






长此以往:投资者情绪可能虚假地预测异常回报
Robert F. Stambaugh, Jianfeng Yu, and Yu Yua
2014年2月16日
摘 要
伪回归偏差解释了在股票回报异常中所观察到的投资者情绪作用的可能性极小。我们用Stambaugh, Yu和Yuan(2012)在回归分析中模拟的持续序列来替代投资者情绪,他们发现高情绪后,多头-空头异常利润更高,这完全是由于短线。在2亿个模拟回归器中,我们发现没有一个能像投资者情绪那样强有力地支持这些结论。关键是异常之间的一致性。在上述研究中检查的11个异常中,仅获得回归系数的预测符号,对于每43个模拟回归器仅发生一次。
JEL分类:G12, G14, C18
关键词:投资者情绪、异常、伪回归因素
介 绍
当推断高度自相关的变量可以预测资产回报时,需要谨慎。一个原因是“伪”回归因素的可能性:如果未观测到的资产预期回报是时变的和持久的,那么另一个与回报没有真实关系的持久变量似乎可以在有限的样本中预测回报。Ferson, Sarkissian和Simin(2003)证明了这些回归的潜力如何使评估收益预测的任务复杂化,并解释了其潜在机制如何与Yule(1926)和Granger和Newbold(1974)分析的伪回归问题相关。Ferson等人还解释了数据挖掘如何与伪回归器问题相互作用。当存在伪回归量的可能性时(即。(即持续时变的预期收益),数据挖掘产生了特别大的机会,可以找到看似预测收益,但实际上只是虚假预测的序列。
更强的动机是将系列剧作为一个回报预测器,而更弱的动机是担心它的预测能力是虚假的。一个具有强大先验动机的指标是市场范围内的投资者情绪。至少早在凯恩斯(1936),许多作者就考虑过这样一种可能性:大量受情绪驱动的投资者的存在,可能会导致价格偏离基本价值,从而创造出纠正这种错误定价的未来回报的一部分。Baker和Wurgler(2006)以及Stambaugh,Yu和Yuan(2012)等人发现,投资者情绪和/或消费者信心显示出一种预测不同类别股票和投资策略回报的能力。这些研究还细化了投资者情绪的先验动机作为预测因素。例如,Baker和Wurgler(2006)认为,在难以估值的股票中,情绪应该发挥更大的作用。为了支持这一假设,他们发现情绪表现出更强的能力来预测小型股票、年轻股票、高波动性股票、无盈利股票、无派息股票、极端增长股票和低迷股票的回报。Stambaugh,Yu,and Yuan(2012)假设,当市场整体情绪与Miller(1977)关于卖空障碍的影响的观点相结合时,高情绪导致的定价过高比定价过低更有可能因为情绪低落。他们的结果支持了这一论点,因为情绪可以预测大量基于异常的多/空策略的短线获利,而情绪却无法预测长线获利。
尽管先前的动机是投资者的情绪表现为一个异常回报的预测器,但人们可能会担心,情绪只是一个虚假的预测器。例如,诺维-马克思(Novy-Marx,2013b)的研究结果可能会引发这种担忧,他报告称,各种异常的回报显然可以通过看似不可能的变量(如太阳黑子和行星位置)来预测。本研究评估了投资者情绪作为预测指标的观察能力可以通过假回归器实现的几率。我们关注的是在多个返回序列和假设中一致性的作用。为了理解一致性的价值,假设多个投资组合的真实预期回报具有一些独立的变化,但每个预期回报与投资者情绪的真实相关性具有相同的符号。投资组合的数量越多,就越难找到一个虚假的回归指标,该回归指标将在整个投资组合中始终显示出与投资者情绪相当的有限样本预测能力。我们探讨一致性作用的背景是Stambaugh,Yu,andYuan(2012)。该研究调查了11种不同的异常情况,并在这些异常情况下发现了一致的结果,支持了三个假设:(i)当前情绪与未来多/短线收益差之间存在正相关关系;(ii)当前情绪与未来短线收益之间存在负相关关系;(iii)当前情绪与未来长期收益之间没有关系。我们只是问,这些假设有多大可能被用来代替投资者情绪的随机产生的虚假回归分析强有力地支持。
在2亿个模拟回归器中,我们发现没有一个回归器联合支持Stambaugh, Yu, and Yuan(2012)的三个假设像投资者情绪一样强烈。如果只看三种假说中的一种,成功的几率仍然相当大。例如,第一种假设——情绪与多/空回报差之间存在正相关关系——在每28500个模拟回归量中就会出现一次相对强大且一致的支持。对于第二个假设——情绪与短期回报之间的负相关——每105,000个回归变量中就会出现一次类似支持。如果我们不考虑任何强度(t统计),而只是看看前两个假设所指示的回归系数的符号,即使如此,每43个模拟回归器中也只有一个达到了与投资者情绪所显示的一致.
