






马丁·福勒在《领域特定语言》中对语义模型的阐释具有较高的专业性和系统性,但对于初学者而言,理解该概念需要一定的知识储备。这主要源于两方面原因:其一,书中内容涉及编译原理、抽象语法树等计算机科学基础知识,若读者缺乏DSL相关背景,可能对部分技术描述感到晦涩;其二,作为一本工具性著作,该书侧重技术实现细节,对于完全未接触过DSL的读者,需要结合实践案例逐步消化理论内容,尽管作者已通过精炼的语言阐述核心思想。因此,本文将从多角度对语义模型展开解读——作为DSL的核心组成部分,深入理解其内涵对掌握领域特定语言技术体系具有关键意义。
需要明确的是,DSL本质上是由脚本、语法分析器、语义模型等要素构成的完整体系。但在本小节讨论中,为聚焦核心概念,将DSL的范畴限定为前两部分(DSL脚本与语法分析器),暂不纳入语义模型的整体框架。这一阶段性的视角划分,旨在帮助读者分层次理解DSL的技术构成,后续将逐步引入语义模型的内容以构建完整认知。
一. 初识语义模型
读者是否考虑过,“编程语言”的本质究竟是什么?从广义上讲,编程语言是一种能被计算机和人类理解的符号系统,其中计算机可识别性是其核心特性。Python、Java、C#等通用编程语言,以及开发者自定义的DSL均属此类。每种编程语言背后都存在着一个语义模型(Semantic Model),它定义了程序及其组成元素的含义,以及这些元素如何组合以表达有意义的计算逻辑。对于语义的理解,有时会给人一种“只可意会,不可言传”的感觉。所以,使用案例的方式进行说明会带来更好的效果。代码1-6由Java和Python编写,用于对变量进行声明。
代码1-6
int x = 0; //Java
name = "my name" # Python尽管这两段代码在表现形式有着很大差异,但我们认为二者的语义是一样的:将值赋给一个特定的变量。请读者再看一下代码1-7的含义:
代码1-7
x = 1 + 1;这是一个由未知语言所编写的代码,变量x的值到底是什么完全取决于语义的设定,它可能是2,也能是1。前者意味着这句代码的语义就是数学上的加法;后者则代表了逻辑计算的结果。可以看到,仅在脚本或代码的维度,我们是无法将语言所代表的语义表达出来的。读者可能会对此产生疑问:代码1-6中的int x = 0表示将0赋给变量x,语义不是可以通过代码体现出来吗?当然不是!它的语义并不是由语言所体现出来的,而是某本书、某个老师、某个前辈告诉您的。实际上,当我们在学习某一门语言的时候,会主要学习两方面的知识:语法、语义。而就代码本身来说,它仅仅是语言的一种表现形式,具体应如何理解,需要依赖其背后的语义模型负责解释。自然语言其实也是如此,它的表现形式可以是文字,也可以是人们口中所说的话,负责解释语言含义的则是人脑。
“编译”的本质是编程语言的翻译过程,所有编程语言都需通过某种形式的翻译才能被计算机执行,只是不同语言的翻译方式有所差异。编译型语言通常有显式的编译阶段,将高级语言代码转换为机器语言或中间语言,例如Java代码会被编译为字节码,C#代码会被编译为中间通用语言(CIL),这些过程可被开发者直观感知。而解释型语言的编译过程通常对用户透明,在后台自动完成——以Python为例,执行.py文件时,源代码会先被编译为字节码这一中间表示形式,再由解释器执行。
解释编译的概念,是因为其通常包含语义分析过程。一般来说,代码编译会经历语法分析和语义分析两个阶段:
- 语法分析阶段。验证代码是否符合语言的语法规则,例如检查括号匹配、关键字使用是否正确等;
- 语义分析阶段。检查代码含义的正确性,确保其符合语言的语义规则,例如变量类型是否匹配、操作符是否适用等。
现代编译器为提升效率,可能不完全遵循两阶段的严格顺序,而是采用交叉优化策略,在语法分析过程中同步进行部分语义验证,以减少整体编译耗时。这种设计体现了编译技术在理论模型与工程实践之间的平衡。
