






原文章:NSGA2算法原理及python实现_w要变强的博客-CSDN博客_nsga2 python
算法原理不多说了,网上都有,我是在NSGAII里加上约束违反值计算,实现不等式约束
RCM01问题:

# 这是Kalyanmoy Deb教授流行的NSGA-II算法的python实现
# 导入模块
import math
import random
import matplotlib.pyplot as plt
# 第一个约束函数
def function1(x1, x2, x3, x4):
z1 = 0.0625 * x1
value = 1.7781 * z1 * x3 ** 2 + 0.6224 * z1 * x2 * x4 + 3.1661 * z1 ** 2 * x4 + 19.84 * z1 ** 2 * x3
return value
# 第二个约束函数
def function2(x3, x4):
value = -math.pi * x3 ** 2 * x4 - (4 / 3) * math.pi * x3 ** 3
return value
#计算约束违反值
def CV(x):
z1 = 0.0625 * x[0]
z2 = 0.0625 * x[1]
g1 = 0.00954 * x[2] - z2
g2 = 0.0193 * x[2] - z1
if g1<=0 and g2<=0:
return 0
elif g1<=0 and g2>0:
return g2
elif g2<=0 and g1>0:
return g1
elif g1>0 and g2>0:
return g1+g2
# 查找列表值的索引的函数
def index_of(a, list):
for i in range(0, len(list)):
if list[i] == a:
return i
return -1
# 按序号排序的功能
def sort_by_values(list1, values): # list为下标序列,values为值序列
sorted_list = []
while (len(sorted_list) != len(list1)): # 遍历len(list1)次
if index_of(min(values), values) in list1:
sorted_list.append(index_of(min(values), values)) # 查找该层次中的最小值所在的索引
values[
index_of(min(values), values)] = math.inf # math.inf 浮点正无限(设置最小的(边界))的值为无穷,当找不到的时候设置最后一个为浮点正无限(return -1)
return sorted_list
# 执行NSGA-II快速非支配排序的功能
def fast_non_dominated_sort(values1, values2,cv):
S = [[] for i in range(0, len(values1))] # 生成values1(种群大小)个空列表的二维列表S,S记录被P支配的集合
front = [[]] # 一个空的二维列表
n = [0 for i in range(0, len(values1))] # 生成values1(种群大小)个0的一维列表n,n指p被支配的个数
rank = [0 for i in range(0, len(values1))] # 生成values1(种群大小)个0的以为列表,rank指非支配序
for p in range(0, len(values1)): # p为种群中的每个个体,遍历种群
S[p] = [] # 初始化当前个体p支配的集合
n[p] = 0 # 初始化当前个体p被支配的个数
for q in range(0, len(values1)): # q为种群中的每个个体,遍历种群(两层遍历达到每两两都进行比较)
if cv[p]==0 and cv[q]==0: #当p和q都不违反约束时
if (values1[p] > values1[q] and values2[p] > values2[q]) or (
values1[p] >= values1[q] and values2[p] > values2[q]) or (
values1[p] > values1[q] and values2[p] >= values2[q]): # 如果函数1当前值p大于函数1其他值而且函数2当前值大于函数2其他值
# 或者 函数1当前值p不小于函数1其他值而且函数2当前值大于函数2其他值
# 或者 函数1当前值p大于函数1其他值而且函数2当前值不小于函数2其他值
# (判断条件 使其找到非支配前沿)
if q not in S[p]: # 保证当前p并未在S[p]中(即证明p支配q)
S[p].append(q) # 添加被p支配的集合S[p]
elif (values1[q] > values1[p] and values2[q] > values2[p]) or (
values1[q] >= values1[p] and values2[q] > values2[p]) or (
values1[q] > values1[p] and values2[q] >= values2[p]): # 如果函数1当前值p大于函数1其他值而且函数2当前值大于函数2其他值
# 或者 函数1当前值p不小于函数1其他值而且函数2当前值大于函数2其他值
# 或者 函数1当前值p大于函数1其他值而且函数2当前值不小于函数2其他值
# (判断条件 p受q支配)
n[p] = n[p] + 1 # 使其p被支配个数n[p]加1
elif cv[p]==0 and cv[q]>0: #当p是可行解,而q不可行时
if q not in S[p]: # 保证当前p并未在S[p]中(即证明p支配q)
S[p].append(q) # 添加被p支配的集合S[p]
elif cv[p]>0 and cv[q]==0: #当p时不可行解,而q是可行解时
n[p]=n[p]+1
if n[p] == 0: # 如果p不被其他群体支配
rank[p] = 0 # 则设置其非支配序为0
if p not in front[0]: # 并通过判断将其添加到(第一列)前沿序列Z1中
front[0].append(p)
print(front)
i = 0
while (front[i] != []): # 通过判断前一列序列是否为空(保证不为空) i = 0(即第二步)
Q = [] # 初始化另一个集Q
for p in front[i]: # 遍历当前列序列里面的每个个体
for q in S[p]: # 考察它所支配的个体集s[p]
n[q] = n[q] - 1 # 集合S[p]中的每个个体q的(被支配个数)n[q]减1(因为支配个体q已经加入到当前集front[i],即以不属于下面的序列)
if (n[q] == 0): # (注:在减1之前n[q]不存在为0的个数,以为在之前将n[q]=0的个体已经加入到front[0])