经验设定与模拟结果
我们在这里分析的实证设置主要集中在Stambaugh, Yu, and Yuan(2012),下文SYY报告的主要回归结果集。该研究估计了回归,
在Ri,t异常策略在第t个月的超额回报是长腿,短腿,还是差St−1 Baker和Wurgler(2006)月末的投资者情绪指数水平t-1和MKTt,SMBt,HMLt是Fama和French(1993)定义的三个股市因素在第t个月的收益。SYY检查了之前文献中记录的11种异常:
1.失败概率(Campbell,Hilscher,and Szilagyi,2007)
2.痛苦(Ohlson,1980)
3.净股票发行(Ritter,1991年,Loughran和Ritter,1995年)
4.综合股票发行(Daniel and Titman,2006)
5.应计总额(Sloan,1996)
6.净经营资产(Hirshleifer,Hou,Teoh,and Zhang,2004)
7.势头(杰加迪什和提特曼,1993)
8.毛利率(Novy-Marx,2013a)
9.资产增长(Cooper,Gulen,and Schill,2008)
10.资产收益率(Fama and French, 2006, Chen, Novy-Marx, and Zhang, 2010, Wang and Yu, 2010)
11.投资对资产(Titman, Wei, Xie, 2004, Xing, 2008)
与SYY一样,除异常(1)的数据开始于1974年12月外,其余异常(2)和(10)的样本期为1965年8月至2008年1月,异常(2)和(10)的数据开始于1972年1月。对于每个异常,SYY使用基于异常变量的十分位1和10来检查多/空策略,其中长腿是平均回报率最高的十分位。SYY还研究了一种组合策略,该策略在任意一个月构建的多空策略中持有相同的头寸。
方程(1)中的兴趣系数为b。SYY(参见表5)报告了在与该研究中探索的三个假设相关的三组回归中,对11个异常中的每一个以及组合策略估计b的结果。对于第一个假设,Ri,t 长短期收益差,与估计值ˆb有预测吗?
所有11个异常都是积极的信号。ˆb的t统计量,基于White(1980)的异方差一致性标准误差,在个体异常范围内从0.22到3.38不等,在组合策略中等于2.98。对于第二个假设,Ri,t 是短期回报,ˆb对所有11个异常都有预测的负号。单个异常的t统计量范围为−1.11至−3.58,组合策略的t统计量为−3.01。第三个假设,Ri,t 是长腿回报,预测b应该是大约为零。在这些回归分析中,ˆb的符号在个别异常中是混合的(7个正的,4个负的),t统计量从-2.07到1.44,组合策略的t统计量为0.15。当综合观察估计的36个回归(每个假说12个)时,SYY的结果似乎为所有三个假说提供了相当有力的支持。
在这项研究中,我们要问一个虚假的预测器有多大可能像投资者情绪一样有力地支持SYY的三个假设。我们随机生成一个预测器序列xt,用它来代替St,然后对上述36个相同的回归方程(1)重新估计。这个过程要重复2亿次。每个预测因子序列xt为一阶自回归过程,具有正态创新,自相关等于0.988,等于St 在Marriott and Pope(1954)和Kendall(1954)中进行了一阶偏差校正。
2.1 t统计量联合比较
判断x是否t 和S一样强烈地支持给定的假设t,我们问,通过异常联合观察ˆb的t统计量是否与使用S产生的假设一样有利t.在第一个假设的情况下确定这个条件,对于Ri,t 定义t-Si为11个异常中的ˆb的第i高t统计量,St 使用。类似地,将t-xi定义为11个异常中ˆb的第i高t统计量t 使用。设tSC表示组合策略的t统计量t ,令txC表示当xt 使用。那么xt 支持第一种假设(b>0)t if t-xi≥t-Si for i=1,…,11 and txC≥tSC。
