






最近在学习python爬虫,本篇博客用来记录学习当中遇到的一些小问题,会在学习和使用中持续更新~
一.Pycharm给字典中多个键值对批量加单引号
这篇2021年的博客中的方法现在仍然适用,本文也是按照这篇博客中的方法成功了,在此感谢这位兄弟!下面做一下总结
爬虫时经常需要复制请求标头,而复制下来的键值对是没有单引号,也没有逗号的,当表头中的信息特别多时,我们一个一个手动添加是非常不方便的。
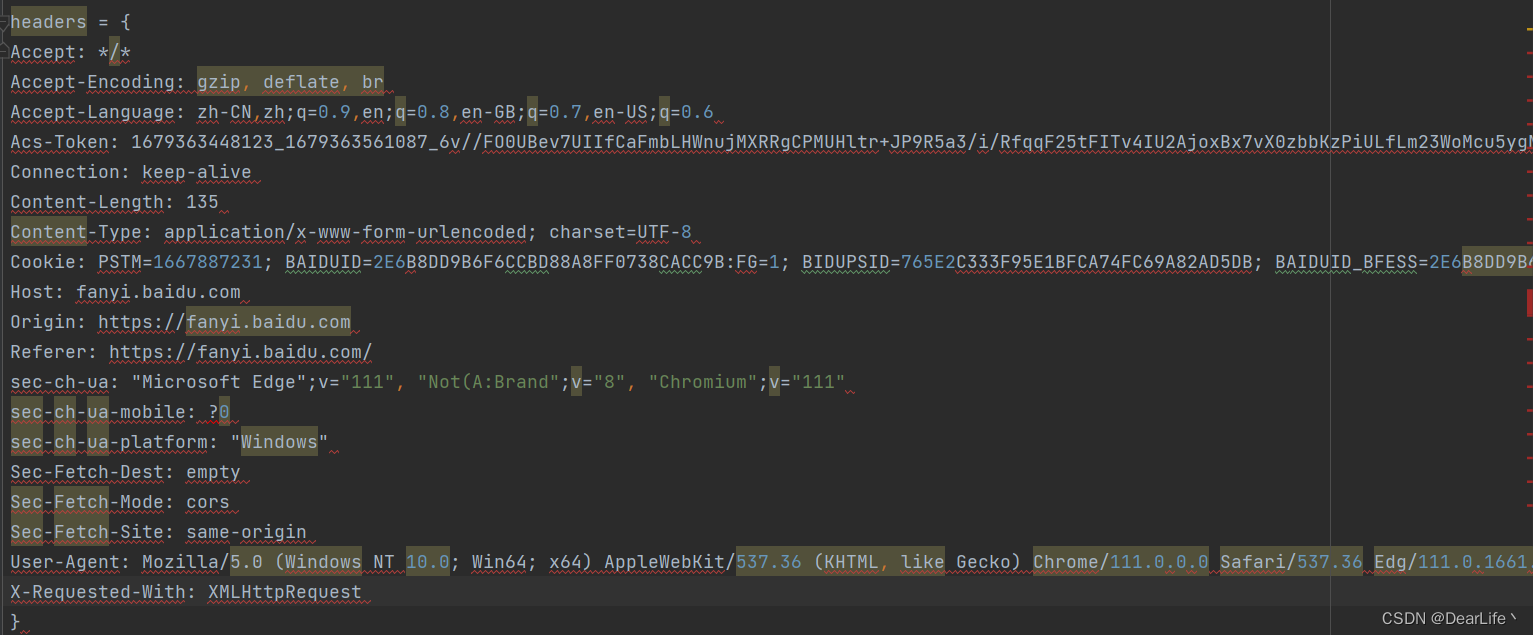
解决方法
1.使用pycharm的快捷键ctrl+R打开正则匹配窗口,在第一行、第二行分别输入: (.*?): (.*)和 '$1': '$2',(直接复制粘贴即可)
2.按如图所示顺序点击,即操作成功
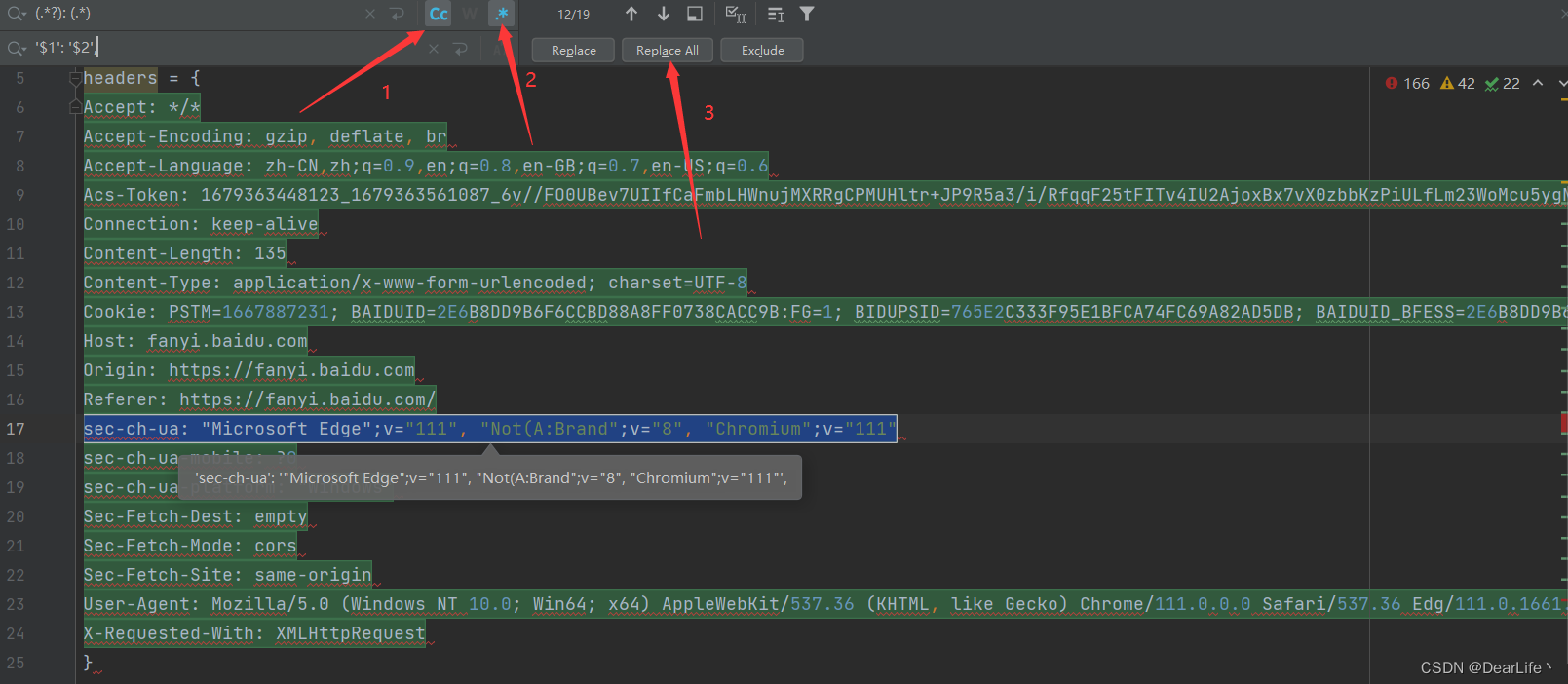
二.让爬取到的json格式数据看起来清晰明了
爬取到的json格式数据看起来特别不方便

