







目录
一:RocketMq 整体文件存储介绍
存储⽂件主要分为三个部分:
CommitLog:存储消息的元数据。所有消息都会顺序存⼊到CommitLog⽂件当中。CommitLog由多个⽂件组成,每个⽂件固定⼤⼩1G。以第⼀条消 息的偏移量为⽂件名。
ConsumerQueue:存储消息在CommitLog的索引。⼀个MessageQueue⼀个⽂件,记录当前MessageQueue被哪些消费者组消费到了哪⼀条CommitLog。
IndexFile:为了消息查询提供了⼀种通过key或时间区间来查询消息的⽅法,这种通过IndexFile来查找消息的⽅法不影响发送与消费消息的主流程。
这篇文章主要介绍CommitLog的研究,以rocketmq5.3.0版本作为研究。
二:CommitLog 的文件结构
整体的消息存储结构,如下图:
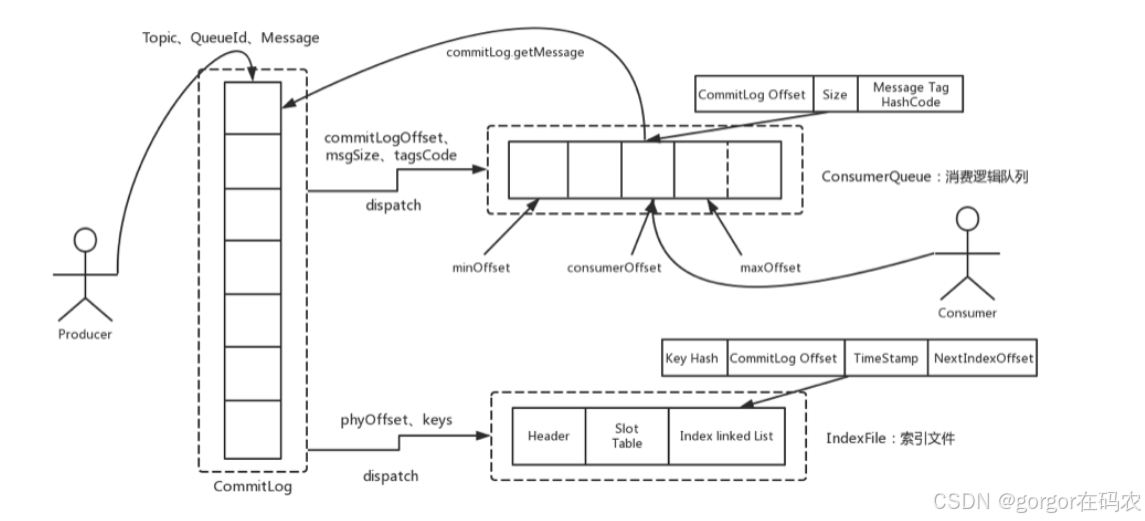
CommitLog 的文件格式:

CommitLog 消息条目格式说明:
消息按以下字段顺序写入字节缓冲区(byteBuf),最终持久化到 CommitLog 文件:
| 字段名 | 长度(字节) | 说明 |
|---|---|---|
| TOTAL_SIZE | 4 | 消息总长度(从 MAGIC_CODE 到 CRC32 的总字节数) |
| MAGIC_CODE | 4 | 魔数(标识消息版本,例如 0xAABBCCDD 或更高版本) |
| BODY_CRC | 4 | 消息体的 CRC32 校验码,用于校验消息体完整性 |
| QUEUE_ID | 4 | 消息所属的队列 ID(Queue ID),用于逻辑队列分片 |
| FLAG | 4 | 消息标志位(用户自定义,用于业务标记) |
| QUEUEOFFSET | 8 | 消息在消费队列(ConsumeQueue)中的逻辑偏移量 |
| PHYSICAL_OFFSET | 8 | 消息在 CommitLog 中的物理偏移量(初始为 0,持久化后更新为实际值) |
| SYS_FLAG | 4 | 系统标志位(表示消息特性,如压缩、事务、批量等) |
| BORN_TIMESTAMP | 8 | 消息生产时间戳(Producer 生成消息的时间) |
| BORNHOST | 8 | 生产者地址(4 字节 IP + 4 字节 Port,如 192.168.1.1:8888) |
| STORE_TIMESTAMP | 8 | 消息存储到 Broker 的时间戳 |
| STOREHOSTADDRESS | 8 | Broker 地址(4 字节 IP + 4 字节 Port,如 10.0.0.1:10911) |
| RECONSUMETIMES | 4 | 消息重试消费次数(正常消息为 0,重试消息递增) |
| PREPARED_TRANSACTION_OFFSET | 8 | 事务消息的预提交偏移量(非事务消息为 0) |
| BODY | 变长 | 消息内容(实际数据或压缩后的数据) |
| TOPIC | 变长 | Topic 名称(长度由 topicLength 决定,支持短或长格式) |
| PROPERTIES | 变长 | 消息属性(键值对,格式为 key1=value1\0key2=value2...) |
| CRC32 | 4 | 校验码(覆盖从 MAGIC_CODE 到 PROPERTIES 的所有字段) |
关键字段说明
1. MAGIC_CODE(魔数)
-
作用:标识消息格式版本,不同版本可能扩展字段或调整编码方式。
-
5.3.0 版本:
-
MessageVersion.V1:魔数为0xAABBCCDD。 -
MessageVersion.V2:魔数为0xAABBCCDE(可能支持更长的 Topic 或属性)。
-
2. QUEUEOFFSET 与 PHYSICAL_OFFSET
-
QUEUEOFFSET:消息在 ConsumeQueue 中的逻辑偏移量(由 Broker 分配),用于消费队列的索引构建。
-
PHYSICAL_OFFSET:消息在 CommitLog 中的物理偏移量,初始写入时为 0,持久化到磁盘后更新为实际值(全局唯一)。
3. SYS_FLAG(系统标志位)
-
位运算标识消息特性:
