







前言
这周更晚了一天,这周的内容可能相对于前些章来说会稍微繁琐一些,但是依然还是干货满满,相信追剧到这里的博友,都是志同道合的老友了,这章主要进阶一波,深入理解一下rocketMQ的一些原理知识,废话不多说,开干!
1.首先解答前期铺垫的pull和push两种消费模式的区别
之前的章节中有做过一个铺垫,这里就不多提了,简单的来讲,push和pull本质上消费模式是一样的,都是消费者机器主动发送请求到broker机器去拉取一批消息下来,那么对于这两种消费模式,应该选择哪种消费模式呢?区别在哪里的?
1.1:push消费模式:push消费模式底层也是基于消费者主动拉取的模式来实现的,只不过名字叫做push而已,意思就是broker会尽可能实时将最新的消息交给消费者机器来进行处理,push的时效性会更好。
1.2:一般在使用rocketMQ的时候,消费模式都是基于push模式来做的,因为pull模式的代码更加复杂和繁琐,而且push模式底层就是基于消息拉取的方式来做的,只不过时效性更好而已。
说白了,选择push就完事了,简单的分析一下push的实现原理和机制:
为什么push的实时性好呢?
1.3:push消费模式机制原理:当消费者发送请求到broker去拉取消息的时候,如果有新的消息,那么就会立马返回一批消息到消费机器上去处理,处理完之后会立刻接着发送请求到broker机器上去拉取下一批消息==充分的体现了消息消费的时效性;
1.4:push的两种机制分析一下:长轮询和请求挂起
请求发送到broker,结果发现没有新的消息处理,就会让请求线程挂起,默认挂起的时间是15秒,然后这个期间会有后台线程每隔一会去检查一下是否有新的消息,如果在这个挂起的过程中,如果有新的消息到达,会自动唤醒挂起的线程,然后将消息返回;是否清晰的解答了心中的small疑惑呢
2.producer生产者的工作原理(看完就理解了,没这么难)
2.1:在学习的时候,最期待的就是原理或者是底层源码刨析,但是最爱的也是源码刨析,知道了是什么种子,才知道这种子适合什么样的“环境”,什么时候开花结果和凋谢,说白了,这不就是我们经常提起的生命周期么?
2.2:想知道producer生产者的工作原理,首先要知道一个就是**messagequeue是什么?**
· 看过前些文章的朋友都知道topic就是一个数据模型,例如一直提起的order_topic类似,实际上简单讲就是一个数组或者是集合,这个messagequeue就是数据分片,数据分片可能听起来比较复杂,知道topic再来理解messagequeue数据分片就很简单----概念:分布式数据存储----也就是一个topic在发送到broker的时候,是可以指定分片成为几个messagequeue的,假设现在有4台master broker机器,那么就可以指定topic数据为4,例如一个topic中有1万条数据,那么均摊下来就是每台机器2500条数据,这样就完成分布式的存储,相信看到这里,很多好友已经理解了messagequeue是什么,至少有个基础的概念,也大致的明白了topic、messagequeue、broker这三者之间的关系,为了更方便的理解,
贴个图:【topic、messagequeue、broker三者之间的关系】

2.1:生产者发送消息的时候写入那个messagequeue?
之前的一些文章nameserver的概念和重要性都已经说到和提到过,这里就不过多的冗余分享了,生产者在发送消息的时候,会跟nameServer进行通信获取topic的路由数据,所以生产者从nameServer中就会知道,一个topic有几个messagequeue,哪些messagequeue在哪台broker机器上;
那么从nameServer获取到了这些信息,生产者就会均匀的将消息写入各个messageQueue,例如发送了20条数据,如果有4个队列(messageQueue)每个都会写入5条数据,其他写入的策略暂时不管;

