









一、词法分析器的实现
在运用语法制导翻译或语法分析器生成器时,通常需先编写BNF格式的文法,再基于该文法实现语法分析器。尽管分隔符制导翻译方案通常无需此类文法规则,但笔者仍强烈建议在实现分析程序前,梳理待分析文本的构成规则——这一实践不仅便于词法分析器与语法分析器的开发,还可作为技术文档支持后续扩展维护,甚至为测试用例设计提供参考。文法3-1呈现了笔者对日志过滤规则DSL的语法描述:
文法3-1
关键字列表 'for service:' 服务名列表
关键字列表 'for service:' 服务名
关键字 'for service:' 服务名列表
关键字 'for service:' 服务名
关键字列表上述描述方式虽与BNF文法的设计思想有相似之处,不过笔者并未采用推导式的写法,而是直接把规则一一罗列出来。当语法结构极为简单时,采用这种相对原始的方式,尽管内容可能会显得有些冗长,但足以把问题阐释清楚。当然,BNF方式无疑更为专业,只是需要一定的学习成本,特别是在多人协作的场景下。所以,对于小型DSL而言,如果确定使用简单文本也能够清晰地描述语法规则,那么笔者认为这种做法并非不可行。
下面,我们来看看词法分析器的实现。从图 2.1能够了解到,外部DSL的构成元素里包含了词法分析器这一组件,但它并非是必需的。那么,对于分隔符制导翻译方案而言,我们是否有必要使用词法分析器呢?这个问题笔者很难给出一个确切的答案。不过按照个人的编程习惯,要是一项大任务能够分解成多个小步骤来处理,我肯定会选择采用拆分的方式去完成,也就是人们常说的“分治法”。就当前这个例子来说,笔者会选择引入词法分析器。但此词法分析器并非传统意义上的词法分析器,其输出的也不是Token列表,只是在设计上运用了词法分析的思想。尽管逻辑简单,但相比将它和语法分析器混杂在一起,这样的设计更为合适。
就如何从黑名单文件中读取过滤规则数据,逻辑比较简单,笔者不在此进行展示。代码3-8展示了词法分析器的实现细节,内容过长,因此我们使用分段的方式将其展示出来。
代码3-8
class Lexer {
static final String SERVICE_DELIMITER = "for service:";
static final String COMMA = ",";
List<String> parse(String text) {
List<String> lexemes = new ArrayList<>();
if (text.contains(SERVICE_DELIMITER)) {
String keywords = keywords(text);
lexemes.addAll(splitText(keywords));
lexemes.add(SERVICE_DELIMITER);
String services = services(text);
lexemes.addAll(splitText(services));
} else {
lexemes.addAll(splitText(text));
}
return lexemes;
}
}parse()方法的核心功能是解析单行日志过滤规则文本。其处理流程如下:首先过滤掉空行及冗余符号(如逗号),然后对预处理后的文本进行分段,并将结果封装为词素列表(List)输出。该列表结构为:前半部分包含关键字信息,后半部分包含服务名称信息,两部分通过字符串“for service:”分隔。尽管可自定义分隔符,但建议沿用源码中的约定,否则需同步告知语法分析器设计者词法分析阶段引入的新规则。
假设过滤规则文本如下所示:
k1,k2 for service: s1,s2
读者是否可以猜测到调用parse()方法之后的输出对象格式?笔者的答案如下:
| k1 | k2 | for service: | s1 | s3 |
探讨完parse()方法的输出之后,我们再了解一下该方法的参数。其代表的是黑名单文件中的一条日志过滤规则。再次提醒一下,在实际编程过程中,务必要对输入内容进行检查,像是否为空字符串、是否为null等。做好防御式编程对程序的稳定性而言至关重要。
继续代码的学习。parse()方法内部还调用了另外三个方法,分别是keywords()、services()和splitText()。前两个方法分别用于从输入文本里获取关键字部分的信息和服务名称部分的信息,逻辑相对简单,所以笔者仅重点展示最后一个方法的实现。splitText()方法能够把以逗号分隔的字符串解析成字符串列表对象,这是词法分析器中最为关键的逻辑部分,如代码 3-9所示:
代码 3-9
class Lexer {
List<String> splitText(String keywords) {
if (!StringUtils.hasLength(keywords)) {
return new ArrayList<>();
}
List<String> result = new ArrayList<>();
String[] splits = keywords.split(COMMA);
for (String s : splits) {
s = s.trim();
if (StringUtils.hasLength(s)) {
result.add(s);
}
}
return result;
}
String keywords(String text) {