int sysFlag = message.getSysFlag(); // 示例: // 第 0 位:是否压缩(1 << 0) // 第 1 位:是否为批量消息(1 << 1) // 第 2 位:是否为事务消息(1 << 2) // 第 3 位:是否为重试消息(1 << 3)
4. TOPIC 格式
-
版本差异:
-
V1:Topic 长度用 1 字节 表示(最大 255 字符)。
-
V2:Topic 长度用 2 字节 表示(最大 65535 字符)。
if (MessageVersion.MESSAGE_VERSION_V2.equals(msgInner.getVersion())) { this.byteBuf.writeShort((short) topicLength); // 2 字节 } else { this.byteBuf.writeByte((byte) topicLength); // 1 字节 } -
5. PROPERTIES(属性)
-
编码规则:键值对以
\0分隔,例如TAGS=TagA\0KEYS=Order_123。 -
长度限制:属性总长度由
propertiesLength(2 字节)指定,最大 32767 字节。
6. CRC32 校验
-
计算范围:从
MAGIC_CODE到PROPERTIES的所有字段(不含TOTAL_SIZE和CRC32自身)。 -
写入方式:先预留 4 字节空间,最后回填计算结果:
// 预留 CRC32 位置
this.byteBuf.writerIndex(this.byteBuf.writerIndex() + crc32ReservedLength);
// 后续计算并回填三:CommitLog 写入和查询流程
1. CommitLog 写入流程图
+---------------------+
| Producer 发送消息 |
+---------------------+
|
v
+---------------------+
| Broker 接收消息 |
| - 校验消息合法性 |
| (Topic 是否存在等) |
+---------------------+
|
v
+---------------------+
| 分配全局物理偏移量 |
| (PHYSICAL_OFFSET) |
+---------------------+
|
v
+---------------------+
| 顺序写入 CommitLog 文件 |
| - 若文件满(默认1GB) |
| 滚动创建新文件 |
+---------------------+
|
v
+---------------------+
| 同步更新索引文件 |
| 1. ConsumeQueue | → 记录逻辑偏移量 → 物理偏移量映射
| 2. IndexFile | → 记录 Key/时间 → 物理偏移量映射
+---------------------+
|
v
+---------------------+
| 返回写入成功响应 |
| (包含消息ID) |
+---------------------+CommitLog 文件初始化和替换:
-
编码:org.apache.rocketmq.store.MessageExtEncoder#encode(MessageExtBrokerInner)
-
替换:org.apache.rocketmq.store.CommitLog.DefaultAppendMessageCallback#doAppend(long, java.nio.ByteBuffer, int, org.apache.rocketmq.common.message.MessageExtBrokerInner, org.apache.rocketmq.store.PutMessageContext)
QUEUEOFFSET 字段获取和累加:
- 获取: org.apache.rocketmq.store.DefaultMessageStore#assignOffset
- 累加:org.apache.rocketmq.store.DefaultMessageStore#increaseOffset
public CompletableFuture<PutMessageResult> asyncPutMessage(final MessageExtBrokerInner msg) {
........