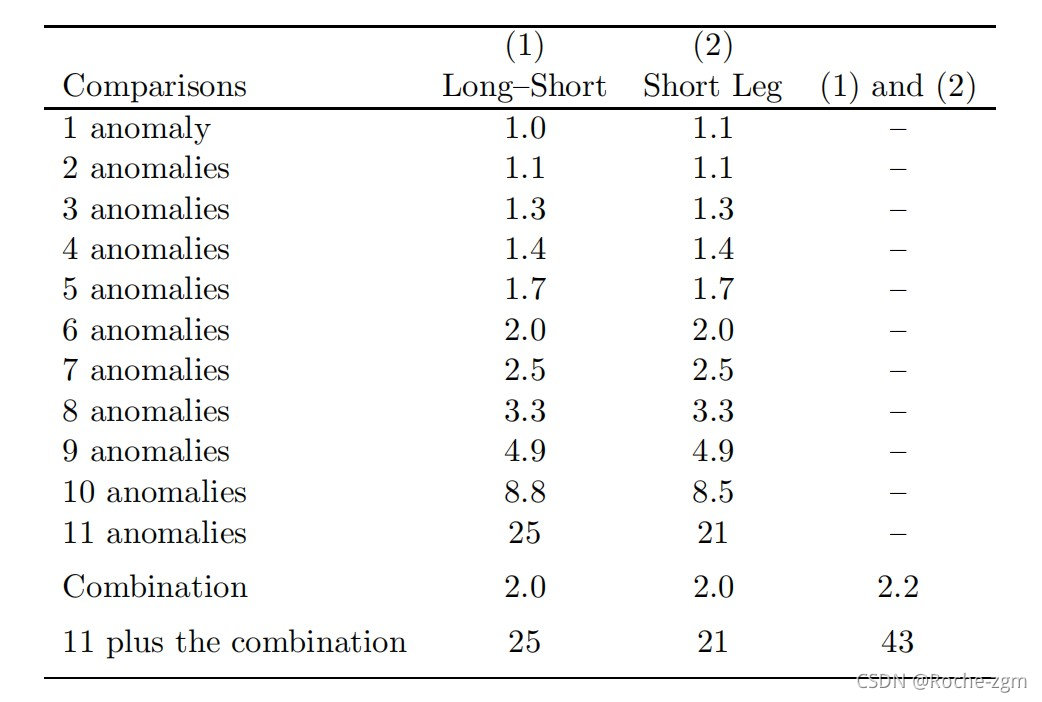
每28500人中只有一次产生xt 级数,平均来说,是第一个被x强烈支持的假设t 的年代t.表1第一列的最后一行报告了这个结果。其他的行显示较少满足上述不等式的频率。例如,同一列的第一行报告11中至少有一个在生成的每22个x中,t-xi的值超过对应的t-Si一次t系列。沿着列向下移动时,值的急剧增加说明了在多个异常之间要求一致性的显著效果。只要找到xt 当超过一半的t-xi值超过相应的t-Si值时,每833 x只发生一次t 系列。倒数第二行表示,对于组合策略,t统计量是用x得到的t 超过用S得到的t 每67季一次。
当考虑第二个假设时,伪回归量的可能性变得更大,正如我们从表1的第二列中看到的那样。这个假设得到了x的有力支持t因为它是由St每105,000个系列中只有一次。这里的不等式条件和之前的正好相反,因为Ri,t现在是短期回报,而预测是b<0。设tSi表示ˆb的第i个最低t统计量,当St,设txi表示当xt使用。那么xt和S一样有力地支持第二种假设t如果txi≤tSi for i=1,…、11、txC≤tSC。与第一个假设一样,要求各独立回归的一致性的影响是巨大的。然而,即使是使用组合策略的单次回归,得到的负t统计量也大于使用S得到的负t统计量t每次只发生一次。
第三个假设是b = 0。为了让这个假设得到随机生成的x的有力支持t 因为它是由St,则需要xt−1 像S一样始终虚弱t−1 它预测R的能力i,t,现在定义为长腿返回。对于这种情况,设|t|Si表示S时,t统计量绝对值第i小的t统计量t ,并设|t|xi表示当xt 使用。那么xt 支持第三种假说t 如果|t|xi≤|t|Si for i = 1,…、11、|txC|≤|tSC|。
当仅仅考虑第三个假设时,伪回归器出现的几率就会提高,但它们仍然相当长。当要求与回归量没有明显的关系时,我们再一次看到一致性的效果。每919个随机生成的x中只有一个t 我们发现一个连续的不成功的预测长期的回报。
当然,故事不会以简单地孤立地考虑这三个假设而结束。正如SYY所解释的那样,这些假设是一系列联合影响的结果,是通过将市场整体情绪波动的存在与Miller(1977)的观点相结合而发展起来的,后者认为卖空障碍使得定价过高比定价过低更为普遍。最后两列报告伪回归器x的频率t 支持一个以上的假设,如St,每个人都能得到相当的支持。
假设的判断与之前一样。在46.8万个回归分析中,只有一个虚假回归分析像投资者情绪一样强烈支持前两个假设。当我们寻找一个能像投资者情绪一样有力地支持所有三个假设的伪回归因素时,我们实际上在2亿个模拟序列中没有发现任何回归因素。当使用组合策略将练习限制在单一回归时,我们仍然发现,每6580个假回归中,只有一个回归同时支持这三个假设,与投资者情绪一样强烈。
2.2 Joint-comparison 基准
正如上面的分析所说明的,多个异常和假设的结果的一致性使得这些结果特别不可能由虚假的回归器产生。虽然同时进行的联合比较揭示了一致性的重要性,但它们也会使解释结果的强度变得不那么直接。表1中的每个数字本质上给出了在“零假设”(一个虚假的预测)下获得一个样本结果的概率的倒数,该样本结果至少与使用情绪系列S实际观察到的结果一样极端t.然而,当比较涉及到一个统计向量,而不是单一统计量时,相应的概率可能相当低,即使样本结果远没有实际观察到的样本结果极端。如果相当不极端的结果在零值下的概率也很低,那么就很难解释与比实际结果更极端的结果相关的低概率。
