







C2-2.1 Mini-batch 梯度下降
1、什么是Mini-batch 梯度下降
起因:是我们有很大的一组训练样本,比如这里有5000万个训练样本,由于一次性对这些训练样本进行训练拟合模型,会发生训练速度过慢的情况 / 完全训练不了因为数据量太大了,对内存 GPU都是一个考验。这样就引出来mini-batch梯度下降算法。
解释:这个算法的原理正如名字一样min-batch:把特别大的数据集划分成一个个小撮,比如这里5000万条数据,我们每5000个样本(在min-batch中每组最少2000+)划分成一个组,把这个组称之为X{i},Y{i}。x(1)x(1000)称之为X{1},x(1001)x(2000)称之为X{2},y也同理,以此类推…在训练的时候,不使用for循环,而是使用线性代数的点乘方法,对每一组的1000个样本进行并行运算。提高运算速度。内存不足的情况。
核心思想:这种方法通过在内存容量和计算效率之间找到平衡,使得处理大型数据集成为可能,同时也利用了现代计算硬件的并行处理能力。
2、一个生动的解释:
想象你有一个非常大的书架,上面放着成千上万的书。你的任务是逐本检查这些书,并在每本书上做一些标记。如果你一次拿出所有的书来检查,那么你可能没有足够的空间放所有的书,而且这个任务也会显得非常压倒性。这就像是在深度学习中一次处理整个数据集。
所以,你选择了一个更有效的方法:一次只拿出书架上的一小部分书,比如说10本,来进行检查和标记。处理完这10本书之后,你再拿出接下来的10本。这样,你一次只处理少量的书,这样既节省空间,又使得任务更加可管理。这就像是mini-batch梯度下降法,其中你一次只处理一小部分(一个mini-batch)的数据。
现在,来到了“并行处理”和“向量化”的部分。当你在处理这10本书的时候,你可以同时为这10本书做标记,而不是一本一本地去做。这就是向量化——你一次性处理了一个小批次的书籍,而不是一个接一个。在计算机中,这样的操作可以通过矩阵和向量来实现,而且现代计算机硬件(比如GPU)非常擅长同时处理这样的任务。
所以,总结一下:
- 一次处理一个mini-batch:这就像是一次从书架上拿下一小部分书来检查。
- 向量化和并行处理:这就像是同时为这一小部分的书做标记,而不是一本本单独处理。
3、学习过程的思想纠正
3.1 并行处理
- **并行处理指的是:**对每一组的5000条数据进行一起的并行处理。
而不是:说对分成的1000组,这1000个组同时处理
3.2 一次处理一个
刚学习的时候有一个误区:一次处理一个???不是说min-batch 梯度下降是提高效率的吗,为什么又一次处理一个???那还能提高效率了吗?
