







前言
参考资料:
高升博客
《CUDA C编程权威指南》
以及 CUDA官方文档
CUDA编程:基础与实践 樊哲勇
文章、讲解视频同步更新公众《AI知识物语》,B站:出门吃三碗饭
1:内存组织介绍
现代计算机中的内存往往存在一种组织结构(hierarchy)。在这种结构中,含有多种类 型的内存,每种内存分别具有不同的容量和延迟(latency,可以理解为处理器等待内存数据的时间)。一般来说,延迟低(速度高)的内存容量小,延迟高(速度低)的内存容量大。

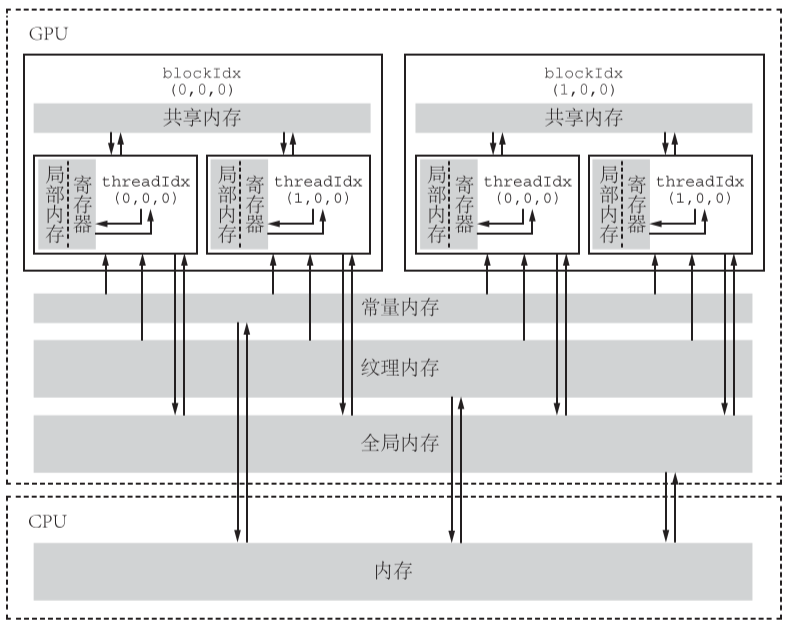
2:CUDA 不同类型的内存
2.1全局内存:
(1)其含义是核函数中的所有线程都能够访问其中的数 据,和C++中的“全局变量”不是一回事。我们已经用过这种内存,在数组相加的例子中, 指针 d_x、d_y 和 d_z 都是指向全局内存的。全局内存由于没有存放在GPU的芯片上,因此具有较高的延迟和较低的访问速度。
(2)全局内存的主要作用是为核函数提供数据,并在主机与设备及设备与设备之间传递数 据。首先,我们用cudaMalloc 函数为全局内存变量分配设备内存。然后,可以直接在核函数中访问分配的内存,改变其中的数据值。
(3)全局内存对整个网格的所有线程可见。也就是说,一个网格的所有线程都可以访问(读 或写)传入核函数的设备指针所指向的全局内存中的全部数据。
(4)全局内存的生命周期(lifetime)不是由核函数决定的,而是由主机端决定的。在数组 相加的例子中,由指针 d_x、d_y 和 d_z 所指向的全局内存缓冲区的生命周期就是从主机端用 cudaMalloc 对它们分配内存开始,到主机端用 cudaFree 释放它们的内存结束。
2.2静态全局内存:
静态全局内存变量由以下方式在任何函数外部定义:
__device__ T x; // 单个变量
__device__ T y[N]; // 固定长度的数组
其中,修饰符 device 说明该变量是设备中的变量,而不是主机中的变量;T 是变量的 类型;N是一个整型常数。
在核函数中,可直接对静态全局内存变量进行访问,并不需要将它们以参数的形式传给核 函数。不可在主机函数中直接访问静态全局内存变量,但可以用 cudaMemcpyToSymbol 函
数和 cudaMemcpyFromSymbol 函数在静态全局内存与主机内存之间传输数据。
2.3常量内存:
常量内存(constant memory)是有常量缓存的全局内存,数量有限,一共仅有 64 KB。 它的可见范围和生命周期与全局内存一样。不同的是,常量内存仅可读、不可写。由于有 缓存,常量内存的访问速度比全局内存高,但得到高访问速度的前提是一个线程束中的线程(一个线程块中相邻的 32 个线程)要读取相同的常量内存数据。
一个使用常量内存的方法是在核函数外面用 constant 定义变量,并用前面介绍 的CUDA运行时API函数cudaMemcpyToSymbol将数据从主机端复制到设备的常量内存后供核函数使用。
在数组相加的例子中,核函数的参数 const int N 就是在主机端定义的变量,并通过传值的方式传送给核函数中的线程 使用。在核函数中的代码段 if (n < N) 中,这个参数 N 就被每一个线程使用了。所以, 核函数中的每一个线程都知道该变量的值,而且对它的访问比对全局内存的访问要快。除给核函数传递单个的变量外,还可以传递结构体,同样也是使用常量内存。
2.4纹理内存和表面内存
纹理内存(texture memory)和表面内存(surface memory)类似于常量内存,也是一 种具有缓存的全局内存,有相同的可见范围和生命周期,而且一般仅可读(表面内存也可写)。不同的是,纹理内存和表面内存容量更大,而且使用方式和常量内存也不一样。
2.5寄存器
