







##kubernetes常用命令
删除集群中所有运行中的pod
kubectl delete pods --all
常见错误 节点notReady
/etc/hosts/问题:主机ip问题 重启电脑后/etc/hosts文件的配置没了
(一)云原生基础
ECS弹性部署
ECS 云服务器,弹性计算服务
ansible和terraform区别
terraform是编排工具,ansible是配置管理工具。编配/配置是一个创建基础设施的过程——虚拟机、网络组件、数据库等等。

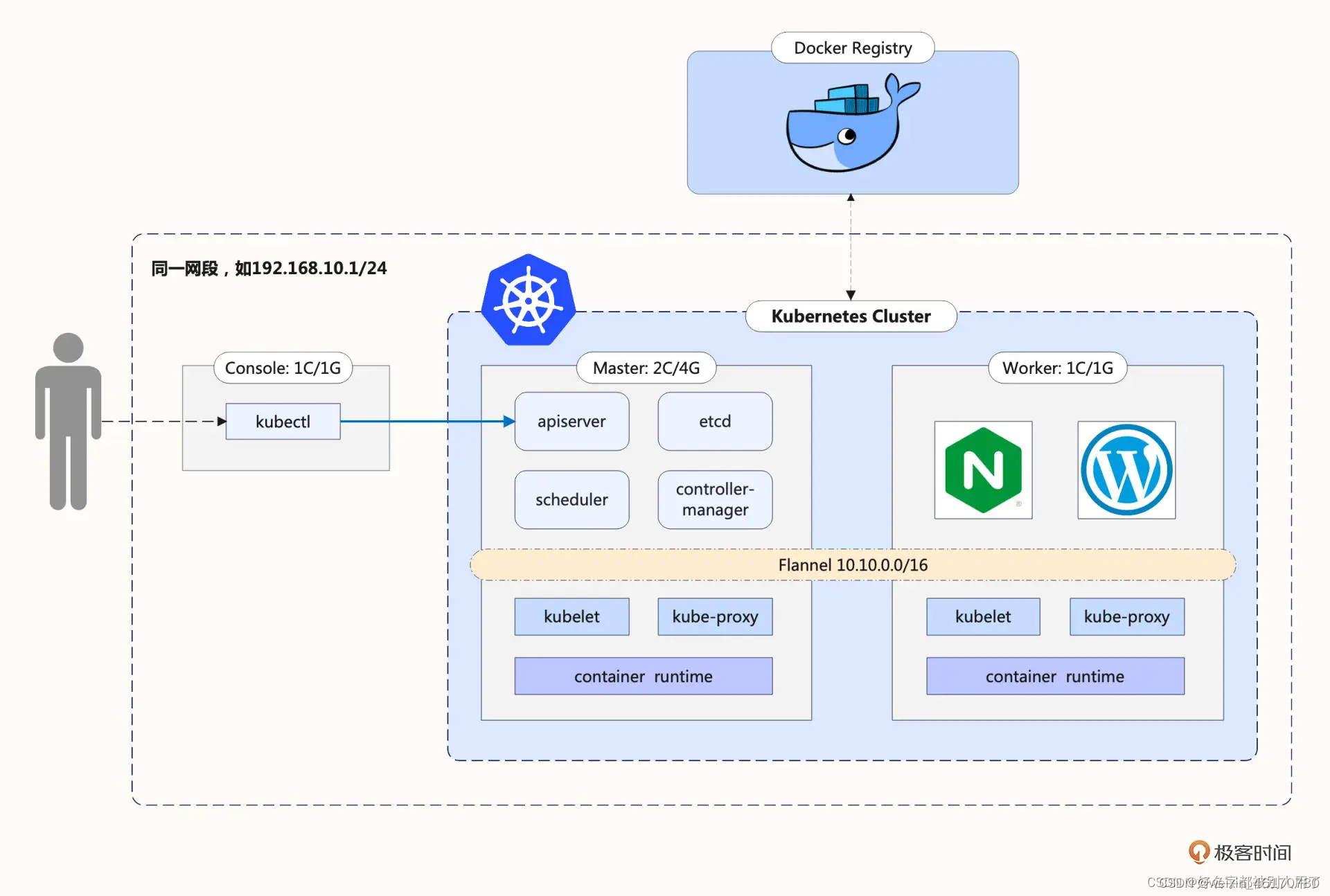
k8s介绍
Master主要负责整个集群的管理工作,为集群提供管理接口,并监控和编排集群中的各个工作节点。各节点负责以 Pod形式运行Docker容器。
Master节点主要由apiserver、scheduler、contrller三个系统组件以及一个集群存储系统 etcd
组成。而API、UI、CLI则为管理员客户端操作方式。
-
kube-apiserver:Kubernetes API,集群的统一入口,各组件协调者,以RESTful
API提供接口服务,所有对象资源的增删改查和监听操作都交给APIServer处理后再提交给Etcd存储。 -
kube-controller-manager(RC):处理集群中常规后台任务,一个资源对应一个控制器,而ControllerManager就是负责管理这些控制器的。
-
kube-scheduler:根据调度算法为新创建的Pod选择一个Node节点,可以任意部署,可以部署在同一个节点上,也可以部署在不同的节点上。
-
etcd:分布式键值存储系统。用于保存集群状态数据,比如Pod、Service等对象信息。
创建pod
pod.yaml
apiVersion: v1
kind: Pod
metadata:
name: demo
spec:
containers:
- name: testpod
image: alpine:latest
command: ["ping", "8.8.8.8"]
kubectl apply -f pod.yaml
kubectl get pods
kubectl logs demo
kubectl delete -f pod.yaml
(二)搭建k8s集群
容器云部署
1.基于dokcer desktop在本地搭建单节点k8s集群
(1)docker compose
(2)minikube等
2.基于dokcer desktop在本地搭建私有云多节点k8s集群
(1)docker swarm
局域网搭建集群
(2)kubeadm搭建
- 安装docker服务
ubuntu系统中安装
sudo apt-get update && sudo apt-get install docker.io
sudo systemctl start docker
sudo systemctl status docker
问题wi11 中 wsl windows for docker 用在wsl2 ubuntu系统中 unit not found
解决:ubun系统中下载docker
- 安装前的准备工作:
版本信息:
master节点:
操作系统:ubuntu20.04
Docker client:24.0.6
Docker server:24.0.2
kubectl:1.25.9
node:
操作系统:
操作系统:ubuntu22.04
Docker client:23.0.5
Docker server:23.0.5
kubectl:1.25.9
修改主机名
//master节点主机名设为Master
sudo vi /etc/hostname
#或者这样修改
sduo hostnamectl set-hostname Master
修改 Docker 配置
在“/etc/docker/daemon.json”里把 cgroup 的驱动程序改成 systemd ,然后重启 Docker 的守护进程,具体的操作我列在了下面:
cat <<EOF | sudo tee /etc/docker/daemon.json
{
"exec-opts": ["native.cgroupdriver=systemd"],
"log-driver": "json-file",
"log-opts": {
"max-size": "100m"
},
"storage-driver": "overlay2"
}
EOF
sudo systemctl enable docker