- 一次处理一个mini-batch:我们这里划分了1000个组,每次迭代迭,是一个组一个组进行的,每次迭代的结果是得到这一个组的最佳结果。在内存容量和计算效率之间找到平衡。
与一次处理整个数据集(如在批量梯度下降中)相比,使用mini-batches减少了内存需求,因为每次只加载一个mini-batch的数据到内存中。这样不仅减少了内存压力,还可以更有效地利用缓存,提高数据访问速度。
4、可视化图的解释
4.1 “等高线”图
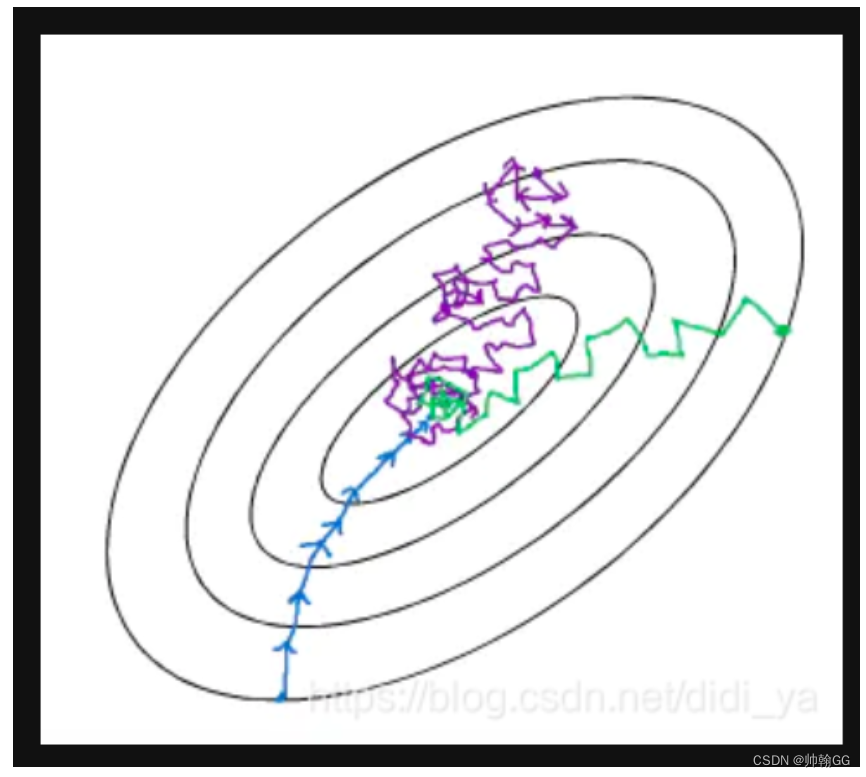
蓝色:为 batch 梯度下降,即 mini batch size = m,
紫色:为 stochastic 梯度下降,即 mini batch size = 1,
绿色:为 mini batch 梯度下降,即 1 < mini batch size < m。
-
**传统的梯度下降算法:**遍历全部数据集算一次损失函数,然后算函数对各个参数的梯度,更新梯度。这种梯度下降法叫做这称为Batch gradient descent(BDG)。我们知道 Batch 梯度下降的做法是,在对训练集执行梯度下降算法时,必须处理整个训练集,然后才能进行下一步梯度下降。当训练数据量非常多时,每更新一次参数都要把数据集里的所有样本都看一遍,虽然收敛性能好,但是一次迭代需要等待多长时间,速度慢,会极大的降低训练速度。
-
随机梯度下降,stochastic gradient descent(SDG),每看一个数据就算一下损失函数,然后求梯度更新参数。这个方法速度比较快,但是永远不会收敛,可能在最优点附近晃来晃去,无法收敛。两次参数的更新也有可能互相抵消掉,造成目标函数震荡的比较剧烈。
-