........
//锁对列
topicQueueLock.lock(topicQueueKey);
try {
boolean needAssignOffset = true;
if (defaultMessageStore.getMessageStoreConfig().isDuplicationEnable()
&& defaultMessageStore.getMessageStoreConfig().getBrokerRole() != BrokerRole.SLAVE) {
needAssignOffset = false;
}
if (needAssignOffset) {
//QUEUEOFFSET 获取
defaultMessageStore.assignOffset(msg);
}
.......
.......
// Increase queue offset when messages are successfully written
// QUEUEOFFSET 累加
if (AppendMessageStatus.PUT_OK.equals(result.getStatus())) {
this.defaultMessageStore.increaseOffset(msg, getMessageNum(msg));
}
.......
.......旧 CommitLog 文件的清理
RocketMQ 通过 后台线程 定期清理过期的 CommitLog 文件,释放磁盘空间。清理策略由以下参数控制:
(1) 消息保留时间
-
参数:
fileReservedTime(默认 72 小时)。 -
规则:删除早于当前时间减去保留时间的 CommitLog 文件。
-
示例:
若当前时间为 2023-10-01 12:00:00,保留时间为 72 小时,则删除所有在 2023-09-28 12:00:00 之前写入的 CommitLog 文件。
(2) 磁盘水位控制
-
参数:
diskMaxUsedSpaceRatio(默认 85%)。 -
规则:若磁盘使用率超过阈值,强制删除最旧的 CommitLog 文件,直至低于阈值。
(3) 手动清理
-
命令:通过 RocketMQ 提供的
cleanUnusedTopic命令或直接删除物理文件(需谨慎操作)。
文件的清理代码⼊⼝: DefaultMessageStore.addScheduleTask -> DefaultMessageStore.this.cleanFilesPeriodically() 和
DefaultMessageStore.this.cleanQueueFilesPeriodically()
在这个⽅法中会启动两个线程,cleanCommitLogService⽤来删除过期的CommitLog⽂件,cleanConsumeQueueService⽤来删除过期的ConsumeQueue和IndexFile⽂件。
在删除CommitLog⽂件时,Broker会启动后台线程,每60秒,检查CommitLog、ConsumeQueue⽂件。然后对超过72⼩时的数据进⾏删除。也就是说,默认 情况下, RocketMQ只会保存3天内的数据。这个时间可以通过fileReservedTime来配置。
触发过期⽂件删除时,有两个检查的纬度,⼀个是,是否到了触发删除的时间,也就是broker.conf⾥配置的deleteWhen属性。另外还会检查磁盘利⽤率,达到阈值也会触发过期⽂件删除。这个阈值默认是72%,可以在broker.conf⽂件当中定制。但是最⼤值为95,最⼩值为10。
然后在删除ConsumeQueue和IndexFile⽂件时,会去检查CommitLog当前的最⼩Offset,然后在删除时进⾏对⻬。
需要注意的是,RocketMQ在删除过期CommitLog⽂件时,并不检查消息是否被消费过。 所以如果有消息⻓期没有被消费,是有可能直接被删除掉,造成消息丢失的。
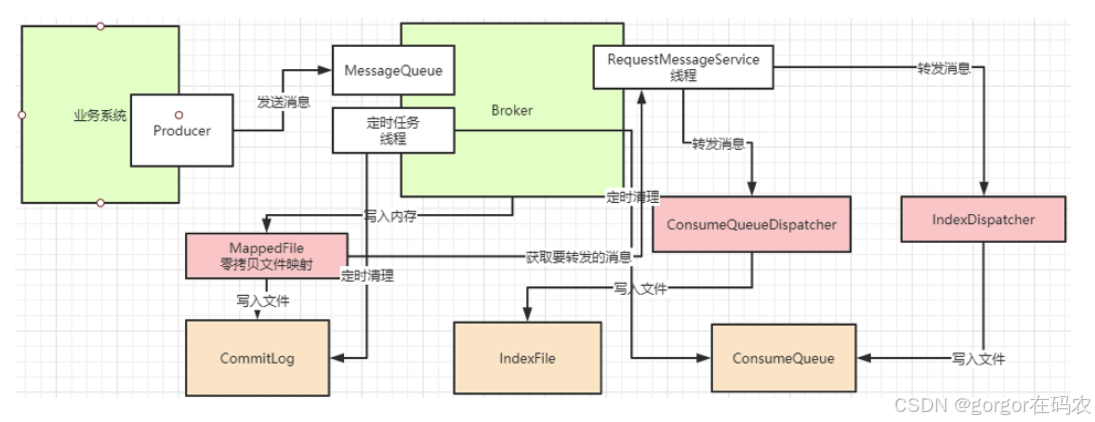
2. CommitLog 查询流程图
+---------------------+
