







封装器法
请参考《数据准备和特征工程》中的相关章节,调试如下代码。

注意:本部分代码因为耗费的内存较大,在线执行如果不成功,请下载到本地执行。
4.1.1 循序特征选择
基础知识
# !mkdir /home/aistudio/external-libraries
# !pip install -i https://pypi.tuna.tsinghua.edu.cn/simple mlxtend -t /home/aistudio/external-libraries
import sys
sys.path.append('/home/aistudio/external-libraries')
from mlxtend.feature_selection import SequentialFeatureSelector as SFS
from sklearn.neighbors import KNeighborsClassifier
from mlxtend.data import wine_data
from sklearn.model_selection import train_test_split
from sklearn.preprocessing import StandardScaler
X, y = wine_data()
X.shape
(178, 13)
# stratify=y:对训练集和测试集按照标签y进行划分
X_train, X_test, y_train, y_test= train_test_split(X, y,
stratify=y,
test_size=0.3,
random_state=1)
# 特征标准化
std = StandardScaler()
X_train_std = std.fit_transform(X_train)
# 创建knn模型,作为SFS(封装器)的目标函数:estimator=knn
# k_features=4:选择4个最佳特征
# forward=True:True代表循序向前特征选择
# floating=False:若为True,则启用浮动选择算法
# verbose=2:表示输出训练过程的全部日志信息,0为不显示,1为只显示1个
# scoring='accuracy':对模型的评估方法
# cv=0:0为不进行交叉验证,默认值是5,表示要进行交叉验证,将训练集分为5份:训练4份,验证1份
knn = KNeighborsClassifier(n_neighbors=3)
sfs = SFS(estimator=knn,
k_features=4,
forward=True,
floating=False,
verbose=2,
scoring='accuracy',
cv=0)
sfs.fit(X_train_std, y_train)
[Parallel(n_jobs=1)]: Using backend SequentialBackend with 1 concurrent workers.
[Parallel(n_jobs=1)]: Done 1 out of 1 | elapsed: 0.0s remaining: 0.0s
[Parallel(n_jobs=1)]: Done 13 out of 13 | elapsed: 0.1s finished
[2022-05-22 11:00:12] Features: 1/4 -- score: 0.8629032258064516[Parallel(n_jobs=1)]: Using backend SequentialBackend with 1 concurrent workers.
[Parallel(n_jobs=1)]: Done 1 out of 1 | elapsed: 0.0s remaining: 0.0s
[Parallel(n_jobs=1)]: Done 12 out of 12 | elapsed: 0.0s finished
[2022-05-22 11:00:12] Features: 2/4 -- score: 0.9596774193548387[Parallel(n_jobs=1)]: Using backend SequentialBackend with 1 concurrent workers.
[Parallel(n_jobs=1)]: Done 1 out of 1 | elapsed: 0.0s remaining: 0.0s
[Parallel(n_jobs=1)]: Done 11 out of 11 | elapsed: 0.0s finished
[2022-05-22 11:00:13] Features: 3/4 -- score: 0.9919354838709677[Parallel(n_jobs=1)]: Using backend SequentialBackend with 1 concurrent workers.
[Parallel(n_jobs=1)]: Done 1 out of 1 | elapsed: 0.0s remaining: 0.0s
[Parallel(n_jobs=1)]: Done 10 out of 10 | elapsed: 0.0s finished
[2022-05-22 11:00:13] Features: 4/4 -- score: 0.9838709677419355
SequentialFeatureSelector(clone_estimator=True, cv=0,
estimator=KNeighborsClassifier(algorithm='auto',
leaf_size=30,
metric='minkowski',
metric_params=None,
n_jobs=None,
n_neighbors=3, p=2,
weights='uniform'),
fixed_features=None, floating=False, forward=True,
k_features=4, n_jobs=1, pre_dispatch='2*n_jobs',
scoring='accuracy', verbose=2)
# 返回每次选择出来的特征名称feature_names,及其相应的评估分数avg_score
sfs.subsets_
{1: {'feature_idx': (6,),
'cv_scores': array([0.86290323]),
'avg_score': 0.8629032258064516,
'feature_names': ('6',)},
2: {'feature_idx': (6, 9),
'cv_scores': array([0.95967742]),
'avg_score': 0.9596774193548387,
'feature_names': ('6', '9')},
3: {'feature_idx': (6, 9, 11),
'cv_scores': array([0.99193548]),
'avg_score': 0.9919354838709677,
'feature_names': ('6', '9', '11')},
4: {'feature_idx': (6, 8, 9, 11),
'cv_scores': array([0.98387097]),
'avg_score': 0.9838709677419355,
'feature_names': ('6', '8', '9', '11')}}
项目案例
# SFFS:循序向前浮动选择
knn = KNeighborsClassifier(n_neighbors=3)
sfs1 = SFS(estimator=knn,
k_features=4,
forward=True,
floating=True, # SFFS
verbose=2,
scoring='accuracy',
cv=0)
sfs.fit(X_train_std, y_train)
[Parallel(n_jobs=1)]: Using backend SequentialBackend with 1 concurrent workers.