语法分析是检验代码结构正确性的过程。以Java 为例,“语句后面没有分号作为结尾” 是典型的语法错误。然而,语法正确并不一定意味着语义正确,例如代码1-8:
代码1-8
void doSomething() {
int x;
int y = x + 1;
}上述代码无法通过编辑。从语法的角度来看,代码本身并无任何问题,无论是赋值语句还是变量x的声明,该有的元素都有。但是语义检测是通不过的,因为Java要求局部变量在使用前必须显式初始化。
在编译过程中,语义检查由编译器负责执行,但编译器需要依赖语义模型来完成这一任务。需要明确的是,通用语言领域的语义模型并非传统的对象模型,而是一套隐式的规则与定义,由编译器在语义分析阶段基于程序语法结构和语言规则动态构建。许多读者对语义模型概念感到困惑,可能源于对“模型”一词的认知偏差——具备技术背景的读者往往将其等同于代码中的类或接口,但实际情况并非如此。例如在面向对象分析中,“建模”可能仅表现为描述性文字或图形化表达,与具体实现代码并无直接关联。在语义模型的语境下,“模型”本质上是一种描述程序语义的数据结构,用于在编译阶段验证代码逻辑的合法性。
回归正文。读者可以想象一下代码1-6中的片段“int x = 0”所对应的语义模型,或许只是这样的一些描述:
- 声明一个名称为x的变量。
- 为该变量分配4个字节的内存地址。
- 设置该变量的值为0。
- 将变量名增加到符号表中。
- ……。
二. DSL中的语义模型
在DSL的语境中,语义模型的核心概念与通用语言保持一致,但更聚焦于特定领域的概念和操作,且表现形式更为显式。如前文所述,通用语言的语义模型通常以隐式方式存在,不直接呈现为对象模型;而在DSL中,随着复杂度提升,显式定义语义模型几乎成为必然选择。DSL的语义模型直接映射目标领域的核心概念,其表现形式包括对象模型、图结构、关系模型或逻辑表达式等。例如,对于用于参数验证的DSL,语义模型便是验证规则;对于表示配置的DSL,语义模型便是配置信息模型;对于代码生成的DSL,语义模型则是一种信息载体,包含了生成代码时所需要的全部元数据。
从技术实现角度,通用语言编译器中的语义模型通常以抽象语法树(AST)、类型系统、控制流图等中间表示形式存在,结构复杂且高度隐晦。相比之下,DSL的语义模型多以显式定义的类和接口呈现,与领域模型的表现形式趋同。可以认为,通用语言的语义模型更接近编译过程中的中间数据,而DSL的语义模型则直接承载领域逻辑,成为连接DSL语法与实际业务逻辑的桥梁——尽管它可能不是最终的执行形态,但已完整表达领域概念的核心语义。
在DSL的设计过程中,显式定义语义模型要求将语法模型与语义模型分开进行设计。当然,这种分离并非意味着两者完全独立,而是将其视为DSL设计的不同阶段(通常先设计语义模型,再进行语法设计)。设计师需确保两者间的最大解耦,此举可带来以下优势:
- 独立演进能力。DSL的语法层位于语义模型之上,允许独立变更语法表现形式而不影响底层逻辑。例如,同一语义模型可支持命令式、声明式或图形化等多种语法形态。只要语义模型的接口保持稳定,语法层的修改不会产生严重影响。这与现代应用的前后端分离架构类似——将DSL语法视为语义模型的“表现层”,可实现两者的独立迭代。
- 模块化测试机制。由于语义模型通常以显式对象模型存在,可通过单元测试等手段独立验证其逻辑正确性。同理,DSL语法层也可单独测试,确保语法解析的准确性。这种分离简化了测试流程,提升了组件质量。
- 简化实现复杂度。DSL语法分析器与语义模型属于不同责任域:前者负责解析用户输入并组装语义模型,后者承载领域逻辑或代码生成所需数据。将两者分离符合“分而治之”的设计原则,避免组件职责过载,降低实现复杂度。