如图,全都挤在一行里面了
快捷键ctrl+alt+L 如下图所示
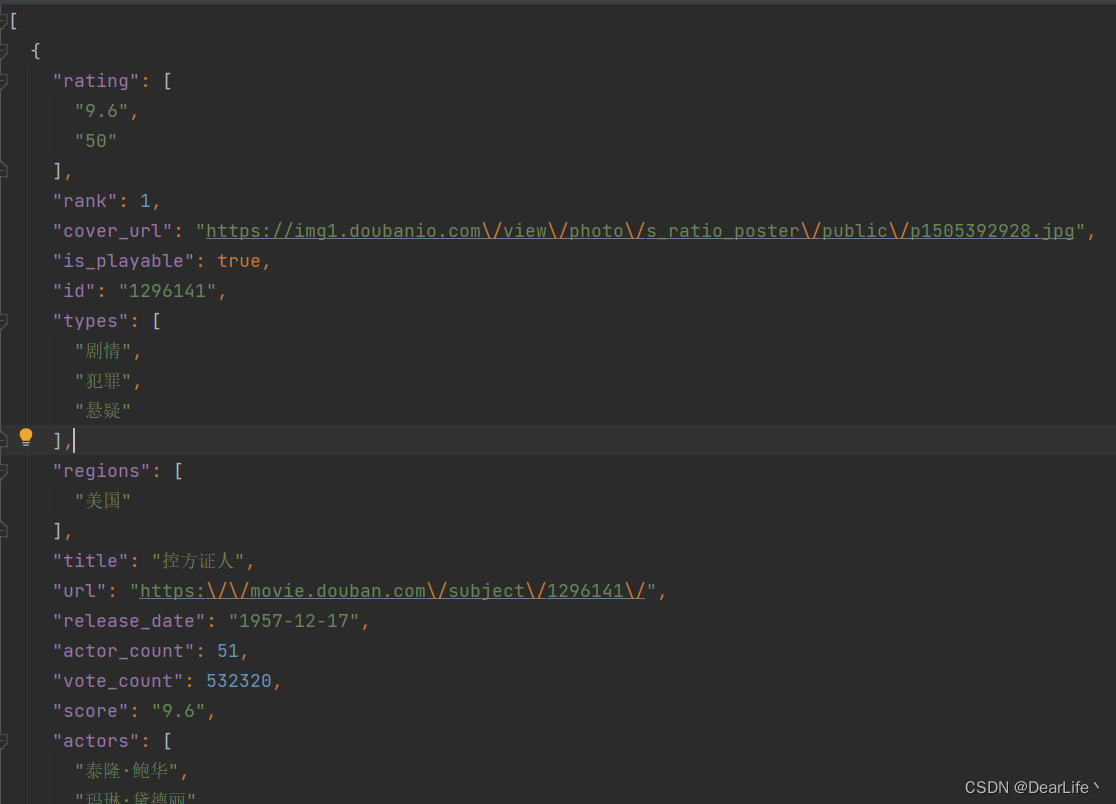
这里的快捷键会和QQ中的锁定QQ快捷键冲突,退出QQ或修改QQ热键即可。














 8403
8403











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