在核函数中定义的不加任何限定符的变量一般来说就存放于寄存器(register)中。 核函数中定义的不加任何限定符的数组有可能存放于寄存器中,但也有可能存放于 局部内存中。另外,以前提到过的各种内建变量,如 gridDim、blockDim、blockIdx、 threadIdx 及 warpSize 都保存在特殊的寄存器中。在核函数中访问这些内建变量是很高效的。
const int n = blockDim.x * blockIdx.x + threadIdx.x;
这里的 n 就是一个寄存器变量。寄存器可读可写。上述语句的作用就是定义一个寄存器变 量 n 并将赋值号右边计算出来的值赋给它(写入)。在稍后的语句
z[n] = x[n] + y[n];
中,寄存器变量 n 的值被使用(读出)。
寄存器变量仅仅被一个线程可见。也就是说,每一个线程都有一个变量 n 的副本。虽 然在核函数的代码中用了这同一个变量名,但是不同的线程中该寄存器变量的值是可以不
同的。
2.6局部内存
局部内存和寄存器几乎一 样。核函数中定义的不加任何限定符的变量有可能在寄存器中,也有可能在局部内存中。寄存器中放不下的变量,以及索引值不能在编译时就确定的数组,都有可能放在局部内存中。
这种判断是由编译器自动做的。对于数组相加例子中的变量 n 来说,作者可以肯定它在寄 存器中,而不是局部内存中,因为核函数所用寄存器数量还远远没有达到上限。
2.7共享内存
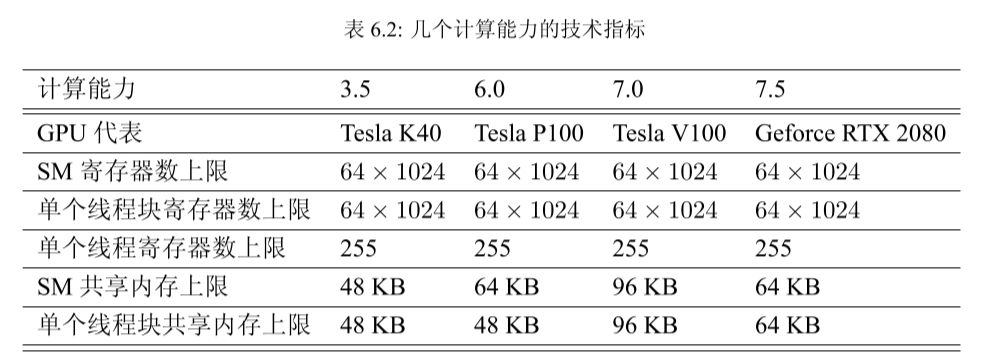
共享内存和寄存器类似,存在于芯片 上,具有仅次于寄存器的读写速度,数量也有限。表 6.2 列出了与几个计算能力对应的共享 内存数量指标。
不同于寄存器的是,共享内存对整个线程块可见,其生命周期也与整个线程块一致。也就是说,每个线程块拥有一个共享内存变量的副本。共享内存变量的值在不同的线程块中 可以不同。一个线程块中的所有线程都可以访问该线程块的共享内存变量副本,但是不能访问其他线程块的共享内存变量副本。
2.8 L1 、L2缓存
从费米架构开始,有了SM层次的L1缓存(一级缓存)和设备(一个设备有多个SM) 层次的 L2 缓存(二级缓存)。它们主要用来缓存全局内存和局部内存的访问,减少延迟。
3:流多处理器SM
一个 GPU 是由多个SM构成的。一个SM包含如下资源:
• 一定数量的寄存器。
• 一定数量的共享内存。
• 常量内存的缓存。
• 纹理和表面内存的缓存。
• L1 缓存。
• 两个(计算能力 6.0)或 4 个(其他计算能力)线程束调度器(warp scheduler),用于 在不同线程的上下文之间迅速地切换,以及为准备就绪的线程束发出执行指令。
• 执行核心,包括:
– 若干整型数运算的核心(INT32)。
– 若干单精度浮点数运算的核心(FP32)。
– 若干双精度浮点数运算的核心(FP64)。
– 若干单精度浮点数超越函数(transcendental functions)的特殊函数单元(Special Function Units,SFUs)。
– 若干混合精度的张量核心(tensor cores,由伏特架构引入,适用于机器学习中的
低精度矩阵计算,本书不讨论)。
SM占有率
因为一个 SM 中的各种计算资源是有限的,那么有些情况下一个 SM 中驻留的线程数 目就有可能达不到理想的最大值。此时,我们说该SM的占有率小于 100%。获得 100%的 占有率并不是获得高性能的必要或充分条件,但一般来说,要尽量让 SM 的占有率不小于某个值,比如 25%,才有可能获得较高的性能。
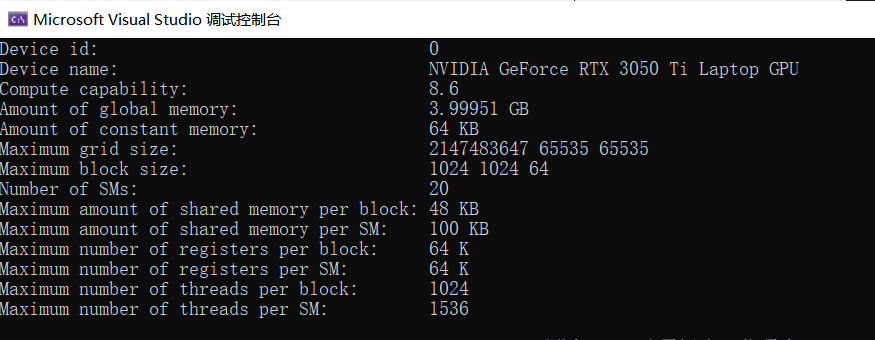
4:用CUDA运行时 API 函数查询设备
#include <stdio.h>
#define CHECK(call) \
do \
{ \
const cudaError_t error_code = call; \
if (error_code != cudaSuccess) \