return text.substring(0, text.indexOf(SERVICE_DELIMITER));
}
}splitText()方法的实现逻辑较为简明,我们不做过多的解释。值得留意的是,在词法分析过程中,笔者仅进行了简单的判断操作,对于诸如关键字信息为空字符串这类明显的语法问题,并未采取抛异常的处理方式。实际上,这体现了词法分析器的一项重要设计原则,即保持职责单一性。也就是说,应将语法分析的职责交由语法分析器,词法分析器只需专注于剔除源代码中的无用信息,并将输入代码转换为语法分析器可识别的格式。同理,语法分析器也无需关注词法分析的具体实现细节,只需依据既定语法规则对输入内容进行分析即可。既然在设计阶段就决定采用两个独立的组件,那么在实现过程中就应确保每个组件仅承担特定任务,尽量减少不必要的交互。
从另一个角度来看词法分析器的设计思想,原则上,对于编译过程中出现的错误,应采用统一的处理方式。若让词法分析器同时承担语法检查的职责,就需要人为保证词法分析阶段和语法分析阶段的错误处理逻辑一致。对于大型DSL而言,这种做法会显著降低协作效率。
最后,再谈一下无意义字符的处理。通常情况下,注释信息也是词法分析器需要过滤的内容之一。不过为了简化案例,笔者并未在其中考虑注释功能。其实现逻辑其实并不复杂,您可以预先定义某个字符,如双斜杠(//)、井号(#)等作为注释的起始符号,在词法分析过程中,只需将该符号及其后面的内容过滤掉即可。对于DSL而言,除非有特殊需求,否则不建议支持分块注释或跨行注释(语法分析器生成器除外),因为这会增加词法分析器的实现难度。
二、语法分析器的实现
在完成词法分析器的设计之后,接下来进入语法分析器的实现阶段。语法分析器的输入是黑名单中的DSL源代码,经过按换行符切分后形成DSL脚本列表,该列表中的每个元素都代表着一条日志过滤规则;其输出则是语义模型LogFilter类型的对象。首先要展示的代码是语法分析器的定义以及入口方法parse(),具体内容如代码3-10所示:
代码3-10
class Parser {
List<String> textLines;
Lexer lexer = new Lexer();
LogFilter parse() {
List<FilterRule> rules = new ArrayList<>();
for (String textLine : textLines) {
FilterRule rule = parseRule(textLine);
if (rule != null) {
rules.add(rule);
}
}
return new LogFilter(rules);
}
}对于输入的DSL脚本列表,parse()方法的处理逻辑比较简单,其会循环列表中的每一个元素并将其传递给方法parseRule()进行解析处理,后者的处理结果为FilterRule类型的对象。待所有的DSL脚本解析完毕后,也就意味着语义模型的构建工作完成了。很明显,parseRule()是这一过程中的关键部分,其片段如代码3-11所示:
代码3-11
FilterRule parseRule(String text) {
List<String> lexemes = lexer.parse(text);
if (lexemes.isEmpty()) {
return null;
}
KeywordGroup keywordGroup = parseKeywords(lexemes);
boolean hasService = hasService(lexemes);
ServiceGroup serviceGroup;
if (hasService) {
serviceGroup = parseServices(lexemes);
} else {
serviceGroup = new ServiceGroup(new ArrayList<>());
}
return new FilterRule(serviceGroup, keywordGroup);
}
boolean hasService(List<String> lexemes) {
return lexemes.stream()
.anyMatch(e -> Objects.equals(e, Lexer.SERVICE_DELIMITER));
}parseRule()方法的核心逻辑同样也比较简单,主要聚焦于如何构建FilterRule类的两个成员变量ServiceGroup和KeywordGroup。此外,语法分析器与词法分析器的集成也在本方法中得到体现。对于每一段DSL脚本,会首先送至词法分析器中进行解析,之后再利用返回的词素列表进行语法分析。当然,如果愿意的话您也可以选择首先对所有的源代码进行词法分析,之后再统一送到语法分析程序中进行解析处理。
接下来要讲解的是语法分析的核心逻辑。parseKeywords()方法用于对关键字部分的语法进行检查,如代码3-12所示:
代码3-12
KeywordGroup parseKeywords(List<String> lexemes) {
List<String> keywords = new ArrayList<>();
for (int i = 0; i < lexemes.size(); i++) {
String lexeme = lexemes.get(i);