对messagequeue数据分片做个小总结:
通过这个机制/方法,不就可以将写请求分散到多个broker,提高了写入效率,数据分布式存储后,就又可以实现rocketMQ的海量数据存储了。
2.2:万一某个broker挂了呢?messagequeue消息分片写入问题
就是这么神奇,自从写了代码,就有万一XXX,万一XXX等等小思考,问题分析:broker出现故障,例如某台master broker出现故障,那么此时正在等待其他的slave broker自动热切换为master broker,那么这个时候对这组broker就没有master broker可以写入了,此时如果还是按照之前的策略,均匀的写入到各个broker上的messagequeue上,会导致在一段时间内,每次访问这个挂掉的master broker都会访问失败,
问题解决:对于这个问题,建议在producer生产者开启一个开关:sendLatencyFaultEnable,一旦打开了这个开关,就会有一个自动容错的机制,例如某次访问broker发现网络延迟时间500ms,还是无法访问,就会自动回避这个broker一段时间,例如接下来的3000ms内,就不会访问这个broker了,这个容错机制就可以避免一个broker故障之后,生产者还频繁的发送消息到故障的broker上去,过一段时间master broker恢复了,就可以访问了。
2.3:深入研究broker是如何持久化存储消息的?
上面已经简单的了解了topic、messagequeue、broker以及nameServer的关系,那得了解一下,broker是如何持久化存储消息的呢?
2.3.1:why?=为啥要持久化,经过磁盘,不就降低性能了么?但是基于内存操作是不是增大风险了呢?万一你发了200条消息,broker宕机,200条消息不就什么也没了?疯狂翻日志,检查,恢复,甚至恢复不过来,出现杂七杂八的事情一大堆,降低点性能算啥?
2.3.2:broker数据存储才是mq最最核心的环节,决定了生产者写入消息的吞吐量,决定了数据的不丢失,决定了消费者获取消息的吞吐量;这里就引入了commitLog概念,知道commitLog是个文件就行了,log就是一个日志文件,commit不就是提交的意思吗?简单;
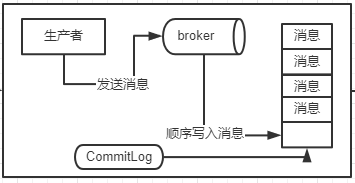
2.3.3:commitLog消息顺序写入机制:这个稍后上图,但是要知道顺序写入要比随意写入文件,不管是写入还是读取,性能都会高很多,毋庸置疑。
【简单看下这个图,初步认识一下commitLog顺序写入机制】
这个commitLog是很多磁盘文件,每个文件限定是1GB,如果commitLog写满了1GB,就会创建一个新的CommitLog文件,这个和底层的mmap技术有关系,估计在接下来的一章文章中会简单分析一些核心底层技术;
问题:messageQueue是具体体现在哪里的呢?
其实在broker中,对topic下的每个messageQueue都会又一系列的ConsumeQueue文件,就是在broker磁盘中会有这种格式的一系列文件:$HOME/store/consumerqueue/{topic}/{queueId}/{fileName},文件解释:每个topic都会有一些messageQueue,所以{topic}指定的就是某个topic,{queueId}指的就是某个MessageQueue,然后存储在这台broker机器上的topic的下一个messagequeue,有很多consumeQueue文件,这个consumeQueue文件里存储的是一条消息对应在commitLog文件中的offset偏移量,看到这里估计会有一些晕,没事,继续往下满满解答,最后尽量通俗易懂的做个小总缓解一下读文字的疲劳,先看一下图的变化:
做个图解:也就是说,topic下的messagequeue0和messagequeue1就放在broker机器上,每个messagequeue目前在磁盘上就对应了一个consumerqueue,所以,messagequeue0对应着broker磁盘上的consumerqueue0,1对应consumer1,假设queue的名字叫做:TopicOrderPaySuccess,那么此时在broker磁盘上应该有如下两个路径的文件:
$HOME/store/consumequeue/TopicOrderPaySuccess/MessageQueue0/ConsumerQueue0磁盘文件
$HOME/store/consumequeue/TopicOrderPaySuccess/MessageQueue1/ConsumerQueue1磁盘文件
然后当broker收到一条消息写入了commitLog之后,同时会将这条消息在commitLog中从物理位置,也就是一个文件偏移量,offset,写入到这条消息所属的messagequeue对应的consumerqueue中去
【再看图的架构演变】
所以:什么是offset,也得到了解释:实际上,consumerqueue0中存储的是一个个消息在commitLog文件中的物理位置,也就是offset,那么consumerQueue中的一个物理位置其实是对CommitLog文件中一个消息的引用,更详细的来讲:实际上在consumequeue中存储的每条数据不只是消息在commitLog中的offset偏移量,还包含了消息的长度,以及tag hashcode,一条数据是20个字节,每个consumequeue文件保存30万条数据,大概每个文件是5.72MB,这个文件大小也是一个铺垫,实际上topic的每个messagequeue都对应了broker机器上的多个consumerqueue文件,保存了这个messagequeue的所有消息在commitLog文件中的物理位置,也就是offset偏移量!


