







 八爪鱼是一款网页爬虫工具,可以不用编写代码快速实现网页数据的爬取。关于其基础操作,可以在其官网的使用教程http://www.bazhuayu.com/tutorialIndex 进行查看。其中主要针对其翻页和带有验证码的登录以及xpath操作进行阐述。特殊翻页数字翻页在制作采集规则时,页面没有“下一页”等翻页按钮,而是一排页码,如"1","2","3","4","5"……如何...
八爪鱼是一款网页爬虫工具,可以不用编写代码快速实现网页数据的爬取。关于其基础操作,可以在其官网的使用教程http://www.bazhuayu.com/tutorialIndex 进行查看。其中主要针对其翻页和带有验证码的登录以及xpath操作进行阐述。特殊翻页数字翻页在制作采集规则时,页面没有“下一页”等翻页按钮,而是一排页码,如"1","2","3","4","5"……如何...
八爪鱼是一款网页爬虫工具,可以不用编写代码快速实现网页数据的爬取。
关于其基础操作,可以在其官网的使用教程http://www.bazhuayu.com/tutorialIndex 进行查看。其中主要针对其翻页和带有验证码的登录以及xpath操作进行阐述。
特殊翻页
数字翻页
在制作采集规则时,页面没有“下一页”等翻页按钮,而是一排页码,如"1","2","3","4","5"……
如何通过数字翻页的进行处理?
解决思路:
找到一条xpath,使得在当前页(除未页外)始终能定位到下一页。
示例网址:http://stock.cngold.org/news/
常用函数:following-sibling::*
比如://span[@class=”page_curl”]/ following-sibling=a[1]
其中先找到数字页码1所在的位置为span,其class为page_url,这样就定位到了数字1所在的那个span。然后使用following-sibling找到其兄弟元素去定位下一页,找到其下一页也即是第2页所在的位置为a标签,由于后面所有同级元素的页码都是a标签,所以使用a[1]表示第1页后的第一个a标签。
“加载更多”的翻页形式
适用情况:
要采集的网页中,有“加载更多”或“再显示20条”等按钮,点击这些按钮之后需要采集的数据才会完全显示出来。
比如下列情况,需要点击“加载更多内容”,而且每点击一次多显示20条的数据:
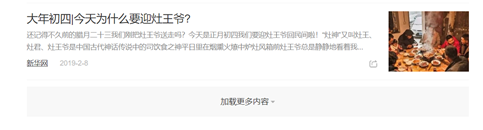
解决思路:
按照常规操作,创建翻页循环,然后将循环翻页步骤拖到循环-提取数据步骤前,让所有翻页完成之后,再进行循环提取数据步骤,不然会很多重复数据。
循环翻页的点击按钮一般是ajax加载,即点击翻页的高级选项需勾选ajax,并设置超时时间(时间长短根据数据加载快慢设置),不要勾选新标签。
比如,针对https://weixin.sogou.com/网页,常规的是先循环点击“加载更多内容”,比如下左图,如果这样执行采集数据之后,得到的将是前20条数据的循环采集。
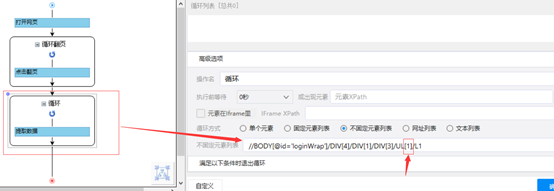
对于此种情况,我们需要将循环提取数据拖到循环翻页下面,如右图,这样就会先将所有的数据都加在出来,再一起执行数据的提取了。注意,有时候数据太多,它会无限制地执行加载数据,此时可以对翻页设置循环次数限制。另外,需改变循环提取数据的xpath如下图,否则只能提取前20条数据。


 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章
















 3万+
3万+











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