[Parallel(n_jobs=1)]: Done 1 out of 1 | elapsed: 0.0s remaining: 0.0s
[Parallel(n_jobs=1)]: Done 13 out of 13 | elapsed: 0.1s finished
[2022-05-22 11:00:13] Features: 1/4 -- score: 0.8629032258064516[Parallel(n_jobs=1)]: Using backend SequentialBackend with 1 concurrent workers.
[Parallel(n_jobs=1)]: Done 1 out of 1 | elapsed: 0.0s remaining: 0.0s
[Parallel(n_jobs=1)]: Done 12 out of 12 | elapsed: 0.0s finished
[2022-05-22 11:00:13] Features: 2/4 -- score: 0.9596774193548387[Parallel(n_jobs=1)]: Using backend SequentialBackend with 1 concurrent workers.
[Parallel(n_jobs=1)]: Done 1 out of 1 | elapsed: 0.0s remaining: 0.0s
[Parallel(n_jobs=1)]: Done 11 out of 11 | elapsed: 0.0s finished
[2022-05-22 11:00:13] Features: 3/4 -- score: 0.9919354838709677[Parallel(n_jobs=1)]: Using backend SequentialBackend with 1 concurrent workers.
[Parallel(n_jobs=1)]: Done 1 out of 1 | elapsed: 0.0s remaining: 0.0s
[Parallel(n_jobs=1)]: Done 10 out of 10 | elapsed: 0.0s finished
[2022-05-22 11:00:13] Features: 4/4 -- score: 0.9838709677419355
SequentialFeatureSelector(clone_estimator=True, cv=0,
estimator=KNeighborsClassifier(algorithm='auto',
leaf_size=30,
metric='minkowski',
metric_params=None,
n_jobs=None,
n_neighbors=3, p=2,
weights='uniform'),
fixed_features=None, floating=False, forward=True,
k_features=4, n_jobs=1, pre_dispatch='2*n_jobs',
scoring='accuracy', verbose=2)
from mlxtend.plotting import plot_sequential_feature_selection as plot_sfs
# plot_sfs?
%matplotlib inline
from mlxtend.plotting import plot_sequential_feature_selection as plot_sfs
# 绘制特征子集与模型评分之间的关系图
# get_metric_dict():以字典的方式返回:knn模型对特征子集的各个特征组合进行评估的结果
# kind='std_err':{'std_dev'、'std_err'、'ci'、None} 中的误差线或置信区间。
fig = plot_sfs(sfs.get_metric_dict(), kind='std_err')
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-coeXT1yZ-1653294190061)(https://s2.loli.net/2022/05/23/6jGhMIH81fxcbke.png)]
sfs.get_metric_dict()
{1: {'feature_idx': (6,),
'cv_scores': array([0.86290323]),
'avg_score': 0.8629032258064516,
'feature_names': ('6',),
'ci_bound': nan,
'std_dev': 0.0,
'std_err': nan},
2: {'feature_idx': (6, 9),
'cv_scores': array([0.95967742]),
'avg_score': 0.9596774193548387,
'feature_names': ('6', '9'),
'ci_bound': nan,
'std_dev': 0.0,
'std_err': nan},
3: {'feature_idx': (6, 9, 11),
'cv_scores': array([0.99193548]),
'avg_score': 0.9919354838709677,
'feature_names': ('6', '9', '11'),
'ci_bound': nan,
'std_dev': 0.0,
'std_err': nan},
4: {'feature_idx': (6, 8, 9, 11),
'cv_scores': array([0.98387097]),
'avg_score': 0.9838709677419355,
'feature_names': ('6', '8', '9', '11'),
'ci_bound': nan,
'std_dev': 0.0,
'std_err': nan}}
# 改进做法:k_features=(3, 10)设置特征数量的范围,在该范围中找出最佳个数的特征
knn = KNeighborsClassifier(n_neighbors=3)
sfs2 = SFS(estimator=knn,
k_features=(3, 10),
forward=True,
floating=True,
verbose=0,
scoring='accuracy',
cv=5)
sfs2.fit(X_train_std, y_train)
