







在CUDA 程序中获取GPU 设备属性
#include <memory>
#include <iostream>
#include <cuda_runtime.h>
int main()
{
int device_Count = 0;
cudaGetDeviceCount(&device_Count); // 一个函数返回支持CUDA 的数量。没有返回0。
if (device_Count == 0)
{
printf("没有支持CUDA 的设备\n");
}
else
{
printf("有 %d 个设备支持CUDA \n", device_Count);
}
}
通过查询 cudaDeviceProp 结构体来查找每个设备的相关信息,这个结构体返回所有设备属性,对于多个设备可以通过for 遍历所有设备属性。
通用设备信息
cudaDevicePorp 结构体提供了可以用来设别设备以及确定使用的版本信息属性。提供 name 属性,以字符串的形式返回设备的名称。 cudaDriverGetVersion ,cudaRuntimeGetVersion 这两个属性获得设备使用的CUDA Driver 和运行时引擎的版本。如果有多个设备,并希望使用具有最多流多处理器的那个,可以通过multiProcessorCount 属性判断,这个属性返回设备上的流多处理器的个数。还可以通过clockRate 属性获取GPU 的时钟速率。以 Khz 返回时钟速率。
#include <memory>
#include <iostream>
#include <cuda_runtime.h>
int main()
{
int device_Count = 0;
int device = 0;
int driver_Version=0;
cudaDeviceProp device_Property;
cudaGetDeviceProperties(&device_Property, device);
printf("\n Device %d: \" %s \" \n ", device, device_Property.name); // 设备型号
cudaDriverGetVersion(&driver_Version);
printf(" CUDA Driver Version %d.%d\n", driver_Version / 1000, (driver_Version % 100) / 10); // CUDA 版本
// 显存大小
printf(" Total amount of global memory : %.0f MB ( %llu bytes) \n", (float)device_Property.totalGlobalMem / 1048576.0f, (unsigned long long) device_Property.totalGlobalMem);
printf(" (%2d) Multiprocessors\n", device_Property.multiProcessorCount); // 最多含有多少多流处理器
printf(" GPU Max Clock rate :`在这里插入代码片` %.0f MHz (%0.2f GHz ) \n", device_Property.clockRate * 1e-3f, device_Property.clockRate * 1e-6f);
} // 时钟速率
内存相关属性
GPU 上的内存是分层的,有 L1 缓存, L2 缓存,全局内存,纹理内存和共享内存。cudaDeviceProp 提供了许多特性来帮助识别设备中可以用的内存。memoryClockRate and memoryBusWidth 提供显存频率和显存位宽。显存的读写速度是非常重要的,会影响正程序的速度。totalGlobalMem 返回设备可用的全局内存大小。totalConstMem 设备可用的总常量显存。sharedMemPerBlock 设备上每个块中最大可用共享内存大小。使用 regsPerBlock 可用识别每个块的可用寄存器总数。 I2CacheSize 识别 L2缓存大小。
#include <memory>
#include <iostream>
#include <cuda_runtime.h>
int main()
{
int device = 0;
cudaDeviceProp device_Property;
cudaGetDeviceProperties(&device_Property, device);
printf("Total amount of global memory : %.0f MB (%llu bytes) \n", (float)device_Property.totalGlobalMem / 1048576.0f, (unsigned long long ) device_Property.totalGlobalMem);
printf("Memory Clock rate :%.0f Mhz \n ", device_Property.memoryClockRate * 1e-3f);
printf("Memory Bus Width : %d-bit \n", device_Property.memoryBusWidth); // 显存频率和显存位宽
if (device_Property.l2CacheSize)
{
printf(" L2 Cache Size : %d bytes \n", device_Property.l2CacheSize);
}
printf("Total amout of constant memory : %lu bytes \n", device_Property.totalConstMem); // 总常量显存
printf("Total amount of shared memory per block : %lu bytes \n", device_Property.sharedMemPerBlock);
printf("Total number of registers available per block : %d\n", device_Property.regsPerBlock); //每个块的可用寄存器总数
}
显存相关属性
块和线程可以是多维的,所有最好知道每个维度可用并行启动多少线程和块。对于每个多处理器的线程数量和每个块的线程数量也有限制。可用通过 maxThreadsPerMultiProcessor and maxThreadsPerBlock 查看。这个在内核参数的配置中非常重要,如果启动的线程数超过了最大线程数量,程序就会崩溃。可用通过 maxThreadsDim 确定块中各个维度上的最大线程数量,同样,每个维度中每个网格的最大块可用通过 maxGridSize 来标识。返回一个具有三个值的数组,分别显示 x,y,z 维度中的最大值。
#include <memory>
#include <iostream>