| Consumer 拉取消息 |
| - Topic, QueueId |
| - 起始逻辑偏移量 |
+---------------------+
|
v
+---------------------+
| 查询 ConsumeQueue |
| - 根据逻辑偏移量计算位置 |
| (文件序号 = 偏移量 / 30万) |
+---------------------+
|
v
+---------------------+
| 读取 ConsumeQueue 条目 |
| - 获取物理偏移量 |
| - 消息大小 |
| - Tag 哈希值 |
+---------------------+
|
v
+---------------------+
| 根据物理偏移量定位 CommitLog |
| - 计算文件位置 |
| (文件序号 = 物理偏移量 / 1GB) |
+---------------------+
|
v
+---------------------+
| 从 CommitLog 读取消息体 |
| - 校验 CRC32 |
| - 解析消息属性 |
+---------------------+
|
v
+---------------------+
| 返回消息给 Consumer |
+---------------------+关键步骤说明:
-
消费者拉取请求
-
指定 Topic、QueueId 和起始逻辑偏移量(如
QUEUEOFFSET=1000)。
-
-
ConsumeQueue 查询
-
根据逻辑偏移量计算 ConsumeQueue 文件位置(如
文件序号 = 1000 / 300,000)。 -
读取条目,获取物理偏移量(如
PHYSICAL_OFFSET=1024)、消息大小和 Tag 哈希值。
-
-
CommitLog 定位
-
根据物理偏移量找到对应的 CommitLog 文件(如
00000000000000000000)。
-
-
读取消息内容
-
从 CommitLog 文件读取消息体,校验 CRC32 和完整性。
-
解析消息属性(如 Key、Tag、生产时间等)。
-
-
返回消息
-
将消息内容封装后返回给消费者。
-
关键设计优势
-
写入高性能
-
顺序写:所有消息追加到 CommitLog 末尾,避免随机 I/O。
-
内存映射(MMAP):通过
MappedByteBuffer加速文件写入。 -
批量刷盘:异步或同步刷盘策略平衡性能与可靠性。
-
-
查询高效性
-
逻辑偏移量映射:ConsumeQueue 提供 O(1) 时间复杂度的物理偏移量定位。
-
索引分离:ConsumeQueue 和 IndexFile 独立于 CommitLog,避免读写竞争。
-
-
故障恢复
-
文件滚动:单个文件大小可控,损坏时仅影响部分数据。
-
Reput 机制:通过
reputFromOffset重新构建索引,保障一致性。
-
四: ⽂件同步刷盘与异步刷盘
org.apache.rocketmq.store.CommitLog下的GroupCommitService线程的run⽅法 @Override
public CompletableFuture<PutMessageStatus> handleDiskFlush(AppendMessageResult result, MessageExt messageExt) {
// Synchronization flush 同步刷盘
if (FlushDiskType.SYNC_FLUSH == CommitLog.this.defaultMessageStore.getMessageStoreConfig().getFlushDiskType()) {
final GroupCommitService service = (GroupCommitService) this.flushCommitLogService;
if (messageExt.isWaitStoreMsgOK()) {//构建request的时候从配置⽂件中读取了刷盘超时时间,默认5秒。