rank[q] = i + 1 # 如果当前个体不再受其他个体支配,设置其该集合相同的非支配序rank值
if q not in Q: # 通过判断将其加入到当前最优集Q
Q.append(q)
i = i + 1 # 继续下一序列集
front.append(Q) # 将其添加到前沿序列
# print(front)
del front[len(front) - 1] # 最后一个序列什么都没有添加元素,即(front[i]==0)循环结束,故删除最后一个空列表
return front # 返回快速非支配排序后的结果,rank为其所在二维列表中所在一维列表的下标
# [[6], [4], [11], [8, 17], [1], [5], [7], [2, 19], [13, 16], [18], [3], [0], [12], [14], [15], [9], [10]]
# 需要注意的是其返回的只是种群个体下标划分的列表集(非值,形式如上)
# 计算拥挤距离
def crowding_distance(values1, values2, front): # 注意:此处front是一维列表形式,每个层次序号
distance = [0 for i in range(0, len(front))] # 初始化该层个体距离集合,且初值为0
sorted1 = sort_by_values(front, values1[:]) # 返回函数1该层最小的索引(并设置好了无穷)
sorted2 = sort_by_values(front, values2[:]) # 返回函数2该层最小的索引(并设置好了无穷)
distance[0] = 4444444444444444 # 初始化(正无穷)
distance[len(front) - 1] = 4444444444444444 # 初始化(正无穷)
for k in range(1, len(front) - 1): # 求函数1的拥挤度
distance[k] = distance[k] + (values1[sorted1[k + 1]] - values2[sorted1[k - 1]]) / (max(values1) - min(values1))
for k in range(1, len(front) - 1): # 加上函数2的拥挤度
distance[k] = distance[k] + (values1[sorted2[k + 1]] - values2[sorted2[k - 1]]) / (max(values2) - min(values2))
return distance # 返回改层拥挤距离集
# 执行交叉
def crossover(a, b):
answer=[]
for i in range(len(a)):
r = random.random()
if r > 0.5: # 算术交叉(由两个个体的线性组合而产生两个新的个体,该操作对象一般由浮点数编码表示的个体)
answer.append(mutation((a[i] + b[i]) / 2,min_xi[i],max_xi[i]))
else:
answer.append(mutation((a[i] - b[i]) / 2,min_xi[i],max_xi[i]))
# return mutation((a - b) / 2)
return answer
# 执行变异算子
def mutation(solution,minx,maxx):
mutation_prob = random.random()
if mutation_prob < 1:
solution = minx + (maxx - minx) * random.random()
return solution
# 生成初始种群
def init(min_xi, max_xi, num):
i = 0
solution = [] # 存放结果种群数组,里面存放的每个元素格式为[x1,x2,x3……]
while (i < num):
x=[0]*len(min_xi)
#随机生成x值
for j in range(len(min_xi)):
x[j]=min_xi[j] + (max_xi[j] - min_xi[j]) * random.random()
#计算约束值
z1=0.0625*x[0]
z2=0.0625*x[1]
g1=0.00954*x[2]-z2
g2=0.0193*x[2]-z1
if(g1<0 and g2<0):
solution.append(x)
i+=1
return solution
# 主程序从这里开始
pop_size = 30
max_gen = 1000
# 初始化
min_xi = [1, 1, 10, 10]
max_xi = [99, 99, 200, 200]
solution=init(min_xi,max_xi,pop_size) #solution的结构为[[x1,x2,x3,x4],[x1,x2,x3,x4]]
print("solution:")
print(solution)
gen_no = 0
while (gen_no < max_gen): # 循环921代,即每次循环为一个繁殖
# 将产生的20个种群个体分别运用到function1 和function2
# 即function1_values和function2_values为不同函数的计算值列表
function1_values = [function1(solution[i][0],solution[i][1],solution[i][2],solution[i][3]) for i in range(0, pop_size)]
function2_values = [function2(solution[i][2],solution[i][3]) for i in range(0, pop_size)]
cv=[CV(solution[i]) for i in range(0,pop_size)]
# print(function2_values[:])
# 运行快速非支配排序法非支配排序解集合 (在python中使用列表切片[:]既可以复制原列表,复制后又不会改变原列表)
non_dominated_sorted_solution = fast_non_dominated_sort(function1_values[:], function2_values[:],cv)
print("第", gen_no, "代最优的点集是:") # 开始输出结果
for valuez in non_dominated_sorted_solution[0]: # 遍历最优解集合(存储的只是下标)
print([round(solution[valuez][0], 3),round(solution[valuez][1], 3),round(solution[valuez][2], 3),round(solution[valuez][3], 3)], end=" ") # round() 返回浮点数x的四舍五入值