sudo systemctl daemon-reload
sudo systemctl restart docker
问题:
System has not been booted with systemd as init system (PID 1). Can't operate.host is down
原因;wsl不支持systemctl
解决方法:方法一:
sudo apt-get update // 更新软件包列表
$ sudo apt-get install -y systemd
sudo nano /etc/wsl.conf):
[boot]
systemd=true
//关掉重启wsl
wsl.exe --shutdown
方法二:
使用
sudo service docker start
修改网络设置
为了让 Kubernetes 能够检查、转发网络流量,你需要修改 iptables 的配置,启用“br_netfilter”模块:
cat <<EOF | sudo tee /etc/modules-load.d/k8s.conf
br_netfilter
EOF
cat <<EOF | sudo tee /etc/sysctl.d/k8s.conf
net.bridge.bridge-nf-call-ip6tables = 1
net.bridge.bridge-nf-call-iptables = 1
net.ipv4.ip_forward=1 # better than modify /etc/sysctl.conf
EOF
sudo sysctl --system
修改交换分区
需要修改“/etc/fstab”,关闭 Linux 的 swap 分区,提升 Kubernetes 的性能:
sudo swapoff -a
free
sudo sed -ri '/\sswap\s/s/^#?/#/' /etc/fstab
- 安装kubeadm
配置阿里云镜像源
sudo apt install -y apt-transport-https ca-certificates curl
curl https://mirrors.aliyun.com/kubernetes/apt/doc/apt-key.gpg | sudo apt-key add -
cat <<EOF | sudo tee /etc/apt/sources.list.d/kubernetes.list
deb https://mirrors.aliyun.com/kubernetes/apt/ kubernetes-xenial main
EOF
sudo apt update
问题:直接通过apt install 会报No apt package “kubeadm”, but there is a snap with that name.
Try “snap install kubeadm”;
问题:通过snap install --classic 会报error: a single snap name is needed to specify mode or channel flags
验证版本
sudo apt install -y kubeadm=1.5.9-00 kubelet=1.25.9-00 kubectl=1.25.9-00
kubeadm version
kubectl version --client
sudo systemctl enable --now kubelet
锁定软件版本,避免意外升级导致错误
sudo apt-mark hold kubeadm kubelet kubectl
- 下载kubernetes组件镜像
kubeadm 把 apiserver、etcd、scheduler 等组件都打包成了镜像,以容器的方式启动 Kubernetes,但这些镜像不是放在 Docker Hub 上,而是放在 Google 自己的镜像仓库网站 gcr.io
//使用命令 kubeadm config images list 可以查看安装 Kubernetes 所需的镜像列表,参数 --kubernetes-version 可以指定版本号:
kubeadm config images list --kubernetes-version v1.25.9
//输出
registry.k8s.io/kube-apiserver:v1.25.9
registry.k8s.io/kube-controller-manager:v1.25.9
