







赛题地址:DC竞赛-大数据竞赛平台 (datacastle.cn)
一、数据集介绍
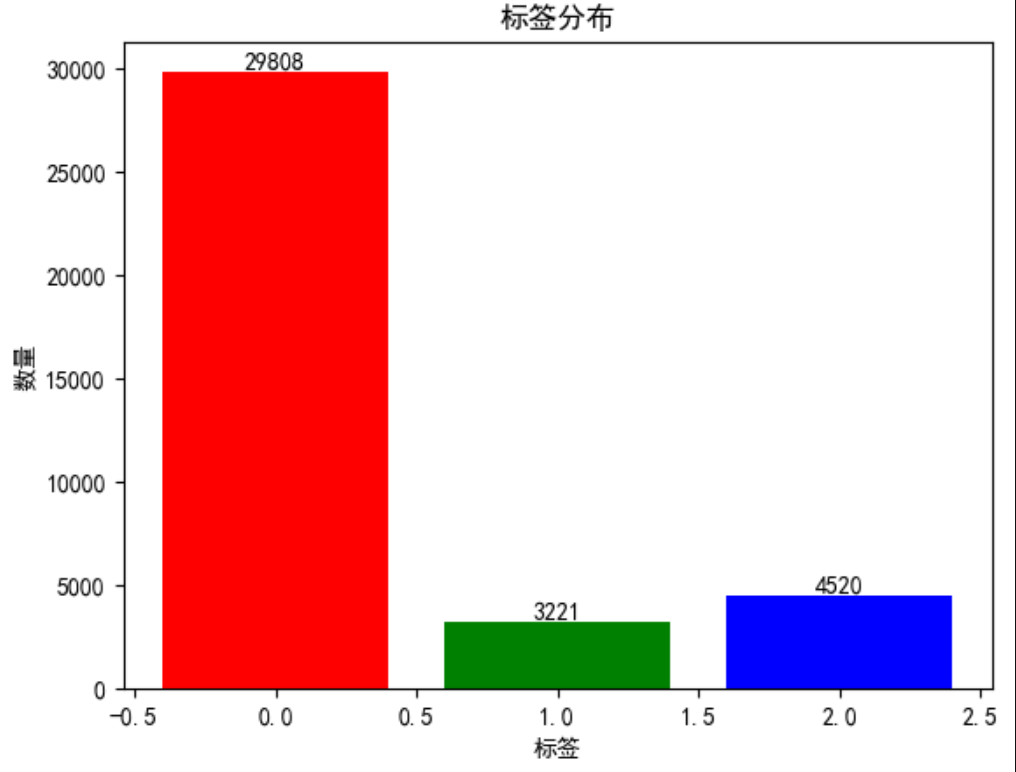
train_x训练数据集特征描述,其样本分布不均匀,0样本29808,1样本3221,2样本4520,共计37549条样本
第一维度:60 位受试样本数总和
第二维度:(血氧和心率)
第三维度:180 秒时序特征
train_y训练数据标签描述:
标签值:0-无事件,1-呼吸暂停,2-低通气事件
测试数据集描述:
第一维度:20 位受试者的总样本数
第二维度:(血氧和心率)
第三维度:180 秒时序特征
二、数据集样本分布查看
import numpy as np
import matplotlib.pyplot as plt
train_y = np.load('训练集/train_y.npy')
# 计算每个标签的数量
labels, counts = np.unique(train_y, return_counts=True)
# 创建一个颜色列表,为每个标签分配一个不同的颜色
colors = ['red', 'green', 'blue']
# 创建柱状图
plt.bar(labels, counts, color=colors)
# 在每个柱状图上标注数目
for i, count in enumerate(counts):
plt.text(labels[i], count + 1, str(count), ha='center', va='bottom')
# 设置图表标题和坐标轴标签
plt.title('标签分布')
plt.xlabel('标签')
plt.ylabel('数量')
# 显示图表
plt.show()
三、样本均衡处理
import numpy as np
# 加载数据集
train_x = np.load('训练集/train_x.npy')
train_y = np.load('训练集/train_y.npy')
# 统计每个类别的样本数量
unique, counts = np.unique(train_y, return_counts=True)
counts_dict = dict(zip(unique, counts))
# 根据要求抽取样本
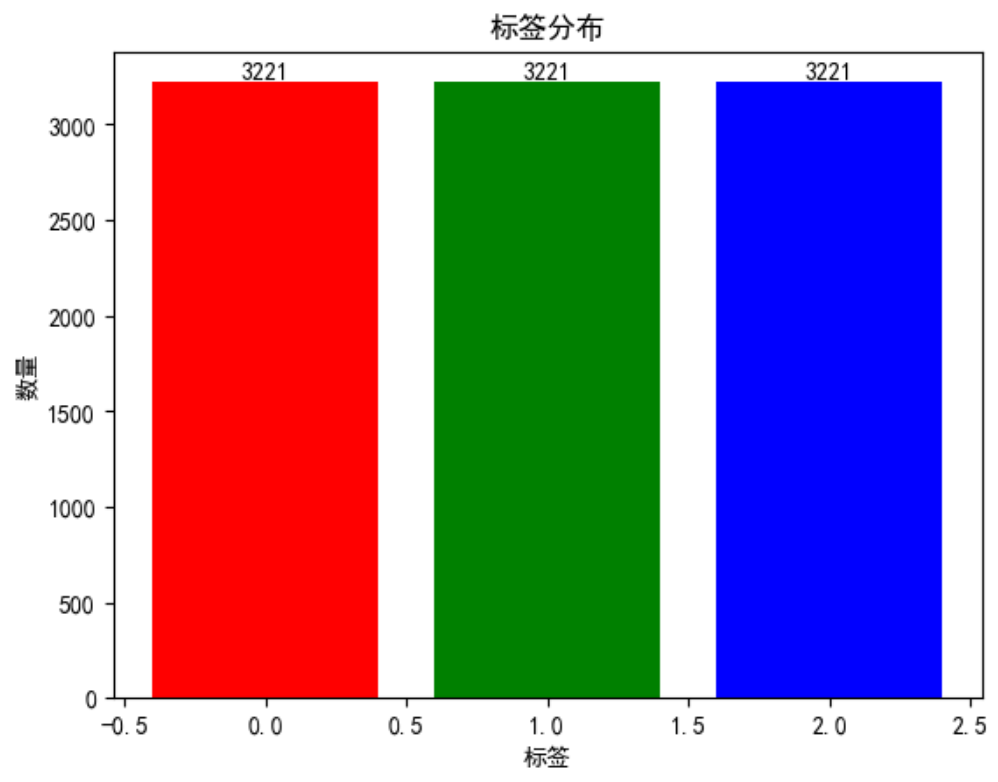
sample_counts = {0: 3221, 1: 3221, 2: 3221}
new_train_x = np.empty((3*3221, 2, 180))
new_train_y = np.empty(3*3221)
indices = {i: np.where(train_y == i)[0] for i in sample_counts}
new_indices = {i: np.random.choice(indices[i], sample_counts[i], replace=False) for i in sample_counts}
offset = 0
for i in sample_counts:
new_train_x[offset:offset+sample_counts[i]] = train_x[new_indices[i]]
new_train_y[offset:offset+sample_counts[i]] = i
offset += sample_counts[i]
# 检查新数据集的分布
new_unique, new_counts = np.unique(new_train_y, return_counts=True)