一般而言,使用语义模型的形式主要有两种:一是实例化后直接运行;二是通过语义模型来生成另外一种代码。当然,这两种情况是可以共存的。很明显,第一种形式比较简单,也是最常见的使用语义模型的方式;第二种则要复杂一点,此时的语义模型实际上是一种中间状态,被生成的代码才是最终的结果。有读者可能会对代码生成的概念不太理解,实际上这是使用DSL的另一种常见形式。实现代码生成的方法有很多,实践中也比较常见,比如根据表结构信息生成数据实体、根据数据实体生成DAO接口以及实现类、根据JSON生成DTO等等。熟悉C#开发的读者应该会知道一个非常有名的代码生成器产品:CodeSmith,该产品强大到“令人发指”。只要有了数据库表,它就可以帮助您生成大部分的基础能力:数据实体、DAO、应用服务等,甚至是UI页面。
读者或许会疑惑,为何需要借助语义模型生成代码?主要原因如下:
- 语义模型不仅描述了业务领域的核心概念与关系,还包含代码生成所需的元数据。
- 同一语义模型可适配不同平台或目标语言的代码生成需求。
- 实现DSL语法优化与代码生成逻辑的责任解耦,降低维护复杂度。
尽管可在语法分析过程中生成代码,但强烈不建议此做法。语法分析器的核心职责仅为验证语言语法正确性——针对用户输入脚本,仅返回布尔值(True表示语法正确,False表示存在语法错误)。若为其附加其他职责,将导致后续扩展与维护复杂度显著增加。因此,将语法分析与代码生成解耦,以语义模型作为代码生成器输入是更优方案。随着对DSL理解的深入,这种分离设计的合理性将逐步显现。当然,亦需避免教条主义:若DSL逻辑极其简单,伴随语法分析同步生成目标代码亦非不可行,甚至可省略语义模型。
三. 语义模型的实现形式
语义模型的表现形式具有灵活性,其实现模式与DSL应用场景紧密相关,既可以是领域模型,也可以是简单的数据结构。在DSL领域中,语义模型可视为领域模型的子集,但其仅关注特定领域概念,无需像领域模型那样完整捕捉业务核心逻辑与数据。从角色定位看,领域模型代表系统关键概念,而语义模型聚焦特定领域并解释DSL行为。若语义模型包含可执行行为,通常可直接运行;若仅作为数据载体,则常作为语言编译的中间形式(如代码生成输入)。
语义模型并非必需,特殊场景可省略。以数据格式翻译为例,若翻译逻辑简单且可伴随语法分析同步执行,则无需引入语义模型。反之,若逻辑复杂,则需显式定义语义模型。
部分场景中,抽象语法树可替代语义模型。尽管抽象语法树的具体概念尚未阐释,但其本质为树状数据结构(与传统数据结构中的树一致)。以四则表达式计算为例,所构建的抽象语法树与语义模型高度重合,这种情况下无需额外引入独立的语义模型。
四. 语义模型的责任
尽管语义模型在概念上可视为领域模型的子集,但在工程实践中建议明确区分两者。并非所有领域模型均适合直接作为语义模型,而且它们的设计初衷以及所承担的责任也存在着很大的区别。具体而言,当DSL用于领域模型组装时,语义模型应承载模型构建的核心逻辑;当DSL用于代码生成时,语义模型则需提供元数据支撑(如生成模板所需的数据源)。此类职责显然超出传统领域模型的设计边界。
若读者对语义模型的职责界定仍存疑义,可通过以下案例进一步阐释。为简化说明,仅聚焦基于语义模型的验证场景,请先参考代码1-9所示的DSL示例:
代码1-9
<dependencies>
<dependency>
<groupId>com.squareup.retrofit2</groupId>
<artifactId>retrofit</artifactId>
<version>${retrofit.version}</version>
</dependency>
</dependencies>该代码片段源自Maven配置文件(尽管采用XML格式,但本质上属于DSL范畴,此点无需质疑),用于声明项目依赖。从语法层面分析,这段代码完全符合XML规范,但语义正确性仍需验证。例如,version节点中引用的变量“retrofit.version”是否存在且合法,此类验证已超出语法分析的能力边界,若强行在语法分析阶段处理,将导致编译程序职责混乱。因此,合理的做法是将此类验证逻辑移交至语义分析阶段,由语义模型承载具体的验证规则。