3.如何消息写入commitLog文件近乎内写性能的?
对于生产者将消息写入broker的时候,broker会直接把消息写入到磁盘的commitLog文件,那么broker是如何提升整个过程的性能的呢?
问题分析下:因为这个部分性能会直接提升broker处理消息写入的吞吐量,比如写入一条消息到commitLog磁盘文件假设需要10ms,那么每个线程每秒可以处理100个写入消息,假设有100个线程,每秒钟只能处理1万个写入消息请求。
但是如果将消息写入commitLog磁盘文件的性能优化为只需要1ms,那么每个线程每秒可以处理1000个消息写入,此时100个线程可以处理10万个写入请求,所以明显的可以看到,broker将接收到的消息写入commitLog磁盘文件的性能,对他的TPS有很大的影响。
SO:铺垫【broker是基于OS操作系统的pageCache和顺序写两个机制,来提升commitLog文件的性能的】;首先broker是以顺序的方式将消息写入commitLog磁盘文件的,也就是每次写入就是在文件的末尾追加一条数据就可以了,文件顺序写的性能要比随机写的性能提升很多,另外,数据写入commitLog文件的时候,其实不是直接写入底层的物理磁盘文件的,而是先进入OS的pagecache内存缓存中,然后后续由OS的后台线程选择一个时间,异步化的将OSPageCache内存缓冲中的数据刷入底层的磁盘文件。

commitLog优化思路总结:采用磁盘文件顺序写+OSPageCache缓存写入+OS异步刷盘的策略,基本上可以让消息写入commitLog的性能和直接写入内存是差不多的,所以broker才可以让broker高吞吐的处理每秒大量的消息写入。异步刷盘可能会导致消息数据丢失,简单提一嘴同步刷盘的机制:同步刷盘就是生产者发送一条消息出去,broker接收到了消息,必须直接强制的将这条消息刷入底层的物理磁盘中,然后返回ack给producer生产者,此时才知道消息写入成功了,只要消息进入了物理磁盘,数据就一定不会丢失,但是性能受了极大的影响;
4.dledger技术的broker主从同步的原理是什么?
【首先上个图,然后猜一猜】

dledger技术可以做什么?之前的文章中有dledger的相关介绍,dledger技术实际上自己就有一个commitLog机制,当数据交给dledger的时候,自己会写入commitLog磁盘文件里去,这是第一件事情,如果基于dledger技术实现broker的高可用架构实际上就是用dledger技术先替换掉原来broker管理的commitLog,由dledger来管理commitLog,所以第一步知道的就是,需要使用dledger来管理commitLog,然后broker还可以基于dledger管理commitLog去构建出来机器上的各个consumerqueue磁盘文件的。
4.1:dledger是如何基于raft协议选举master broker的呢?
dledger的raft算法举例:
基于dledger替换掉了每个broker上的commitLog管理组件,那么实际上就是每个broker都有一个dledger组件了,思考:如果配置了一组broker例如3台,dledger是如何选举master broker的呢?基于raft协议来进行leader broker选举的,投票选举机制情况的发生会出现一种情况,就是每个dledger的投票都是投给自己的,那么第一轮投票选举就是不成功的,接着每个节点会进行一个随机的休眠时间,苏醒时间是不一致的,raft算法的描述,raft算法就是确保有人可以成为master(leader),,如果第一轮选举不成功,会随机进入休眠状态,第一个苏醒的会将票投给自己,其他陆续苏醒的也会陆续投票给自己,读写分离,那么集群启动的时候,就会基于raft协议来进行投票选举,选举出来的master只负责写入,slave只负责接受master同步过来的数据;
dledger是如何基于raft协议进行多副本同步的?也就是master broker 数据同步到slave broker中:
数据同步会分为两个阶段:
阶段一:uncommitted阶段:
首先master broker的dledger接收到一条数据之后,会标记为uncommitted状态,然后会通过自己的dledger server组件将这个uncommitted数据发送给follower broker也就是slave broker的dledgerServer;
阶段二:commited阶段:
接着slave broker的dledgerServer接收到uncommitted消息之后,必须返回一个ack(说白了就是响应)给master的dledgerServer,如果master broker收到超过半数的slave broker返回ack之后,就会将消息标记为committed状态,然后master上的dledgerServer就会发送committed消息给slave broker的dledgerServer,各个slave上的dledgerServer也把消息标记为committed【这个就是基于raft协议实现的两个阶段完成的数据同步机制】;
如果master节点挂了,其中一个slave提升master,新选举出来的master就会通过dledger同步给剩下的slave broker;