GroupCommitRequest request = new GroupCommitRequest(result.getWroteOffset() + result.getWroteBytes(),
CommitLog.this.defaultMessageStore.getMessageStoreConfig().getSyncFlushTimeout());
flushDiskWatcher.add(request);//这⾥只是监控刷盘是否超时。
service.putRequest(request);//实际进⾏刷盘,刷盘操作先排队,再执⾏。
return request.future();
} else {
service.wakeup();
return CompletableFuture.completedFuture(PutMessageStatus.PUT_OK);
}
}
// Asynchronous flush
else {
if (!CommitLog.this.defaultMessageStore.isTransientStorePoolEnable()) {//默认false
flushCommitLogService.wakeup();
} else {
commitRealTimeService.wakeup();
}
return CompletableFuture.completedFuture(PutMessageStatus.PUT_OK);
}
}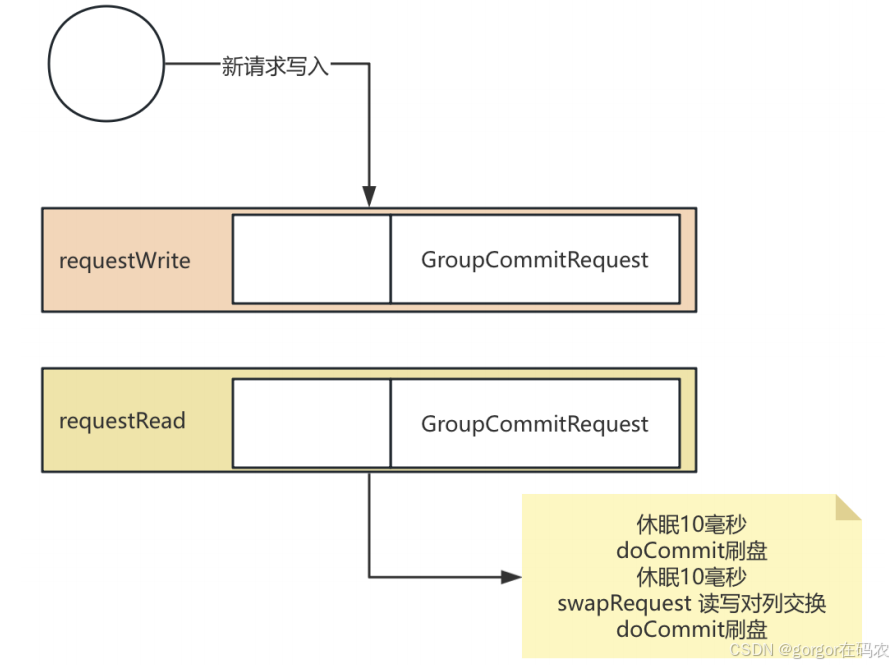
- 传统⼋股⽂会说同步刷盘可以保证消息安全。因为消息尽快写到了磁盘当中,断电就不会丢失。但是,实际情况是,RocketMQ的同步刷盘在后台任务中同 样是要休眠的,意味着,消息写⼊PageCache缓存再到写⼊磁盘,这中间依然是会有时间差的。这意味着同样会有断电丢失的可能。那为什么普遍都认为配置同步刷盘就可以保证消息安全呢?
- 从RocketMQ中可以看到,对于刷盘操作,并不是简单的想怎么调⽤就怎么调⽤。当调⽤刷盘操作过于频繁时,是需要进⾏优化的。那么,是不是可以回顾下Kafka中的刷盘频率是怎么配置的?刷盘间隔时间log.flush.interval.ms可以设置成1吗?
this.commitRealTimeService = new CommitLog.CommitRealTimeService(); //获取配置的刷盘间隔时间。默认200毫秒
int interval = CommitLog.this.defaultMessageStore.getMessageStoreConfig().getCommitIntervalCommitLog();
try{
//主要是提交commitWhere参数
boolean result = CommitLog.this.mappedFileQueue.commit(commitDataLeastPages);
//waitForRunning会阻塞线程,wakeup后会继续执⾏线程
CommitLog.this.flushManager.wakeUpFlush();
//休眠⼀次间隔时间
this.waitForRunning(interval);
} catch(){
}
//提交失败,重试,最多⼗次。
boolean result = false;
for (int i = 0; i < RETRY_TIMES_OVER && !result; i++) {
result = CommitLog.this.mappedFileQueue.commit(0);
CommitLog.log.info(this.getServiceName() + " service shutdown, retry " + (i + 1) + " times " + (result ? "OK" : "Not OK"));
} 

















 1116
1116

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











