







目录
一. 完善登录功能
1.问题分析
前面我们已经完成了后台系统的员工登录功能开发,但是还存在一个问题:用户如果不登录,直接访问系统首页面,照样可以正常访问。
这种设计并不合理,我们希望看到的效果应该是,只有登录成功后才可以访问系统中的页面,如果没有登录则跳转到登录页面。
那么,具体应该怎么实现呢?
答案就是使用过滤器或者拦截器,在过滤器或者拦截器中判断用户是否已经完成登录,如果没有登录则跳转到登录页面。
2.代码实现
实现步骤
1、创建自定义过滤器LoginCheckFilter
2、在启动类上加入注解@ServletComponentScan
3、完善过滤器的处理逻辑
1、创建自定义过滤器LoginCheckFilter
类LoginCheckFilter
位置
/*
检查用户是否已经完成登录
*/
@WebFilter(filterName = "loginCheckFilter",urlPatterns = "/*")
@Slf4j
public class LoginCheckFilter implements Filter {
@Override
public void doFilter(ServletRequest servletRequest, ServletResponse servletResponse, FilterChain filterChain) throws IOException, ServletException {
HttpServletRequest request = (HttpServletRequest) servletRequest;
HttpServletResponse response = (HttpServletResponse) servletResponse;
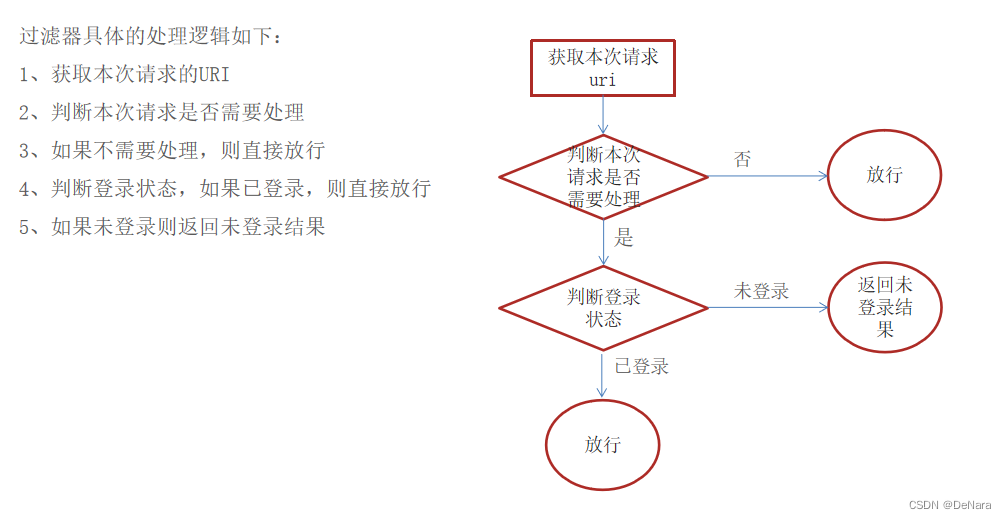
//1、获取本次请求的URI
String requestURI = request.getRequestURI();// /backend/index.html
log.info("拦截到请求:{}",requestURI);
filterChain.doFilter(request,response);
}
}
测试效果:log.info显示可以拦截到/* 即所有资源,过滤器设置成功