fig = plot_sfs(sfs2.get_metric_dict(), kind='std_err')
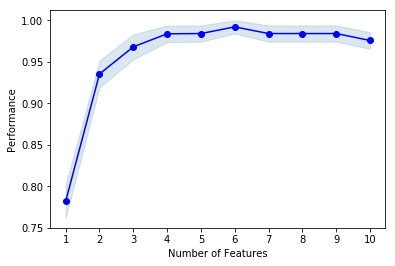
# 由图查看最佳特征数量为6个,查看详细信息
sfs2.subsets_[6]
{'feature_idx': (0, 3, 6, 9, 10, 12),
'cv_scores': array([0.96, 1. , 1. , 1. , 1. ]),
'avg_score': 0.992,
'feature_names': ('0', '3', '6', '9', '10', '12')}
动手练习
import pandas as pd
df = pd.read_csv("data/data20528/housprice.csv")
df.shape
df.head()
| Id | MSSubClass | MSZoning | LotFrontage | LotArea | Street | Alley | LotShape | LandContour | Utilities | ... | PoolArea | PoolQC | Fence | MiscFeature | MiscVal | MoSold | YrSold | SaleType | SaleCondition | SalePrice | |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| 0 | 1 | 60 | RL | 65.0 | 8450 | Pave | NaN | Reg | Lvl | AllPub | ... | 0 | NaN | NaN | NaN | 0 | 2 | 2008 | WD | Normal | 208500 |
| 1 | 2 | 20 | RL | 80.0 | 9600 | Pave | NaN | Reg | Lvl | AllPub | ... | 0 | NaN | NaN | NaN | 0 | 5 | 2007 | WD | Normal | 181500 |
| 2 | 3 | 60 | RL | 68.0 | 11250 | Pave | NaN | IR1 | Lvl | AllPub | ... | 0 | NaN | NaN | NaN | 0 | 9 | 2008 | WD | Normal | 223500 |
| 3 | 4 | 70 | RL | 60.0 | 9550 | Pave | NaN | IR1 | Lvl | AllPub | ... | 0 | NaN | NaN | NaN | 0 | 2 | 2006 | WD | Abnorml | 140000 |
| 4 | 5 | 60 | RL | 84.0 | 14260 | Pave | NaN | IR1 | Lvl | AllPub | ... | 0 | NaN | NaN | NaN | 0 | 12 | 2008 | WD | Normal | 250000 |
5 rows × 81 columns
# 讲数据类型为'int64', 'float64'的特征列挑选出来组成新的数据集data
cols = list(df.select_dtypes(include=['int64', 'float64']).columns)
data = df[cols]
print(data.shape)
data.head()
(1460, 38)
| Id | MSSubClass | LotFrontage | LotArea | OverallQual | OverallCond | YearBuilt | YearRemodAdd | MasVnrArea | BsmtFinSF1 | ... | WoodDeckSF | OpenPorchSF | EnclosedPorch | 3SsnPorch | ScreenPorch | PoolArea | MiscVal | MoSold | YrSold | SalePrice | |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| 0 | 1 | 60 | 65.0 | 8450 | 7 | 5 | 2003 | 2003 | 196.0 | 706 | ... | 0 | 61 | 0 | 0 | 0 | 0 | 0 | 2 | 2008 | 208500 |
| 1 | 2 | 20 | 80.0 | 9600 | 6 | 8 | 1976 | 1976 | 0.0 | 978 | ... | 298 | 0 | 0 | 0 | 0 | 0 | 0 | 5 | 2007 | 181500 |
| 2 | 3 | 60 | 68.0 | 11250 | 7 | 5 | 2001 | 2002 | 162.0 | 486 | ... | 0 | 42 | 0 | 0 | 0 | 0 | 0 | 9 | 2008 | 223500 |
| 3 | 4 | 70 | 60.0 | 9550 | 7 | 5 | 1915 | 1970 | 0.0 | 216 | ... | 0 | 35 | 272 | 0 | 0 | 0 | 0 | 2 | 2006 | 140000 |
| 4 | 5 | 60 | 84.0 | 14260 | 8 | 5 | 2000 | 2000 | 350.0 | 655 | ... | 192 | 84 | 0 | 0 | 0 | 0 | 0 | 12 | 2008 | 250000 |
5 rows × 38 columns
# 将特征'SalePrice'作为标签列(labels)
X_train,X_test,y_train,y_test=train_test_split(data.drop('SalePrice',axis=1),data['SalePrice'],test_size=.2,random_state=1)
X_train.fillna(0, inplace=True) # 用0填充缺失值
from sklearn.ensemble import RandomForestRegressor
# 将随机森林回归模型作为SFS的目标函数
sfs3 = SFS(RandomForestRegressor(),
k_features=10,
forward=True,
verbose=0,
cv=5,
n_jobs=-1,
scoring='r2')
sfs3.fit(X_train,y_train)