#include <cuda_runtime.h>
int main()
{
int device = 0;
cudaDeviceProp device_Property;
cudaGetDeviceProperties(&device_Property, device);
printf("Maximum number of threads per multiprocessor : %d\n ", device_Property.maxThreadsPerMultiProcessor);
printf("Maximum number of threads per block : %d\n ", device_Property.maxThreadsPerBlock);
printf("Max dimension size of a thread block (x,y,z) : (%d, %d, %d) \n ",
device_Property.maxThreadsDim[0],
device_Property.maxThreadsDim[1],
device_Property.maxThreadsDim[2]);
printf("Max dimension size of a grid size (x,y,z) : ( %d, %d, %d) \n",
device_Property.maxGridSize[0],
device_Property.maxGridSize[1],
device_Property.maxGridSize[2]);
}

这些属性可用帮助我们从多个设备中选择合适的,如果应用程序中内核需要与CPU 紧密交互,你可能希望内核运行在与CPU 共享系统内存的集成GPU 上。
现在我们查看设备是否支持双精度浮点数操作。使用cudaDeviceProp 结构体中的两个属性来帮助识别设备是否支持双精度操作。如果major 大于1 且 minor 大于3 就支持双精度操作(见CUDA 文档)。cudaChooseDevice API 帮助选择具有特定属性的设备。此API 用于当前设备,用于确定是否包含这两个属性。如果包含这个属性就为应用程序选择该设备。如果系统中存在多个设备,应该进行一个循环,来遍历所有设备。
#include <memory>
#include <iostream>
#include <cuda_runtime.h>
int main()
{
int device = 0;
cudaDeviceProp device_Property;
cudaGetDeviceProperties(&device_Property, device);
cudaGetDevice(&device);
printf(" ID or device : %d \n", device);
memset(&device_Property, 0, sizeof(cudaDeviceProp));
device_Property.major = 1;
device_Property.minor = 3;
cudaChooseDevice(&device, &device_Property);
printf("ID of device which supports double precision id : %d \n", device);
cudaSetDevice(device);
}
CUDA 中的向量运算
利用GPU 的并行处理能力,执行向量或数组的操作。
两个向量加法程序
#include <stdio.h>
#include <iostream>
#define N 5
void cpuAdd(int* h_a, int* h_b, int *h_c)
{
int tid = 0;
while (tid < N)
{
h_c[tid] = h_a[tid] + h_b[tid]; // 这个tid 变量就用用来在CPU 上模仿 GPU 的写法。
tid += 1; // 在GPU 中 tid 代表特定的某个线程的ID 。
}
}
int main()
{
int h_a[N], h_b[N], h_c[N];
for (int i = 0; i < N; i++)
{
h_a[i] = 2 * i * i;
h_b[i] = i;
}
cpuAdd(h_a, h_b, h_c);
printf("CPU 上的向量加法。\n");
for (int i = 0; i < N; i++)
{
printf("the sum of %d element is %d + %d = %d\n", i, h_a[i], h_b[i], h_c[i]);
}
return 0;
}
#include <stdio.h>
#include <iostream>
#include <cuda.h>
#include<cuda_runtime.h>
#define N 5
__global__ void gpuAdd(int* d_a, int* d_b, int *d_c)
{
int tid = blockIdx.x; // 用当前块的ID 来初始变量,根据tid 变量每个线程将一对元素进行相加
if(tid<N) // 如果块的总数等于每个数组中元素的总数,所有的加法操作就并行完成了。
d_c[tid] = d_a[tid] + d_b[tid];
}
int main()
{
int h_a[N], h_b[N], h_c[N];
int* d_a, * d_b, * d_c;
cudaMalloc((void**)&d_a, N * sizeof(int));
cudaMalloc((void**)&d_b, N * sizeof(int));
cudaMalloc((void**)&d_c, N * sizeof(int));
for (int i = 0; i < N; i++)
{
h_a[i] = 2 * i * i;
h_b[i] = i;
}
cudaMemcpy(d_a, h_a, N * sizeof(int), cudaMemcpyHostToDevice);
cudaMemcpy(d_b, h_b, N * sizeof(int), cudaMemcpyHostToDevice);
gpuAdd<<<N,1>>>(d_a, d_b, d_c);
cudaMemcpy(h_c, d_c, N * sizeof(int), cudaMemcpyDeviceToHost); // 这些转来转去的不能省啊
printf("GPU 上的向量加法。\n");
for (int i = 0; i < N; i++)
{
printf("the sum of %d element is %d + %d = %d\n", i, h_a[i], h_b[i], h_c[i]);
}
cudaFree(d_a);
cudaFree(d_b);
cudaFree(d_c);
return 0;
}