2、在启动类上加入注解@ServletComponentScan
/*启动类*/
@Slf4j/*做日志输出的注解,可以使用log*/
@SpringBootApplication
@ServletComponentScan/*加上这个 才可能会扫描@WebServlet注解,从而把过滤器创建出来*/
public class ReggieApplication {
public static void main(String[] args) {
SpringApplication.run(ReggieApplication.class,args);
log.info("项目启动成功...");
}
}
3、完善过滤器的处理逻辑
package com.itheima.reggie.filter;
import com.alibaba.fastjson.JSON;
import com.itheima.reggie.common.R;
import lombok.extern.slf4j.Slf4j;
import org.springframework.util.AntPathMatcher;
import javax.servlet.*;
import javax.servlet.annotation.WebFilter;
import javax.servlet.http.HttpServletRequest;
import javax.servlet.http.HttpServletResponse;
import java.io.IOException;
/*
检查用户是否已经完成登录
*/
@WebFilter(filterName = "loginCheckFilter",urlPatterns = "/*")
@Slf4j
public class LoginCheckFilter implements Filter {
//路径匹配符,支持通配符
public static final AntPathMatcher PATH_MATCHER = new AntPathMatcher();
@Override
public void doFilter(ServletRequest servletRequest, ServletResponse servletResponse, FilterChain filterChain) throws IOException, ServletException {
HttpServletRequest request = (HttpServletRequest) servletRequest;
HttpServletResponse response = (HttpServletResponse) servletResponse;
//1、获取本次请求的URI
String requestURI = request.getRequestURI();// /backend/index.html
log.info("拦截到请求:{}",requestURI);
//定义不需要处理的请求路径
//不需要处理是指不需要检查是否已经登录,直接放行,像backend front都是静态页面 直接放行
//**通配符
//登录和退出,不需要检查用户是否登录,直接可以放行
String[] urls = new String[]{
"/employee/login",
"/employee/logout",
"/backend/**",
"/front/**"
};
//2、判断本次请求是否需要处理
boolean check = check(urls, requestURI);
//3、如果不需要处理,则直接放行
if(check){
log.info("本次请求{}不需要处理",requestURI);
filterChain.doFilter(request,response);
return;
}
//4、判断登录状态,如果已登录,则直接放行
if(request.getSession().getAttribute("employee")!=null){
log.info("用户已登录,用户id为:{}",request.getSession().getAttribute("employee"));
filterChain.doFilter(request,response);
return;/*表示结束方法,不会执行后面所有的代码*/
}
log.info("用户未登录");
//5、如果未登录则返回未登录结果,通过输出流方式向客户端页面响应数据。
response.getWriter().write(JSON.toJSONString(R.error("NOTLOGIN")));
return;
// 过滤器的作用在用户请求到达servlet之前,拦截下来做预处理,处理之后便执行chain.doFilter(request,response)这个方法
// 如果还有别的过滤器,那么将处理好的请求传给下个过滤器
// 如果就这一个过滤器,你们就将处理好的请求直接发给servlet
// chain.doFilter(request,response)是过滤器的必要操作,目的是如果有多个过滤器需要处理同一个url时把请求传给下一个过滤器。
}
/*
方法:路径匹配,检查本次请求是否需要放行,匹配就直接放行
*/
public boolean check(String[] urls,String requestURI){
for(String url:urls){
boolean match = PATH_MATCHER.match(url, requestURI);
if (match){
return true;
}
}
return false;
}
}
3.功能测试
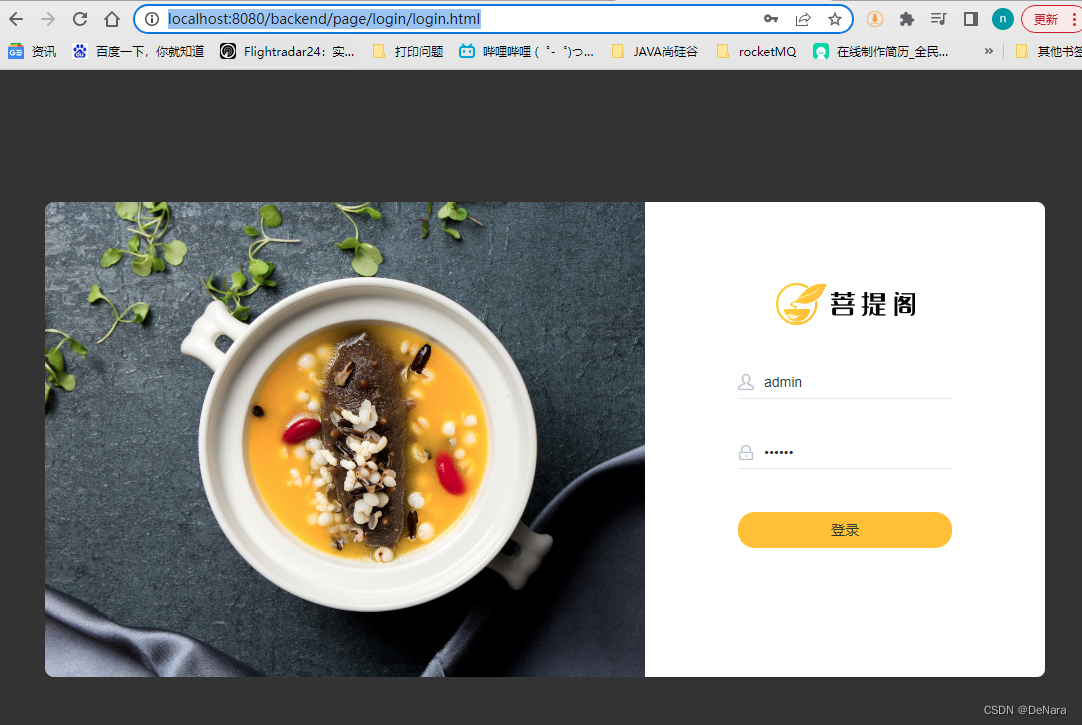
输入http://localhost:8080/backend/index.html 会自动跳转到 http://localhost:8080/backend/page/login/login.html页面
日志输出正常