registry.k8s.io/kube-scheduler:v1.25.9
registry.k8s.io/kube-proxy:v1.25.9
registry.k8s.io/pause:3.8
registry.k8s.io/etcd:3.5.6-0
registry.k8s.io/coredns/coredns:v1.9.3
//然后依次docker pull
docker pull registry.k8s.io/coredns/coredns:v1.9.3
问题:
系统重启之后 image 全部消失了 再重新现在 就下载不了
解决:国内镜像源
配置国内镜像源:
--image-repository registry.aliyuncs.com/google_containers
sudo kubeadm init --image-repository registry.aliyuncs.com/google_containers --kubernetes-version=v1.25.9 --pod-network-cidr=10.10.0.0/16 --apiserver-advertise-address=172.22.1.117 --cri-socket=unix:///var/run/cri-dockerd.sock
- 安装master节点
安装cri-dockerd
//下载二进制文件
wget https://github.com/Mirantis/cri-dockerd/releases/download/v0.3.4/cri-dockerd-0.3.4.amd64.tgz
//解压
tar -zxvf cri-dockerd-0.2.6.amd64.tgz
tar -zxvf cri-dockerd-0.3.4.amd64.tgz
sudo cp ./cri-dockerd//cri-dockerd /usr/bin/
mkdir Cri-dockerd
cd Cri-dockerd/
git clone https://github.com/Mirantis/cri-dockerd.git
sudo cp cri-dockerd/packaging/systemd/* /etc/systemd/system/
sudo vim /etc/systemd/system/cri-docker.service
//
registry.aliyuncs.com/google_containers/pause:3.8
文件 /etc/systemd/system/cri-docker.service Service.ExecStart 字段增加 --network-plugin 与 --pod-infra-container-image 选项。--pod-infra-container-image 镜像tag需要根据具体k8s安装版本指定。也就是要修改网络和根容器镜像。
ExecStart=/usr/bin/cri-dockerd --container-runtime-endpoint fd:// --network-plugin=cni --pod-infra-container-image=registry.aliyuncs.com/google_containers/pause:3.8
sudo systemctl daemon-reload
sudo systemctl enable cri-docker
sudo systemctl start cri-docker
sudo systemctl status cri-docker
//kubeadm init 的参数
-–pod-network-cidr,设置集群里 Pod 的 IP 地址段。
-–apiserver-advertise-address,设置 apiserver 的 IP 地址,对于多网卡服务器来说很重要(比如 VirtualBox 虚拟机就用了两块网卡),可以指定 apiserver 在哪个网卡上对外提供服务。
-–kubernetes-version,指定 Kubernetes 的版本号。
sudo kubeadm init --image-repository registry.aliyuncs.com/google_containers --kubernetes-version=v1.25.9 --pod-network-cidr=10.10.0.0/16 --apiserver-advertise-address=172.22.1.117 --service-cidr=10.1.0.0/16 --cri-socket=unix:///var/run/cri-dockerd.sock