new_counts_dict = dict(zip(new_unique, new_counts))
new_counts_dict, counts_dict
四、单个样本查看
import numpy as np
import matplotlib.pyplot as plt
plt.rcParams['font.sans-serif'] = ['SimHei'] # 设置默认字体
plt.rcParams['axes.unicode_minus'] = False # 正确显示负号
# 加载数据集
train_x = np.load('训练集/train_x.npy')
train_y = np.load('训练集/train_y.npy')
# 选择一个样本进行绘图
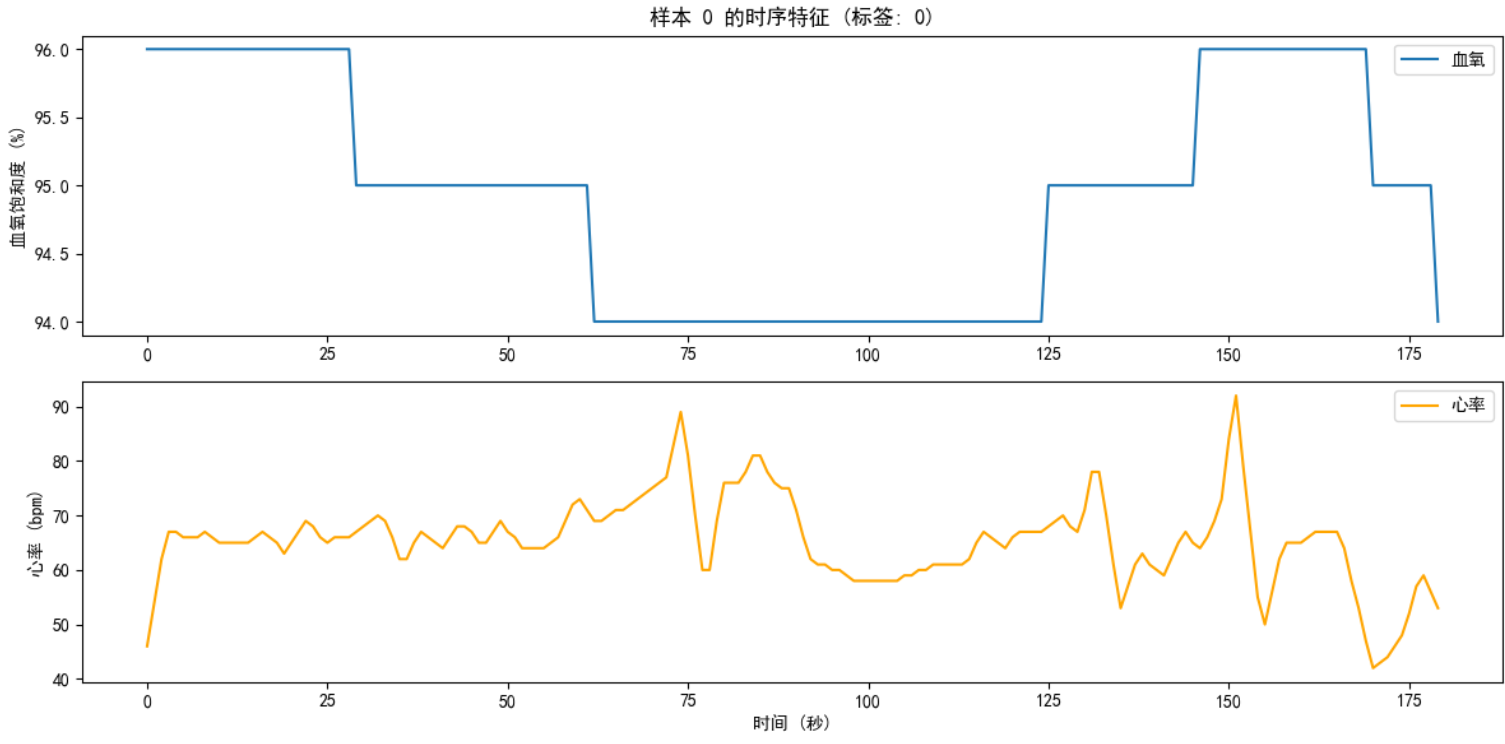
sample_index = 0 # 可以选择任意的样本索引
sample = train_x[sample_index]
label = train_y[sample_index]
# 血氧和心率数据
oxygens = sample[0] # 第一维度是血氧
heartrates = sample[1] # 第二维度是心率
# 时间轴(对应于第三维度,即180秒)
time = np.arange(0, 180)
# 绘图
plt.figure(figsize=(12, 6))
# 绘制血氧时序图
plt.subplot(2, 1, 1)
plt.plot(time, oxygens, label='血氧')
plt.title(f'样本 {sample_index} 的时序特征 (标签: {label})')
plt.ylabel('血氧饱和度 (%)')
plt.legend()
# 绘制心率时序图
plt.subplot(2, 1, 2)
plt.plot(time, heartrates, label='心率', color='orange')
plt.xlabel('时间 (秒)')
plt.ylabel('心率 (bpm)')
plt.legend()
# 显示图表
plt.tight_layout()
plt.show()
五、模型推理及预测
import numpy as np
import tensorflow as tf
from tensorflow.keras.models import Sequential
from tensorflow.keras.layers import Bidirectional, LSTM, Dense, Flatten, TimeDistributed, Dropout
from tensorflow.keras.utils import to_categorical
from tensorflow.keras.callbacks import EarlyStopping, LearningRateScheduler
from tensorflow.keras.regularizers import l1_l2
# 加载数据集
train_x = np.load('训练集/new_train_x.npy')
train_y = np.load('训练集/new_train_y.npy')
test_x_A = np.load('测试集A/test_x_A.npy')
# 检查数据集是否有None值
assert not np.any(np.isnan(train_x))
assert not np.any(np.isnan(test_x_A))
# 预处理 - 标准化特征
mean = np.mean(train_x, axis=(0, 2), keepdims=True)
