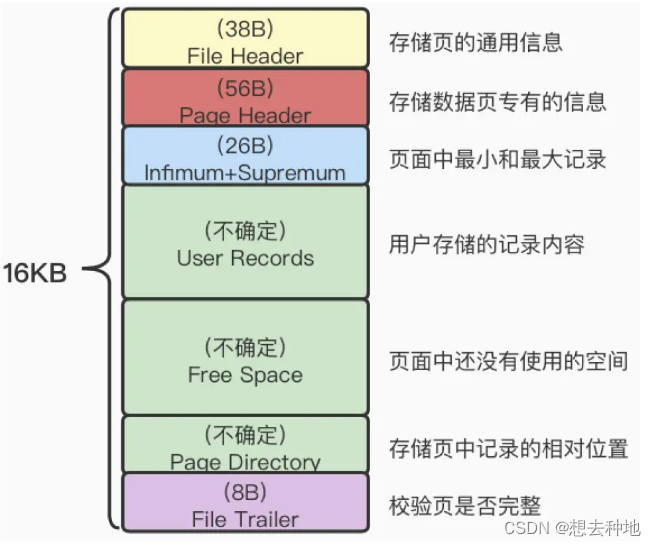
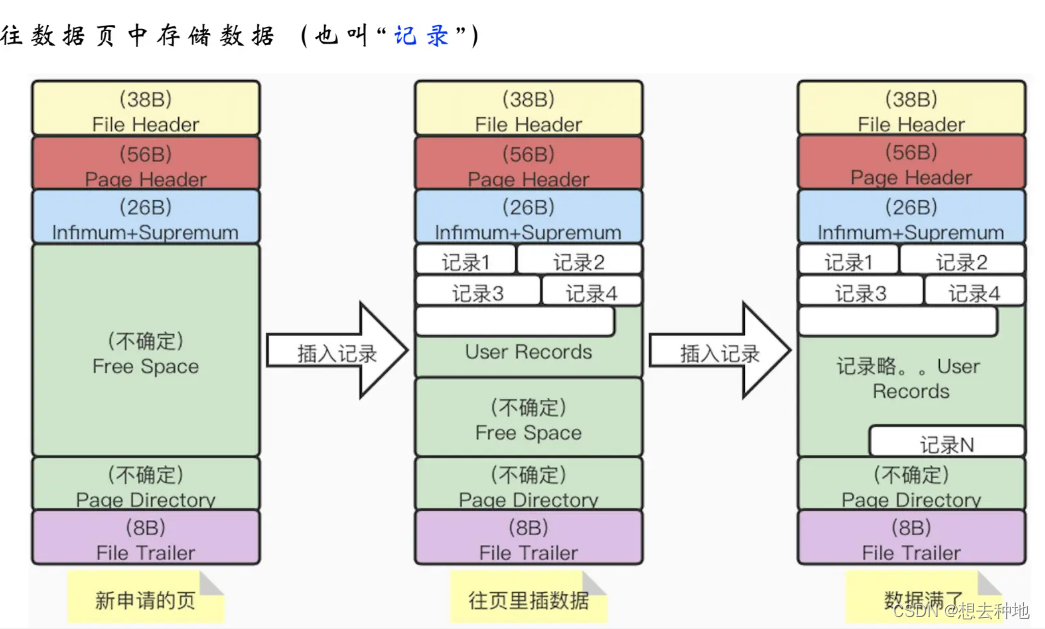

从上面的图中我们可以看到,当我们存储一条数据的时候,不仅会有我们真实存储的数据,还会有数据库本身的额外信息。
trx_id:一条事务对当前列进行写操作的事务id。
roll_pointer:一个指针,用于指向当前记录回滚时的undo log
还有一个隐藏字段roll_id,它的作用主要是用来当作主键,当我们在设计表的时候,如果没有设置自增主键,数据库会为我们自动生成一个roll_id当作自增主键。
记录头信息中几个字段的含义:
delete_flag:用于删除标记,0未删除,1已删除
min_rec_flag:B+树中每层非叶子节点中的最小的目录项记录,都会添加该标记。
n_owned:page页当中,用户存储的数据会被分为若干组,而n_owned代表这个组的“组长”,用来存放当前组的记录数。
heap_no:表示当前记录在页面堆中的相对位置。
record_type:表示当前的记录类型。0:普通记录 1:B+树非叶子节点的目录项记录2:infimum记录 3:supremum记录 .
next _record:指向下一条记录的指针,单向链表。
当我们删除某一条记录时,next_record指针将会重新指向被删除记录的下一条,并且被删除记录所在的组的“组长”的n_owned将会减一。
page directory
从上面我们我们可以看出,当我们想查询某条记录时,我们只能通过主键值从小到大的单向链表,从头结点一直向后查询,如果数据量很大时,我们查询的性能就会很低。
所以我们就会才有page directory,page directory类似于图书目录的形式,然后对其分组。
分组的规则如下:
①infimum只能有一条记录
②supremum可以有1-8条记录
③普通数据组可以有4-8条记录
分组步骤如下:
①刚开始时,只有两个分组,一个是infimum组,一个是supremum组。
②当我们像插入一条记录时,会根据页目录找到对应记录的主键值比要插入记录主键值大,但是差值最小的主键值,然后当前分组的n_owoed加1。
③当插入的记录的组已经满8条时,会将组中的记录拆分成两个组(一个组中4条记录,另一个组中5条记录)。并在拆分过程中,会在PageDirectory中新增一个槽,并记录这个新增分组中最大的那条记录的偏移量。
如果我们要查询某一条记录,查询过程是怎样的?
先通过二分法在页目录中找到,比要查询的数据的主键值要大,前一个组的“组长”(当前组主键值最大的那条记录)比要查询的记录的主键值小的记录,因为next_record是单向链表的,所以我们只能通过前一个分组的“组长”找到当前的分组的主键值最小的记录,然后通过最小记录的指针循环向下查询。















 2359
2359











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