问题1:
sudo kubeadm init --kubernetes-version=v1.25.9
error execution phase preflight: [preflight] Some fatal errors occurred:
[ERROR CRI]: container runtime is not running:
原因:这个问题是针对使用containerd作为CRI的情况 ,containerd安装的时候默认把CRI禁用了
解决:
sudo vim /etc/containerd/config.toml
//将disabled_plugins = ["cri"]中的“cri”删掉
//变为disabled_plugins = []
//保存退出
//重启containerd
sudo systemctl restart containerd
问题2:kube init一直不运行
容器运行时接口CRI:kubelet1.24以后 弃用了docker dockershim
docker下载时自动配置了containerd.sock
还可以使用第三方接口:docker-containerd插件 cri-dockerd
问题3:
Found multiple CRI endpoints on the host. Please define which one do you wish to use by setting the ‘criSocket’ field in the kubeadm configuration file
原因:没有整合kubelet和cri-dockerd
解决办法:在命令后面加上以下选项
--cri-socket unix:///var/run/cri-dockerd.sock
问题4;kubelet连接拒绝
原因:kubelet的cgroup和docker的cgroup不一致
修改了 /etc/docker/daemon.json的驱动无法生效
解决方法:修改kubelet的驱动为cgroupfs
sudo rm -rf /etc/kubernetes/*
sudo rm -rf ~/.kube/*
sudo rm -rf /var/lib/etcd/*
sudo kubeadm reset --cri-socket=unix:///var/run/cri-dockerd.sock
sudo cat /var/lib/kubelet/config.yaml | grep cgroup
sudo vim /etc/systemd/system/kubelet.service.d/10-kubeadm.conf
sudo systemctl daemon-reload
sudo systemctl restart docker
sudo systemctl status docker
sudo systemctl restart kubelet
sudo systemctl status kubelet
journalctl -xeu kubelet
修改/etc/systemd/system/kubelet.service.d/10-kubeadm.conf文件或者/usr/lib/systemd/system/kubelet.service.d/10-kubeadm.conf,增加–cgroup-driver=cgroupfs
Environment=“KUBELET_KUBECONFIG_ARGS=–bootstrap-kubeconfig=/etc/kubernetes/bootstrap-kubelet.conf --kubeconfig=/etc/kubernetes/kubelet.conf --cgroup-driver=cgroupfs”
问题5:wsl: 检测到 localhost 代理配置,但未镜像到 WSL。NAT 模式下的 WSL 不支持 localhost 代理。
解决:防火墙开启服务
问题6:kubelet和docker cgroup修改之后不起作用
解决:重启系统
问题7:
[ERROR DirAvailable–var-lib-etcd]: /var/lib/etcd is not empty
rm -rf /var/lib/etcd
初始化成功后的页面如下:
Your Kubernetes control-plane has initialized successfully!