正常登录的话,可以拦截到,并正常输出日志。

功能测试成功,
退出功能正常
二. 基础知识复习
1. Filter过滤器
注意:查找servlet API时,应在Java EE 7 api文档里找
1. Filter概述
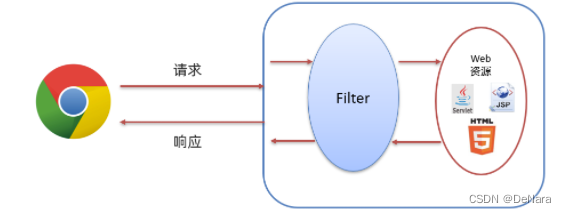
Filter 表示过滤器,是 JavaWeb 三大组件(Servlet、Filter、Listener)之一。
过滤器可以把对资源的请求拦截下来,从而实现一些特殊的功能。
如下图所示,浏览器可以访问服务器上的所有的资源(servlet、jsp、html等)
而在访问到这些资源之前可以使过滤器拦截来下,也就是说在访问资源之前会先经过 Filter,如下图
2. Filter快速入门进行 `
Filter` 开发分成以下三步实现
- 定义类,实现 Filter接口,并重写其所有方法
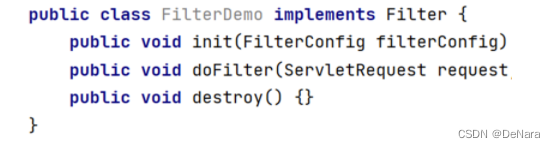
- 配置Filter拦截资源的路径:在类上定义
@WebFilter注解。而注解的value属性值/*表示拦截所有的资源

- 在doFilter方法中输出一句话,并放行
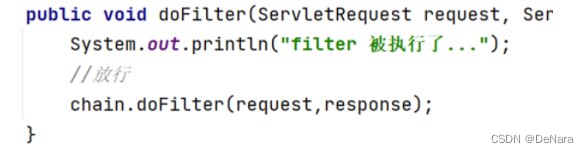
上述代码中的
chain.doFilter(request,response);就是放行,也就是让其访问本该访问的资源。