{ \
printf("CUDA Error:\n"); \
printf(" File: %s\n", __FILE__); \
printf(" Line: %d\n", __LINE__); \
printf(" Error code: %d\n", error_code); \
printf(" Error text: %s\n", \
cudaGetErrorString(error_code)); \
exit(1); \
} \
} while (0)
int main(int argc, char* argv[])
{
int device_id = 0;
if (argc > 1) device_id = atoi(argv[1]);
CHECK(cudaSetDevice(device_id));
cudaDeviceProp prop;
CHECK(cudaGetDeviceProperties(&prop, device_id));
printf("Device id: %d\n",
device_id);
printf("Device name: %s\n",
prop.name);
printf("Compute capability: %d.%d\n",
prop.major, prop.minor);
printf("Amount of global memory: %g GB\n",
prop.totalGlobalMem / (1024.0 * 1024 * 1024));
printf("Amount of constant memory: %g KB\n",
prop.totalConstMem / 1024.0);
printf("Maximum grid size: %d %d %d\n",
prop.maxGridSize[0],
prop.maxGridSize[1], prop.maxGridSize[2]);
printf("Maximum block size: %d %d %d\n",
prop.maxThreadsDim[0], prop.maxThreadsDim[1],
prop.maxThreadsDim[2]);
printf("Number of SMs: %d\n",
prop.multiProcessorCount);
printf("Maximum amount of shared memory per block: %g KB\n",
prop.sharedMemPerBlock / 1024.0);
printf("Maximum amount of shared memory per SM: %g KB\n",
prop.sharedMemPerMultiprocessor / 1024.0);
printf("Maximum number of registers per block: %d K\n",
prop.regsPerBlock / 1024);
printf("Maximum number of registers per SM: %d K\n",
prop.regsPerMultiprocessor / 1024);
printf("Maximum number of threads per block: %d\n",
prop.maxThreadsPerBlock);
printf("Maximum number of threads per SM: %d\n",
prop.maxThreadsPerMultiProcessor);
return 0;
}















 1086
1086











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









