






尽管过拟合是机器学习中的一个错误,它会降低模型的性能,但是,我们可以通过多种方式来防止它。使用线性模型,我们可以避免过拟合;然而,许多现实世界的问题是非线性的。防止模型过度拟合很重要。以下是可用于防止过拟合的几种方法:
- 提前停止
- 使用更多数据进行训练
- 特征选择
- 交叉验证
- 数据增强
- 正则化
提前停止
在这种技术中,在模型开始学习模型中的噪声之前暂停训练。在这个过程中,在迭代训练模型的同时,在每次迭代后衡量模型的性能。继续进行一定数量的迭代,直到新的迭代提高模型的性能。在那之后,模型开始过度拟合训练数据;因此,我们需要在学习者通过该点之前停止该过程。在模型开始从数据中捕获噪声之前停止训练过程称为提前停止。
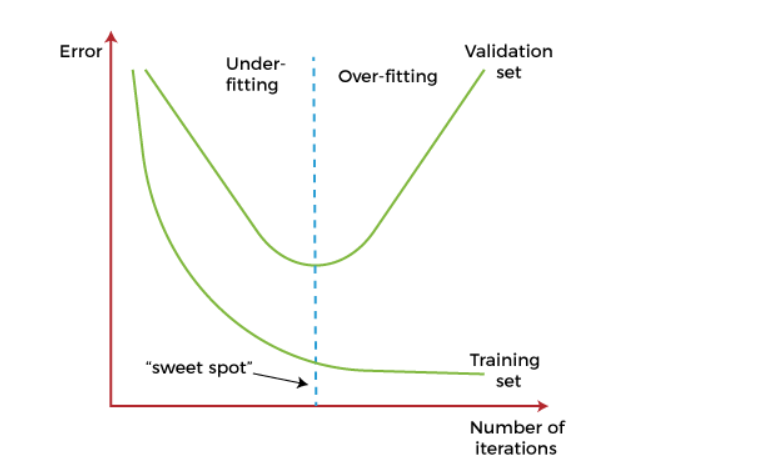
但是,如果过早暂停训练,这种技术可能会导致欠拟合问题。因此,找到欠拟合和过拟合之间的“合适点”非常重要。
使用更多数据进行训练
通过包含更多数据来增加训练集可以提高模型的准确性,因为它提供了更多发现输入和输出变量之间关系的机会。防止过度拟合可能并不总是有效,但这种方式有助于算法更好地检测信号以最小化错误。当一个模型被提供更多的训练数据时,它将无法过度拟合所有数据样本并被迫很好地泛化。但在某些情况下,额外的数据可能会给模型增加更多的噪音;因此,在将数据输入模型之前,我们需要确保数据是干净的并且没有不一致的。
特征选择
在构建 ML 模型时,我们有许多用于预测结果的参数或特征。然而,有时这些特征中的一些对于预测来说是多余的或不太重要,并且为此应用了特征选择过程。在特征选择过程中,我们识别出训练数据中最重要的特征,而其他特征被移除。此外,此过程有助于简化模型并减少数据中的噪声。有些算法有自动特征选择,如果没有,那么我们可以手动执行这个过程。
交叉验证
交叉验证是防止过拟合的强大技术之一。在一般的 k 折交叉验证技术中,我们将数据集划分为 k 等大小的数据子集;这些子集称为折叠。
数据增强
数据增强是一种数据分析技术,它是添加更多数据以防止过度拟合的替代方法。在这种技术中,不是添加更多的训练数据,而是将现有数据的稍微修改的副本添加到数据集中。
数据增强技术使得每次模型处理数据样本时都可能出现略有不同的数据样本。因此,每个数据集对模型来说都是唯一的,并且可以防止过度拟合。
正则化
如果模型复杂时出现过拟合,我们可以减少特征数量。然而,过拟合也可能发生在更简单的模型中,更具体地说是线性模型,对于这种情况,正则化技术很有帮助。
正则化是最流行的防止过拟合的技术。它是一组迫使学习算法使模型更简单的方法。应用正则化技术可能会略微增加偏差,但会略微降低方差。在这种技术中,我们通过添加惩罚项来修改目标函数,该惩罚项在更复杂的模型中具有更高的值。
两种常用的正则化技术是 L1 正则化和 L2 正则化。
集成方法
最常用的集成方法是Bagging 和 Boosting。在 bagging 中,可以多次选择单个数据点。在收集了几个样本数据集后,这些模型被独立训练,并根据任务的类型——即回归或分类——使用这些预测的平均值来预测更准确的结果。此外,bagging 减少了在复杂模型中过度拟合的机会。
在 boosting 中,大量排列成一个序列的弱学习器被训练成序列中的每个学习器从它之前的学习器的错误中学习。它将所有弱学习器组合成一个强学习器。此外,它还提高了简单模型的预测灵活性。
















 519
519











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