因此,为了克服两种方法的缺点,现在一般采用的是一种折中方法,mini-batch gradient decent(在内存容量和计算效率之间找到平衡)。这种方法把数据分为若干个batch,按batch来更新参数,这样,一个batch中的一组数据共同决定了本次梯度的方向,下降起来就不容易跑偏,减少了随机性。另一方面因为批的样本数与整个数据集相比小了很多,计算量也不是很大。
4.2 梯度下降图
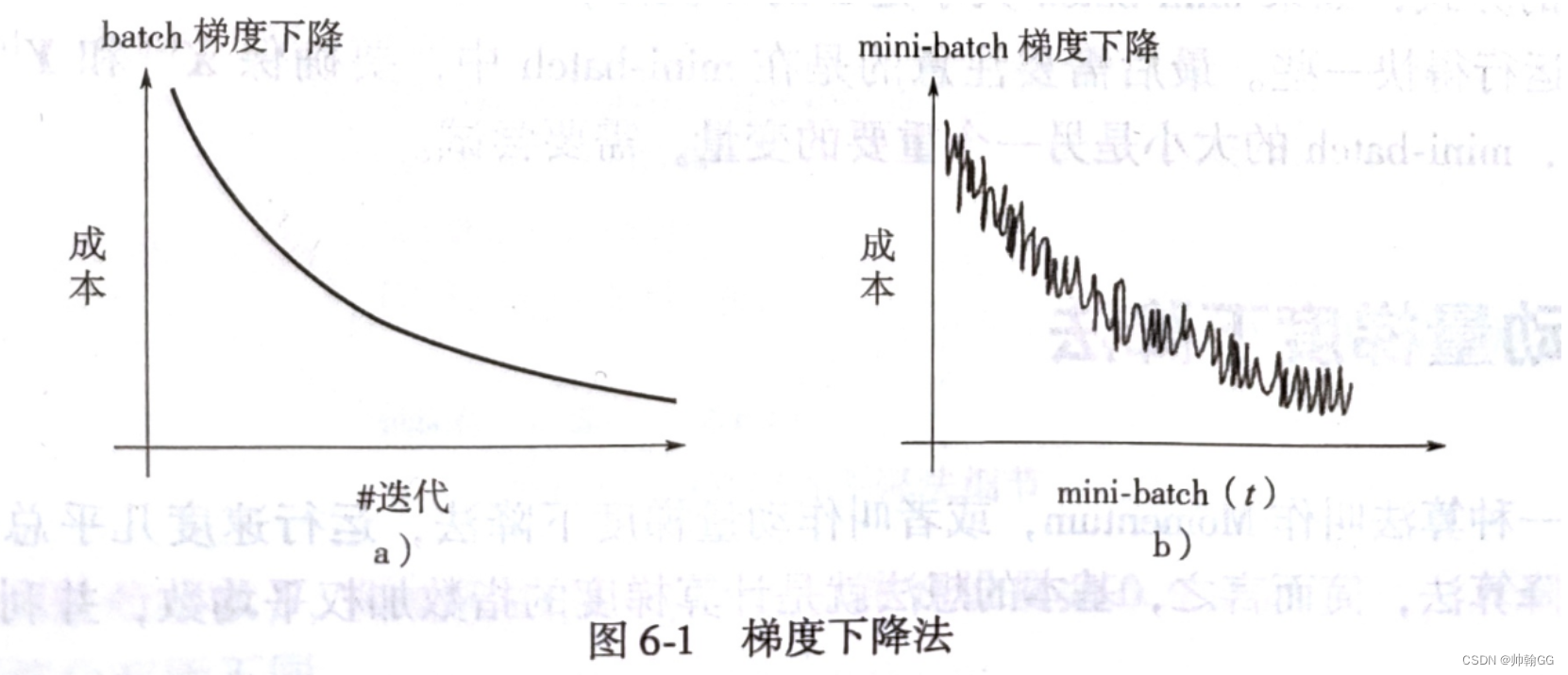
- 图一:是batch 梯度下降:虽然性能好,但是内存 与 时间消耗比较大。
- **图二:是mini batch 梯度下降:**总体都是呈下降的趋势的,但是为什么会呈波浪形下降的???
- 是这样的:mini-batch梯度下降学习的过程是一组(比如一组有5000个数据)一组的学习,因为我们的内存是有限的,使用mini-batch就是在内存 与 效率之间找到权衡,因为每次只加载一个mini-batch的数据到内存中,每次学习完一组数据后,拟合曲线,然后再学习下一组。
- 这样就会出现一个问题:有的数据集学习的比较好,有的学习的不是很好,有噪音:
- 例如学习一个图片:这个图片我们分成3*3大小,学习识别一个鸟,学习到一个组X{1}(想象成是一个第一个小方块),学习到的是鸟嘴。下一次识别图片的时候,会把鸡也当做鸟。这样就叫噪音
- 学习到第二个小方块,X{2},学习到了鸟头了,这样模型J的损失函数值会更低了,学习的效果会更好了…以此类推。
5、【书籍参考】


















 1808
1808











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