boolean isDelimiter = Objects.equals(lexeme, Lexer.SERVICE_DELIMITER);
if (i == 0 && isDelimiter) {
throw new ParseException("no keywords");
}
if (!StringUtils.hasLength(lexeme)) {
throw new ParseException("no keywords");
}
if (!isDelimiter) {
keywords.add(lexeme);
continue;
}
break;
}
return new KeywordGroup(keywords);
}对代码3-12进行详细解释之前,请容许笔者再将词素列表的格式做一下展示:
| k1 | k2 | ... | kn | for service: | s1 | s2 | ... | sn |
可以看到,我们使用关键字“for service:”作为分隔符将词素列表中的内容分成了两部分。通过阅读上述代码,相信您也发现了笔者正是使用这一关键字作为解析关键字部分信息的结束条件。不过为了避免分隔符的重复定义,此处使用了词法分析器中的成员变量,这也是设计中的一个小技巧。
与此同时,您应该也在代码中看到了语法格式检测相关的逻辑,笔者使用了如下两个判断条件来解析关键字部分的内容:
- 分隔符前面是否存在关键字信息。
- 关键字信息是否为空字符串。
只要有一个条件成立,我们就会抛出包含错误提示的语法分析异常ParseException来终止当前流程。此处的检验最为关键,可以看作是语法分析器的核心逻辑之一。值得注意的是,关于语法错误的提示,笔者给出的信息相对简单,实践中您应该加上一些更为详细的内容,比如:行号、列号等。
针对服务名称的语法分析逻辑与关键字部分类似,虽然这一部分的信息为可选项,但并不意味着我们可以肆意而为,当DSL脚本中包含了分隔符“for service:”,却没有指定服务名称的时,就是典型的非法输入。这一部分的实现逻辑如代码3-13所示,建议读者结合代码3-11进行理解。
代码3-13
ServiceGroup parseServices(List<String> lexemes) {
List<String> services = new ArrayList<>();
int indexOfDelimiter = indexOfDelimiter(lexemes);
for (int i = indexOfDelimiter + 1; i < lexemes.size(); i++) {
String lexeme = lexemes.get(i);
if (!StringUtils.hasLength(lexeme.trim())) {
throw new ParseException("service name is empty");
}
services.add(lexeme);
}
if (services.isEmpty()) {
throw new ParseException("no service names");
}
return new ServiceGroup(services);
}
int indexOfDelimiter(List<String> lexemes) {
int index = 0;
for (String lexeme : lexemes) {
boolean isDelimiter = Objects.equals(lexeme, Lexer.SERVICE_DELIMITER);
if (!isDelimiter) {
index++;
} else {
break;
}
}
return index;
}至此,案例相关代码已全部展示完毕。总体而言,基于分隔符的语法分析器实现过程极为简便,几乎不涉及编译原理的专业知识。不过,其与传统语法分析存在一个相似之处,即在分析过程中均会构建语法分析树,如图 3.2所示。此外,在本案例中,语义模型实例是在语法分析过程中同步创建和组装的,这种方式对于简单DSL而言已足够适用,因此无需借助抽象语法树。
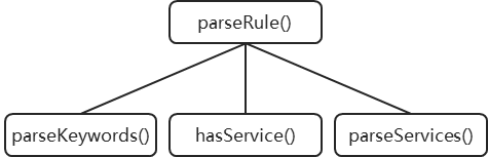
需要特别注意的是,若分析过程中需引用已创建的语义模型实例,建议构建符号表暂存这些对象。以当前案例为例,若在分析服务名称时需使用关键字信息,最优方案是将关键字对象存储于语法分析器的成员变量中,以便服务名称分析代码能够访问这些语义模型。具体实现细节将在后文详细阐述。
结束本章之前,笔者需要分隔符制导翻译方案做一下简单的总结。具体来说,有如下几点值得注意的事项:
- 虽然使用分隔符翻译的场景一般都比较简单,但仍然建议采用分治的方式去实现,能够让代码得到最大化的简化。
- 词法分析器仅应对源代码进行预处理或简单的格式化,不应干涉到语法分析、语义分析相关的逻辑。
- 尽管语义模型的定义顺序可能要先于DSL语法模型,但应时刻保持二者间的匹配,以避免后续因处理适配工作而频繁地调整代码。
- 分隔符的类型并不固定,要以语法模型为准。以本章日志过滤器为例,使用到的分隔符就包括换行、逗号和关键字“for service:”。

















 1万+
1万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