std = np.std(train_x, axis=(0, 2), keepdims=True)
train_x = (train_x - mean) / std
test_x_A = (test_x_A - mean) / std
# 预处理 - 转换标签为独热编码
train_y = to_categorical(train_y, num_classes=3)
# 定义学习率调度器函数
def lr_time_based_decay(epoch, lr):
decay_rate = 0.01
decay_step = 10
if epoch % decay_step == 0 and epoch:
return lr * decay_rate
return lr
# 创建LearningRateScheduler回调实例
lr_scheduler = LearningRateScheduler(lr_time_based_decay)
# 构建模型
model = Sequential()
# 使用Bidirectional层包装LSTM层来创建双向LSTM
model.add(Bidirectional(LSTM(64, return_sequences=True), input_shape=(train_x.shape[1], train_x.shape[2])))
model.add(Bidirectional(LSTM(64, return_sequences=False)))
model.add(Dropout(0.5)) # 添加dropout层
model.add(Dense(32, activation='relu', kernel_regularizer=l1_l2(l1=0.001, l2=0.001)))
model.add(Flatten())
model.add(Dense(3, activation='softmax'))
# 编译模型
model.compile(optimizer='adam', loss='categorical_crossentropy', metrics=['accuracy'])
# 设置早停法
early_stopping = EarlyStopping(monitor='val_loss', patience=10, restore_best_weights=True)
# 训练模型时使用callbacks
model.fit(train_x, train_y, epochs=100, batch_size=32, validation_split=0.1, callbacks=[early_stopping, lr_scheduler])
# 进行预测
predictions = model.predict(test_x_A)
predicted_labels = np.argmax(predictions, axis=1)
# 创建一个包含预测结果的 DataFrame
df_submit = pd.DataFrame({'id': np.arange(len(test_x_A)), 'label': predicted_labels})
# 保存 DataFrame 到 CSV 文件
df_submit.to_csv(f'submit.csv', index=False)
六、讨论区
不定期收录评论区好的想法或思路

















 945
945











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