再举一个例子,DSL脚本如代码1-10所示:
代码1-10
give users [mike@dsl.com] roles ["admin", "guest", "agent"]
give users roles ["db_admin"]此DSL片段用于用户角色分配。第一条脚本语法正确,可推导出其语法规则为:users节点后需指定账户信息,roles节点后需指定角色名称。第二条脚本因users节点后缺失账户信息,可在语法分析阶段被识别为错误。下面聚焦第一条脚本的语义验证问题。
假设执行该脚本时会先生成SQL语句,再将角色分配数据插入数据库。为确保执行结果的正确性,需验证以下两点:
- 是否存在名为“mike@dsl.com”的账户。
- 是否存在名为“admin”的角色。
若将这些数据检查逻辑嵌入到SQL语句中,会导致SQL复杂度剧增。更合理的设计是将验证环节放在SQL生成之前。那么,具体的验证逻辑应放在何处呢?答案仍是语义模型。这是因为此类验证本质上属于业务规则的范畴,而语义模型的核心职责正是承载和解释DSL中的业务逻辑。
请读者再思考一下,将生成和执行SQL语句的逻辑放到语义模型中是否合适呢?笔者给出的答案是否定的。在用户角色分配DSL场景中,目标用户是否存在属于领域概念,而SQL 操作则属于技术实现细节。正如我们不会将DAO操作直接嵌入领域模型一样,语义模型也应避免承担与技术实现强耦合的职责。
就语义模型的责任,笔者会在后续文章中通过案例进行说明。读者此刻只需要记住如下几点重要事项:
- 语义模型并不一定只是数据的载体,其可能包含丰富的方法。
- 语义模型的责任与DSL的目的(即领域)高度相关。
- 语法分析程序一般只用于检查DSL脚本是否符合语法规则,语义相关的检查应交由语义模型来负责。
- 可以将语义模型用作连接DSL和领域模型的连接器,以使得二者可以独立进化。
五. 感性认识语义模型
在先前的阐述中,我们已对语义模型的理论框架进行了详尽探讨。接下来,我们将通过具体实例——如代码1-11所示的参数验证内部DSL——帮助读者建立直观认知。该实例展示了语义模型在实际应用中的表现形式,为后续深入分析奠定基础。
代码1-11
void createProduct(String name, String code) {
ParameterValidator.build()
.addMinLengthRule(name, 5)
.addNotNullRule(name, code)
.validate();
}既然该DSL的目的是为了进行数据验证,进行语义模型设计时也应该本着这个目的,如图1.2所示。
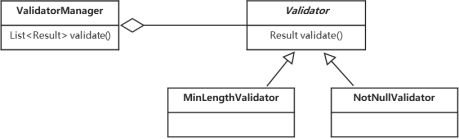
从代码1-11可推导出参数验证的核心流程:通过逐个调用add*(...)方法收集参数信息并构建验证规则对象,将其存入验证器列表;当调用validate()方法时,遍历该列表触发验证逻辑。图 1.2中,MinLengthValidator和NotNullValidator代表具体验证规则,ValidatorManager作为规则容器维护参数与验证规则的映射关系(即验证器列表)。
上述语义模型呈现以下特性:
- 对象模型化。以类和接口为载体,通过ValidatorManager、MinLengthValidator等具体类实现领域逻辑的结构化定义。
- 行为解释性。通过add*(...)方法链完成规则配置,validate方法驱动验证流程,直接映射DSL的“配置-执行”行为。
- 领域聚焦性。模型设计严格围绕数据验证场景,所有组件(规则、容器)均服务于参数合法性校验的核心目标,与DSL语义高度契合。

















 1984
1984

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