5.深入研究消费者是如何获取消息处理以及进行ACK的?
消费者是如何从broker获取消息,并且进行处理已经维护消费进度的?
5.1:引出一个消费组的概念:首先知道什么是消费组: 消费者组的意思就是给一组消费者起一个名字,比如有一个topic叫topicOrderPaySuccess,假设有库存系统,积分系统,营销系统等等都要去消费这个topic中的数据,首先一个给四个系统分别起一个消费组的名字,设置消费组的方式是在代码中进行的,例如代码:
【DefultMQPushConsumer consumer = new DefaultMQPushConsumer("kc_consumer_group");】
例如某个系统部署了4台机器,每台机器上的消费者组的名称都是"kc_sonsumer_group",那么这4台机器就属于同一个消费组的。
正常的情况下,消息进入broker之后,库存系统和营销系统作为两个消费组,每个组都会拉取到这条消息,也就是订单支付成功的消息,库存系统会获取到一条,营销系统也会获取到一条,他们都会获取到这条消息;

5.1:消费组中出现机器宕机或者是扩容加机器,会如何处理?
进入rabalance环节,这个环节也就是重新给消息机器分配他们要处理的messagequeue,例如:机器01现在负责msg0和msg1,机器02负责msg03和msg04,那么现在02宕机了,机器01就会自动接管msg03和msg04;如果加入了一台机器03,此时就可以将机器02之前负责的msg03转移给机器03,这就是负载重平衡的概念;
总结下消费组概念:不同的系统应该设置不同的消费组,如果不同的消费组订阅了同一个topic,对topic里的一条消息,每个消费组都会获取到这条消息;
问题思考:思考一个消费组可能有多台机器,是只有一台获取到消息还是多台呢?
正常情况而言:消费组中只有一台机器会获取到这条消息;【继续深入:集群模式消费VS
广播模式消费】
5.2:集群模式消费VS广播模式消费
5.1.1:对于一个消费组而言,获取到一条消息后,消费组内部有多台机器,到底是只有一台机器能够获取,还是每台机器都可以获取到这条消息,在默认的情况下,都是集群模式,也就是说,一个消费组获取到一条消息,只会交给组内的一台机器去处理,而不是每台机器都能获取到这条消息的,各自处理各自的msg;
5.1.2:将默认的集群模式更改为广播模式【简单介绍一下】
consumer.setMessageModel(MeaageModel.BROADCASTING),消费组之广播模式【使用较少】,如果修改为广播模式,对于消费组获取到的一条消息,组内的每台机器都可以获取到这条消息,但是相对而言广播模式用的比较少,常见的都是使用集群模式来消费的。
6.最后重温一下MessageQueue,commitLog,consumeQueue之间的关系
一个topic创建的时候,是需要设置有多少个messageQueue的,也知道了broker上的messageQueue是如何跟consumerqueue对应起来的;

【图解】:
大致理解:topic中的多个messagequeue会分散到多个broker上面,在每个broker机器上,一个messagequeue就对应了一个consumerqueue,那么在物理磁盘上其实也就是对应了多个consumerqueue文件,大致理解为一一对应的关系。对于broker机器而言,存储在他上面的所有topic以及messagequeue的消息数据都是写入一个统一的commitlog的,对于topic的每个messagequeue而言,就是通过各个consumequeue来存储属于messagequeue的消息在commitlog文件中的物理地址,就是一个offset偏移量,messageQueue和消费者之间的关系就是图中的绿色部分,也就是说,对个topic的各个messagequeue来说,这个messagequeue是通过consumequeue文件来存储messagequeue的消息在conmitLog文件中的物理地址的;
举例:假设topicOrderPaySuccess有4个messageQueue,这四个messageQueue分布再两个master
broker上,那么每个master broker就有两个messagequeue,然后库存系统作为一个消费组里面有两台机器的部署,那么正常情况下,最好就是让这两台机器,每个都负责2个messageQueue的消费了,比如库存系统的机器01从master broker01上消费2个messagequeue,然后库存机器02消费master broker02上的2messagequeue即可,这样就完成了消息的负载均摊,大致理解:一个topic的多个messagequeue活均摊给消费组内的多个机器去消费,这里的一个原则就是,一个messagequeue只能被一个消费机器去处理,但是一台消费者机器可以负责多个messagequeue的消息处理。
本期分享的比较多,稍微偏底层一些,要是有分享不对的地方,欢迎多多指出与建议,上一篇博客地址:链接: rocketMQ(6下);
















 214
214











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