3. Filter执行流程
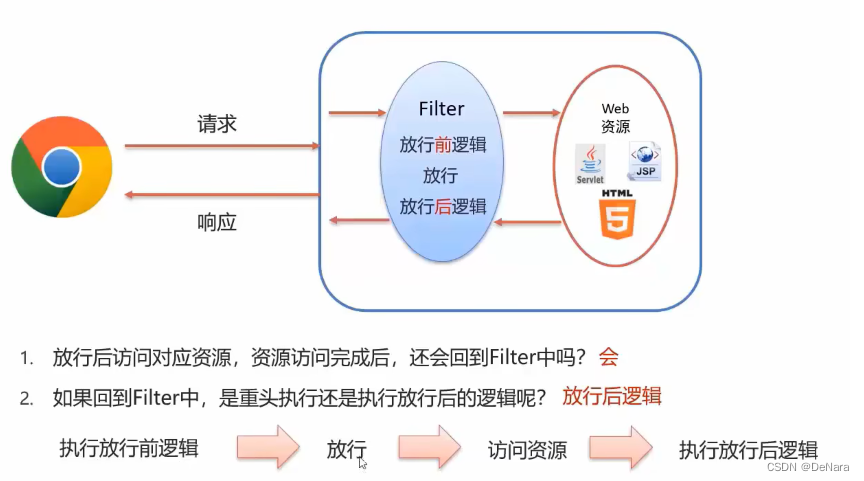
接下来我们通过代码验证一下,在 doFilter() 方法前后都加上输出语句,如下

同时在 hello.jsp 页面加上输出语句,如下
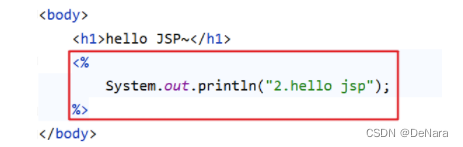
执行访问该资源打印的顺序是按照我们标记的标号进行打印的话,说明我们上边总结出来的流程是没有问题的。启动服务器访问 hello.jsp 页面,在控制台打印的内容如下:

4. Filter拦截路径配置
拦截路径表示 Filter 会对请求的哪些资源进行拦截,使用 @WebFilter 注解进行配置。如:@WebFilter("拦截路径")
拦截路径有如下四种配置方式:
- 拦截具体的资源:/index.jsp:只有访问index.jsp时才会被拦截
- 目录拦截:/user/*:访问/user下的所有资源,都会被拦截
- 后缀名拦截:*.jsp:访问后缀名为jsp的资源,都会被拦截
- 拦截所有:/*:访问所有资源,都会被拦截
通过上面拦截路径的学习,大家会发现拦截路径的配置方式和 Servlet 的请求资源路径配置方式一样,但是表示的含义不同。
5. Filter过滤器链
过滤器链是指在一个Web应用,可以配置多个过滤器,这多个过滤器称为过滤器链。
如下图就是一个过滤器链,我们学习过滤器链主要是学习过滤器链执行的流程
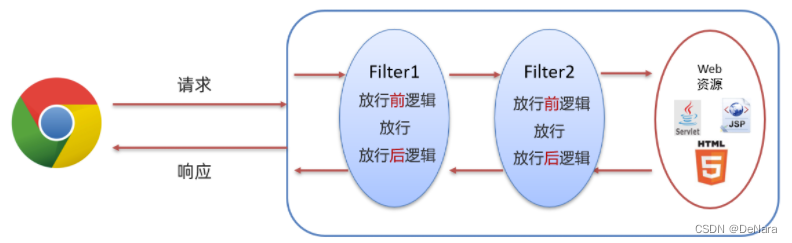
上图中的过滤器链执行是按照以下流程执行:
- 执行
Filter1的放行前逻辑代码 - 执行
Filter1的放行代码 - 执行
Filter2的放行前逻辑代码 - 执行
Filter2的放行代码 - 访问到资源
- 执行
Filter2的放行后逻辑代码 - 执行
Filter1的放行后逻辑代码
以上流程串起来就像一条链子,故称之为过滤器链。
不再演示
2. return
return;直接写是结束方法体,不会执行该方法后面的所有代码。
3. URI和URL
URI:统一资源标识符 ,表示web上每一种可用的资源,是抽象的概念
URL: 统一资源定位符,URL是可以具体来定位资源,访问资源















 778
778











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