print("\n")
print("第", gen_no, "代最优的解是:") # 开始输出结果
result=[]
print(len(non_dominated_sorted_solution[0]))
for valuez in non_dominated_sorted_solution[0]: # 遍历最优解集合(存储的只是下标)
print([function1_values[valuez],function2_values[valuez]],end=" ")
result.append([function1_values[valuez],function2_values[valuez]]) # round() 返回浮点数x的四舍五入值
print("\n")
# print(len(result))
crowding_distance_values = [] # 定义拥挤距离值
for i in range(0, len(non_dominated_sorted_solution)): # 遍历快速非支配排序法产生的分级结果集
crowding_distance_values.append(crowding_distance(function1_values[:], function2_values[:],
non_dominated_sorted_solution[i][
:])) # 计算拥挤距离 (高级用法[:]( ̄▽ ̄)~*)
# 求出每层的拥挤距离值并集中到crowding_distance_values
solution2 = solution[:] # (在python中使用列表切片[:]既可以复制原列表,复制后又不会改变原列表)
# 产生后代
while (len(solution2) != 2 * pop_size): # 使产生的后代后种群大小为2N
a1 = random.randint(0, pop_size - 1) # random.randint(a,b)
b1 = random.randint(0, pop_size - 1) # 随机产生[a,b]中的一个数
solution2.append(crossover(solution[a1], solution[b1])) # 通过交叉变异产生一个新的后代
# 将产生的2N个种群个体分别运用到function1 和function2
# 即function1_values2和function2_values2为不同函数的计算值列表
function1_values2 = [function1(solution2[i][0],solution2[i][1],solution2[i][2],solution2[i][3]) for i in range(0, 2 * pop_size)]
function2_values2 = [function2(solution2[i][2],solution2[i][3]) for i in range(0, 2 * pop_size)]
cv2=[CV(solution2[i]) for i in range(0,2*pop_size)]
non_dominated_sorted_solution2 = fast_non_dominated_sort(function1_values2[:], function2_values2[:],cv2) # 再次求快速非支配排序法
crowding_distance_values2 = []
for i in range(0, len(non_dominated_sorted_solution2)):
crowding_distance_values2.append(
crowding_distance(function1_values2[:], function2_values2[:], non_dominated_sorted_solution2[i][:]))
# 求出每层的拥挤距离值并集中到crowding_distance_values2
new_solution = [] # 初始化新解集
for i in range(0, len(non_dominated_sorted_solution2)): # 遍历拥挤距离集层
non_dominated_sorted_solution2_1 = [
index_of(non_dominated_sorted_solution2[i][j], non_dominated_sorted_solution2[i]) for j in
range(0, len(non_dominated_sorted_solution2[i]))] #
front22 = sort_by_values(non_dominated_sorted_solution2_1[:], crowding_distance_values2[i][:])
front = [non_dominated_sorted_solution2[i][front22[j]] for j in
range(0, len(non_dominated_sorted_solution2[i]))]
front.reverse() # 将前沿解集进行翻转
for value in front: # 遍历前沿解集
new_solution.append(value) # 添加到新的解集合
if (len(new_solution) == pop_size):
break
if (len(new_solution) == pop_size): # 保证新的种群个数仍然为N
break
solution = [[solution2[i][0],solution2[i][1],solution2[i][2],solution2[i][3]] for i in new_solution]
gen_no = gen_no + 1
f = open("k1.txt", "a")
f.writelines(str(result))
f.writelines('\n')
f.close()
# 绘制图形
function1 = [i * -1 for i in function1_values]
function2 = [j * -1 for j in function2_values]
plt.xlabel('Function 1', fontsize=10)
plt.ylabel('Function 2', fontsize=10)
plt.scatter(function1, function2)
plt.savefig('image1/20.jpg')
plt.show()结果图:
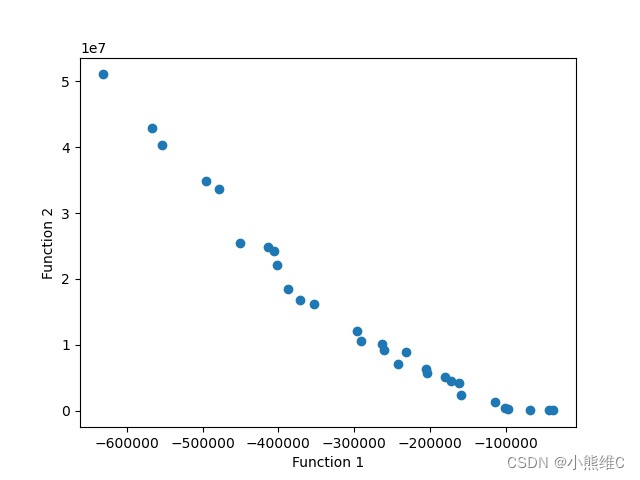
也测试了RCM25,结果图如下:

















 2626
2626











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