# 挑选出来的10个最优特征
sfs3.k_feature_names_
('LotFrontage',
'OverallQual',
'YearRemodAdd',
'MasVnrArea',
'BsmtFinSF1',
'TotalBsmtSF',
'GrLivArea',
'Fireplaces',
'GarageCars',
'OpenPorchSF')
4.1.2 穷举特征选择
基础知识
# 将通过SFS选择出来的10佳特征作为新的数据集
mini_data = X_train[X_train.columns[list(sfs3.k_feature_idx_)]]
mini_data.shape
(1168, 10)
# from mlxtend.feature_selection import ExhaustiveFeatureSelector as EFS
# EFS?
import numpy as np
from mlxtend.feature_selection import ExhaustiveFeatureSelector as EFS
# EFS: 穷举特征选择来选出5强特征
# scoring='r2': (决定系数) 回归评分函数。
# n_jobs=-1: 并行数跟CPU核数一致。
efs = EFS(RandomForestRegressor(),
min_features=1,
max_features=5,
scoring='r2',
n_jobs=-1)
efs.fit(np.array(mini_data),y_train)
# 将5强特征名进行输出
mini_data.columns[list(efs.best_idx_)]
Features: 637/637
Index(['OverallQual', 'YearRemodAdd', 'BsmtFinSF1', 'TotalBsmtSF',
'GrLivArea'],
dtype='object')
项目案例
import pandas as pd
import numpy as np
# 选取该数据集的前20000行样本
paribas_data = pd.read_csv("data/data20528/paribas_data.csv", nrows=20000)
paribas_data.shape
(20000, 133)
# 通过数据类型来选择特征
num_colums = ['int16', 'int32', 'int64', 'float16', 'float32', 'float64']
numerical_columns = list(paribas_data.select_dtypes(include=num_colums).columns)
paribas_data = paribas_data[numerical_columns]
paribas_data.shape
(20000, 114)
from sklearn.model_selection import train_test_split
# 划分训练集:train_features和测试集:test_features
train_features, test_features, train_labels, test_labels = train_test_split(
paribas_data.drop(labels=['target', 'ID'], axis=1),
paribas_data['target'],
test_size=0.2,
random_state=41)
# correlated_features: 创建相关特征的空集合set()
correlated_features = set()
# corr():表示两个变量之间的相关性,取值范围为[-1,1],取值接近-1,表示反相关,取值接近1,表正相关。
correlation_matrix = paribas_data.corr()
# 将相关系数大于0.3的特征选择出来,加入到correlated_features集合中
for i in range(len(correlation_matrix.columns)):
for j in range(i):
if abs(correlation_matrix.iloc[i, j]) > 0.3:
colname = correlation_matrix.columns[i]
correlated_features.add(colname)
# 将上面选择出的correlated_features从数据集中删除。
train_features.drop(labels=correlated_features, axis=1, inplace=True)
test_features.drop(labels=correlated_features, axis=1, inplace=True)
train_features.shape, test_features.shape
((16000, 10), (4000, 10))
from mlxtend.feature_selection import ExhaustiveFeatureSelector
from sklearn.ensemble import RandomForestRegressor, RandomForestClassifier
from sklearn.metrics import roc_auc_score
# EFS:穷举特征选择
feature_selector = ExhaustiveFeatureSelector(RandomForestClassifier(n_jobs=-1),
min_features=2,
max_features=4,
scoring='roc_auc',
print_progress=True,
cv=2)
# 通过EFS模型来进行特征选择
features = feature_selector.fit(np.array(train_features.fillna(0)), train_labels)
# 最终得出2个最佳特征:'v10', 'v38'
filtered_features= train_features.columns[list(features.best_idx_)]
filtered_features
Features: 375/375
Index(['v10', 'v38'], dtype='object')
动手练习
# 第2题
from sklearn import datasets