To start using your cluster, you need to run the following as a regular user:
mkdir -p $HOME/.kube
sudo cp -i /etc/kubernetes/admin.conf $HOME/.kube/config
sudo chown $(id -u):$(id -g) $HOME/.kube/config
Alternatively, if you are the root user, you can run:
export KUBECONFIG=/etc/kubernetes/admin.conf
You should now deploy a pod network to the cluster.
Run "kubectl apply -f [podnetwork].yaml" with one of the options listed at:
https://kubernetes.io/docs/concepts/cluster-administration/addons/
Then you can join any number of worker nodes by running the following on each as root:
kubeadm join 172.22.1.117:6443 --token 8icc6m.fcqg5dbnwvqgrris \
--discovery-token-ca-cert-hash sha256:3d96957a461f0c7bcb2d290f712d6eb2b278707e3bc4559a9586cfa3761904ca
按照上述提示,配置.kube文件
mkdir -p $HOME/.kube
sudo cp -i /etc/kubernetes/admin.conf $HOME/.kube/config
sudo chown $(id -u):$(id -g) $HOME/.kube/config
问题:
sudo kubectl get node
The connection to the server localhost:8080 was refused - did you specify the right host or port?
解决:
// 临时生效(退出当前窗口重连环境变量失效)
export KUBECONFIG=/etc/kubernetes/admin.conf
// 永久生效(推荐)
echo "export KUBECONFIG=/etc/kubernetes/admin.conf" >> ~/.bashrc
source ~/.bashrc
还是无法解决,使用下面的
sudo kubectl --kubeconfig /etc/kubernetes/admin.conf get nodes
配置pod网络
sudo kubectl apply --kubeconfig /etc/kubernetes/admin.conf -f https://raw.githubusercontent.com/coreos/
flannel/master/Documentation/kube-flannel.yml
sudo kubectl apply --kubeconfig /etc/kubernetes/admin.conf -f kube-flannel.yml
sudo kubectl --kubeconfig /etc/kubernetes/admin.conf get nodes
//如下显示 pod网络部署成功 flannel网络
NAME STATUS ROLES AGE VERSION
desktop-bfmi3u8 Ready control-plane 95m v1.25.9
问题:
master节点的ROLES只显示control-plane 不显示master
解决:
//节点标签
kubectl get nodes --show-labels
(3)搭建K8S Dashboard
$ curl -o kubernetes-dashboard.yaml https://raw.githubusercontent.com/kubernetes/dashboard/master/aio/deploy/recommended/kubernetes-dashboard.yaml
问题: error validating “kubernetes-dashboard.yaml”: error validating data: [apiVersion not set, kind not set]; if you choose to ignore these errors, turn validation off with --validate=false
kubectl apply -f https://raw.githubusercontent.com/kubernetes/dashboard/v3.0.0-alpha0/charts/kubernetes-dashboard.yaml
curl -o kubernetes-dashboard.yaml https://raw.githubusercontent.com/kubernetes/dashboard/v3.0.0-alpha0/charts/kubernetes-dashboard.yaml
sudo kubectl apply --kubeconfig /etc/kubernetes/admin.conf -f https://raw.githubusercontent.com/kubernetes/dashboard/v3.0.0-alpha0/charts/kubernetes-dashboard.yaml
问题:v3.0.0 不兼容kubenetes 1.25.9 需要下载两个组件
解决改为v2.7.0
wget https://raw.githubusercontent.com/kubernetes/dashboard/v2.7.0/aio/deploy/recommended.yaml
sudo kubectl apply --kubeconfig /etc/kubernetes/admin.conf -f https://raw.githubusercontent.com/kubernetes/dashboard/v2.7.0/aio/deploy/recommended.yaml
sudo kubectl apply --kubeconfig /etc/kubernetes/admin.conf -f recommended.yaml
sudo kubectl --kubeconfig /etc/kubernetes/admin.conf taint nodes desktop-bfmi3u8 node-role.kubernetes.io/control-plane
:NoSchedule-
node/desktop-bfmi3u8 untainted
sudo kubectl get pods --kubeconfig /etc/kubernetes/admin.conf -n kube-system -o wide
sudo kubectl --kubeconfig /etc/kubernetes/admin.conf describe pods -n kube-system coredns-c676cc86f-fjr2f
sudo kubectl --kubeconfig /etc/kubernetes/admin.conf describe node desktop-bfmi3u8
sudo kubectl get no --kubeconfig /etc/kubernetes/admin.conf -o yaml | grep taint -A 5
问题:
sudo kubectl get nodes --kubeconfig /etc/kubernetes/admin.conf
The connection to the server 172.22.1.117:6443 was refused - did you specify the right host or port?