基本的CUDA 程序模式,这里启动了N 个块。也就是同时启动了N个执行该内核代码的线程副本。每个线程可用通过blockIdx.x 内置变量来知道自己的ID 。然后每个线程通过ID 来索引数组,计算每对元素加法。这样多线程的并行计算明显 减少了数组整体的处理时间。
对比CPU 代码和 GPU 代码的延迟
在N 较小的情况下可能体现不出来这两的差距,如果N 足够大,就可以发现显著差距了。
#include <stdio.h>
#include <iostream>
#include <cuda.h>
#include<cuda_runtime.h>
#include <stdlib.h>
#include <time.h>
#include<iostream>
#define N 10000000
using namespace std;
__global__ void gpuAdd(int* d_a, int* d_b, int* d_c)
{
int tid = blockIdx.x; // 用当前块的ID 来初始变量,根据tid 变量每个线程将一对元素进行相加
if (tid < N) // 如果块的总数等于每个数组中元素的总数,所有的加法操作就并行完成了。
d_c[tid] = d_a[tid] + d_b[tid];
}
void cpuAdd(int* h_a, int* h_b, int* h_c)
{
int tid = 0;
while (tid < N)
{
h_c[tid] = h_a[tid] + h_b[tid]; // 这个tid 变量就用用来在CPU 上模仿 GPU 的写法。
tid += 1; // 在GPU 中 tid 代表特定的某个线程的ID 。
}
}
int main()
{
static int h_a[N], h_b[N], h_c[N]; // 研究了好久,对于占内存较大的数组从堆栈数据段挪到全局数据段
int* d_a, * d_b, * d_c; // 不然就会溢出,,。。。c 艹好难啊。。。
cudaMalloc((void**)&d_a, N * sizeof(int));
cudaMalloc((void**)&d_b, N * sizeof(int));
cudaMalloc((void**)&d_c, N * sizeof(int));
for (int i = 0; i < N; i++)
{
h_a[i] = i + 1;
h_b[i] = i;
}
cudaMemcpy(d_a, h_a, N * sizeof(int), cudaMemcpyHostToDevice);
cudaMemcpy(d_b, h_b, N * sizeof(int), cudaMemcpyHostToDevice);
clock_t start_h = clock();
cpuAdd(h_a, h_b, h_c);
clock_t end_h = clock();
double time_h = (double)(end_h - start_h) / CLOCKS_PER_SEC;
clock_t start_d = clock();
gpuAdd <<<5, 200 >>> (d_a, d_b, d_c);
cudaThreadSynchronize();
clock_t end_d = clock();
double time_d = (double)(end_d - start_d) / CLOCKS_PER_SEC;
printf("GPU 上的向量加法。\n");
printf("Device time %f seconds \nHost time %f seconds\n", time_d, time_h);
cudaFree(d_a);
cudaFree(d_b);
cudaFree(d_c);
return 0;
}
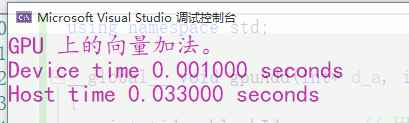
可以看到 GPU 上就是快啊。。
对向量的每个元素进行平方
#include<stdio.h>
#include<iostream>
#include<cuda.h>
#include<cuda_runtime.h>
#define N 5
__global__ void gpuSquare(float* d_in, float* d_out)
{
int tid = threadIdx.x; float temp = d_in[tid];
d_out[tid] = temp * temp;
}
int main()
{
float h_in[N], h_out[N];
//Defining Pointers for device
float* d_in, * d_out;
cudaMalloc((void**)&d_in, N * sizeof(float));
cudaMalloc((void**)&d_out, N * sizeof(float));
for (int i = 0; i < N; i++) {
h_in[i] = i;
}
//Copy Array from host to device
cudaMemcpy(d_in, h_in, N * sizeof(float), cudaMemcpyHostToDevice);
// 启动了 1 个具有N 个线程的块。每个块的最大线程不能超过 1024,所以要根据实际来选择。
gpuSquare <<<1, N >>> (d_in, d_out);
//Coping result back to host from device memory
cudaMemcpy(h_out, d_out, N * sizeof(float), cudaMemcpyDeviceToHost);
//Printing result on console
printf("Square of Number on GPU \n");
for (int i = 0; i < N; i++) {
printf("The square of %f is %f\n", h_in[i], h_out[i]);
}
//Free up memory
cudaFree(d_in);
cudaFree(d_out);
return 0;
}
并行通信模式
多个线程并行执行时,会遵循一定的通信模式,指导再显存哪里输入,哪里输出,
映射
每个线程或任务读取单一输入,产出一个输出,基本啥是一对一的操作。代码模式 d_out[i] = d_in[i] *2
收集
多个输入,一个输出,并保存再单一位置。代码模式:out[i] = (in[i-1] + in[i] + in[i+3]) /3
分散式
单一输入,多个输出out[i-1] += 2*in[i] and out[i+1] += 3*in[i]
蒙版
这个再图像处理中很有用,例如你想用一个 3*3 的滤波窗口。这个的代码模式和收集很像
转置
就是矩阵的转置 out[+j*128] = in[j+i*128]














 2388
2388











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