from sklearn.ensemble import RandomForestClassifier
from mlxtend.feature_selection import ExhaustiveFeatureSelector as EFS
iris = datasets.load_iris()
X = iris.data
y = iris.target
efs = EFS(RandomForestClassifier(n_jobs=-1),
min_features=2,
max_features=4,
print_progress=True,
cv=2)
efs.fit(X, y)
efs.best_idx_
4.1.3 递归特征消除
基础知识
from sklearn.feature_selection import RFE
rfe = RFE(RandomForestRegressor(), n_features_to_select=5)
rfe.fit(np.array(mini_data),y_train)
# 打印特征排名,1为权重最高的5个特征
print(rfe.ranking_)
print(mini_data.columns[rfe.ranking_==1])
[4 1 2 3 1 1 1 6 1 5]
Index(['OverallQual', 'BsmtFinSF1', 'TotalBsmtSF', 'GrLivArea', 'GarageCars'], dtype='object')
项目案例
import pandas as pd
import numpy as np
from sklearn.preprocessing import LabelEncoder
df_train = pd.read_csv("data/data20528/train.csv")
df_test = pd.read_csv("data/data20528/train.csv")
# 统计训练集和测试集的样本行数
train_samples = df_train.shape[0]
test_samples = df_test.shape[0]
# 将训练集和测试集按行合并,忽视原索引,并使警告静音而不进行排序
train_test = pd.concat((df_train, df_test), axis=0, ignore_index=True, sort=False)
# 将特征集features划分为分类特征cat_features和数值特征num_features
features = [x for x in df_train.columns]
cat_features = [x for x in df_train.select_dtypes(include=['object']).columns]
num_features = [x for x in df_train.select_dtypes(exclude=['object']).columns]
print('\n 特征集个数: %d' % len(features))
print('\n 分类特征个数: %d' % len(cat_features))
print('\n 数值特征个数: %d\n' % len(num_features))
# 对分类特征的每一列进行标签编码LabelEncoder(),即数值化变换
le = LabelEncoder()
for c in cat_features:
train_test[c] = le.fit_transform(train_test[c])
X_train = train_test.iloc[:train_samples, :].drop(['id', 'loss'], axis=1)
X_test = train_test.iloc[train_samples:, :].drop(['id'], axis=1)
特征集个数: 132
分类特征个数: 116
数值特征个数: 16
from sklearn.feature_selection import RFECV
from sklearn.ensemble import RandomForestRegressor
from datetime import datetime
# 将loss值作为标签y_train
y_train = df_train['loss']
rfr = RandomForestRegressor(n_estimators=100,
max_features='sqrt',
max_depth=12,
n_jobs=-1)
rfecv = RFECV(estimator=rfr,
step=10,
cv=3,
min_features_to_select=10,
scoring='neg_mean_absolute_error',
verbose=2)
start_time = datetime.now()
rfecv.fit(X_train, y_train)
end_time = datetime.now()
# 输出总的训练时间,m,s为divmod()计算后的商和余数
m, s = divmod((end_time - start_time).total_seconds(), 60)
print('训练时间花费为: {0} 分 {1} 秒'.format(m, round(s, 2)))
Fitting estimator with 130 features.
Fitting estimator with 120 features.
Fitting estimator with 110 features.
Fitting estimator with 100 features.
Fitting estimator with 90 features.
Fitting estimator with 80 features.
Fitting estimator with 70 features.
Fitting estimator with 60 features.
Fitting estimator with 50 features.
Fitting estimator with 40 features.
Fitting estimator with 30 features.
Fitting estimator with 20 features.
Fitting estimator with 130 features.
Fitting estimator with 120 features.