解决:
//每次重启电脑都要关闭交换分区
sudo swapoff -a
- 节点加入
kubeadm join -v=2 172.22.1.117:6443 --token 8icc6m.fcqg5dbnwvqgrris --discovery-token-ca-cert-hash sha256:3d96957a461f0c7bcb2d290f712d6eb2b278707e3bc4559a9586cfa3761904ca --image-repository registry.aliyuncs.com/google_containers --kubernetes-version=v1.25.9 --cri-socket=unix:///var/run/cri-dockerd.sock
问题1:k8s从节点加入主节点[preflight] Running pre-flight checks卡住
解决:
时间同步:
kubernetes要求集群中的节点时间必须精确一致,这里直接使用chronyd服务从网络同步时间
#启动chronyd服务
systemctl start chronyd
#设置chronyd服务开机启动
systemctl enable chronyd
验证
使用date命令查看时间是否同步了,结果一致
如果遇到时间同步问题重启
kubeadm join -v 2 输出日志
ping master节点ip ping不通
ip地址写错了
//
controlPlaneEndpoint: "公网ip:6443"
问题2:coredns服务一直是creating 而不是running
解决方案:手动写入/run/flannel/subnet.env文件,再次查看为running
FLANNEL_NETWORK与pod-network-cidr保持一致
sudo vim /run/flannel/subnet.env
FLANNEL_NETWORK=10.10.0.0/16
FLANNEL_SUBNET=110.10.1.0/24
FLANNEL_MTU=1450
FLANNEL_IPMASQ=true
EOF
问题3:dashboard没有自动拉取镜像,服务也没跑起来
解决:
kubectl proxy
输出Starting to serve on 127.0.0.1:8001
然后通过
http://localhost:8001/api/v1/namespaces/kubernetes-dashboard/services/https:kubernetes-dashboard:/proxy
访问
部署了某个服务没有成功如何删除这个服务?
防火墙服务未开启
sudo systemctl stop firewalld
Failed to stop firewalld.service: Unit firewalld.service not loaded.
原因:未安装防火墙
selinux
sudo setenforce 0
sudo: setenforce: command not found
sudo sed -i 's/^SELINUX=enforcing$/SELINUX=disabled/' /etc/selinux/config
sed: can't read /etc/selinux/config: No such file or directory
3.基于公有云搭建多节点k8s集群
云服务器
购买服务
4.在线免费搭建k8s集群
网站:play-with-k8s
(1)初始化master
# --apiserver-advertise-address指定master在集群中的通讯地址
# --pod-network-cidr指定集群的子网范围
kubeadm init --apiserver-advertise-address 192.168.0.8 --pod-network-cidr=10.244.0.0/16
执行结果如下:
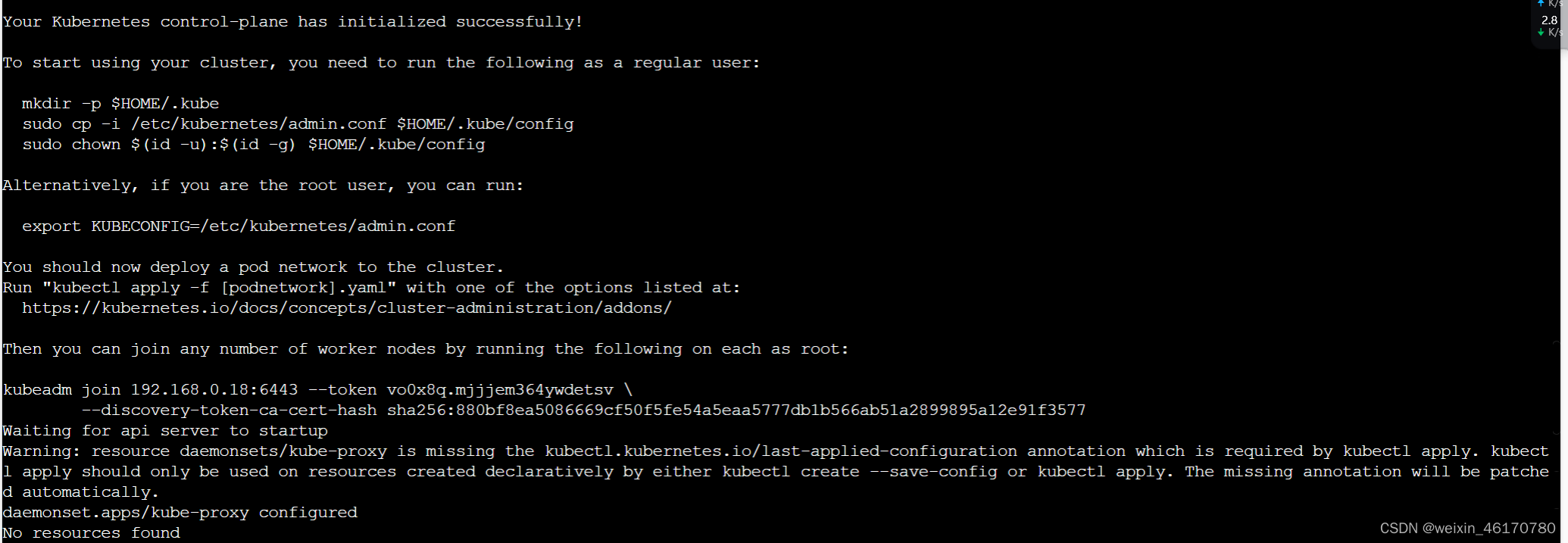
执行内容主要包括:
执行内容主要包括:
- kubeadm执行初始化前的检查;
- 生成token和证书;
- 生成kubeConfig文件,后续kubelet与Master节点通信时需要用到这个;
- 安装Master组件,会从Google的Registry下载组件的Docker镜像。这一步可能会花一些时间,主要取决于网络质量;
- 安装附加组件kube-proxy和kube-dns;
- Kubernetes Master初始化成功;
- 提示如何配置kubectl,参考(2);
- 提示如何安装Pod网络,参考(3);
- 提示如何注册其他节点到Cluster,参考(4);
(2)配置kubectl
# 为root用户使用kubectl做配置
export KUBECONFIG=/etc/kubernetes/admin.conf
(3)安装pod网络
kubectl apply -f https://raw.githubusercontent.com/coreos/flannel/master/Documentation/kube-flannel.yml
(4)注册其他节点到Cluster
kubeadm join 192.168.0.8:6443 --token pwavj7.pq9wskbhg1gc1ws3 \
--discovery-token-ca-cert-hash sha256:8490581b6d223133473f0037104aaa9dac96f7dd9a01c3f54b3c50719540df24
5.搭建混合云集群
公有云+私有云















 269
269











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