Fitting estimator with 100 features.
Fitting estimator with 90 features.
Fitting estimator with 80 features.
Fitting estimator with 70 features.
Fitting estimator with 60 features.
Fitting estimator with 50 features.
Fitting estimator with 40 features.
Fitting estimator with 30 features.
Fitting estimator with 20 features.
Fitting estimator with 130 features.
Fitting estimator with 120 features.
Fitting estimator with 110 features.
Fitting estimator with 100 features.
Fitting estimator with 90 features.
Fitting estimator with 80 features.
Fitting estimator with 70 features.
Fitting estimator with 60 features.
Fitting estimator with 50 features.
Fitting estimator with 40 features.
Fitting estimator with 30 features.
Fitting estimator with 20 features.
Fitting estimator with 130 features.
Fitting estimator with 120 features.
Fitting estimator with 100 features.
Fitting estimator with 90 features.
Fitting estimator with 80 features.
训练时间花费为: 4.0 分 37.94 秒
# 复制文件到matplotlib字体路径
!cp simhei.ttf /opt/conda/envs/python35-paddle120-env/lib/python3.7/site-packages/matplotlib/mpl-data/fonts/ttf/
# 删除matplotlib的缓冲目录
!rm -rf .cache/matplotlib
# 重启内核
%matplotlib inline
import matplotlib.pyplot as plt
# 设置显示中文
plt.rcParams['font.sans-serif'] = ['SimHei'] # 指定默认字体
plt.rcParams['axes.unicode_minus'] = False # 解决保存图像是负号'-'显示为方块的问题
plt.figure()
plt.xlabel('测试的特征数量 x 10')
plt.ylabel('交叉验证分数 (负MAE)')
plt.plot(range(1, len(rfecv.grid_scores_) + 1), rfecv.grid_scores_)
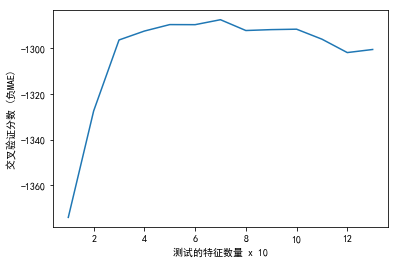
# 将特征进行排序,并显示前10的特征
ranking = pd.DataFrame({'特征': features})
ranking.drop([0, 131], inplace=True)
ranking['排名'] = rfecv.ranking_
ranking.sort_values('排名', inplace=True)
ranking.head(10)
| 特征 | 排名 | |
|---|---|---|
| 1 | cat1 | 1 |
| 103 | cat103 | 1 |
| 101 | cat101 | 1 |
| 100 | cat100 | 1 |
| 99 | cat99 | 1 |
| 94 | cat94 | 1 |
| 92 | cat92 | 1 |
| 91 | cat91 | 1 |
| 90 | cat90 | 1 |
| 89 | cat89 | 1 |
动手练习
# 第2题
import matplotlib.pyplot as plt
from sklearn.svm import SVC
from sklearn.model_selection import StratifiedKFold
from sklearn.feature_selection import RFECV
from sklearn.datasets import make_classification
# 创建数据集
X, y = make_classification(n_samples=1000, n_features=25, n_informative=3,
n_redundant=2, n_repeated=0, n_classes=8,
n_clusters_per_class=1, random_state=0)
# 创建RFEC
svc = SVC(kernel="linear")
rfecv = RFECV(estimator=svc,
step=1,
cv=StratifiedKFold(2),
scoring='accuracy')
rfecv.fit(X, y)
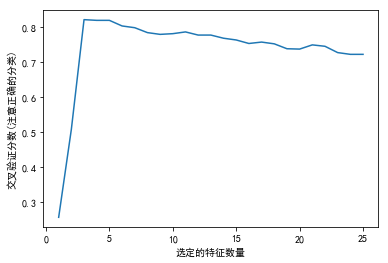
print("最优特征数量: %d" % rfecv.n_features_)
# 制图
plt.figure()
plt.xlabel("选定的特征数量")
plt.ylabel("交叉验证分数(注意正确的分类)")
plt.plot(range(1, len(rfecv.grid_scores_) + 1), rfecv.grid_scores_)
最优特征数量: 3
















 228
228











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