在基准值的存在下,解释表1中的值变得更容易,基准值反映了当实际情绪系列S时人们对表1中的值的期望是什么t 被一个真正虚假的预测器所取代。表2包含了这样的基准值,通过替换基于情绪系列S的t统计量来计算t 基于伪回归量y的t统计量t.也就是说,而不是列出虚假回归量x的频率t 支持SYY假设和实际的S序列t,我们将假回归量x的频率制成表格t 还有另一个伪回归量y吗t.一个新的级数yt 对x系列的每一幅画都画出来了。
例如,考虑伪回归器x的频率t 在所有异常情况下,联合支持三个SYY假设,其强度不亚于实际回归量St.回想一下表1,我们发现这个频率小于2亿分之一。当年代t 被一个伪回归量yt,我们可以从表2中右下角的条目中看到一个伪回归量xt 在大约71个样本中,与y一样强烈支持SYY的三个假设t.换句话说,表2的71值是解释表1的2亿值的基准:它是人们期望的表1值,如果St 真的是假的。将表1的值除以表2的值可以得到前者的“有效”值。例如,用2亿除以71得到的有效值约为280万——仍然非常大。表1中的其他值也可以与表2进行类似的比较。例如,回想一下表1,46.8万个虚假回归器中只有一个像S一样强烈支持前两个SYY假设t.表2中对应的基准值是4.4,用46.8万除以4.4仍然得到超过106000。总的来说,我们看到,虽然联合比较问题很重要,但根据表2基准来解释表1的值仍然可以得出总体结论,即如果St 是一个虚假的回归量。
2.3 额外的比较
要判断一个虚假的回归指标对SYY假设的支持程度是否与实际的投资者情绪系列同样强烈,我们必须定义“支持程度同样强烈”。虽然表1和表2中使用的定义似乎是捕获异常结果一致性的合理方法,但当然还有其他定义。例如,我们可以检查给定假设的k个最不有利的t统计量,比较x产生的t统计量t 使用S获得的t.为说明这一点,设k = 1并考虑第一个假设,该假设预测b > 0当Ri,t 是多空收益差。由S产生的最小t统计量t 在11个异常中等于0.22,小于1个xt 每50个序列中产生的最小t统计量大于这个值。对于第二个假说,它预测当Ri,t 是短线回报,用St 是-1.11,只有一个xt 每2300个样本中产生的最小统计值小于-1.11。现在让k = 2,注意由S产生的倒数第二低的t统计量t 对于第一个假设等于0.76。只有一个xt 每163个序列中有一个最小t统计量大于0.22,第二个最小t统计量大于0.76。对于假设2,只有一个xt 10,000中最弱的两个统计量比使用S的两个最弱的统计量更有利于假设t.继续执行额外的k值和剩下的第三个假设将生成与表1格式相同的表,最后三行中的条目与表1中的条目相同,前十行中的条目更大,对应更长的概率。因此,比较个别异常中最弱的结果将传递与表1类似的消息,甚至更强烈。
当然,对最弱的结果进行联合比较会引起前面小节中讨论的相同的基准问题。也就是说,在比较最弱结果的基础上得到表1的另一个版本,可以同时得到相应的表2的最弱结果版本。例如,当k = 1时,上面报告的第一个和第二个假设的替代表1值50和2300除以表2替代版本中出现的值,就有相应的“有效”值25和1150。同样,当k = 2时,表1中报告的163和10,000的备选值对应的有效值为70和4367。和以前一样,在联合比较的背景下,低频仍然看起来很低。
在某种程度上捕获异常一致性的另一种方法是简单地比较中值t统计量。例如,在11个异常个体以及组合策略中,第一个假设的中值t统计量等于2.41t,一个xt 每1650个中值就产生一个如此大的t统计量。对于第二个假设,中位数t统计量使用St 等于-2.57,还有一个xt 每1186个变量中就会产生一个负幅度较大的中值t统计量。只有一个xt 每7103个中值产生的t统计量同时有利于两个假设。对于第三个假设,用S求绝对t统计量的中位数t 是0.46。一个xt 每15个中值中值绝对t统计量那么低,但只有一个xt 在562,000个样本中,他们这样做的同时,产生的中位数统计数据与使用St.如果按照前面讨论的相同方式对联合比较问题进行调整,这种结果的有效频率仍然低于12.3万人中有一人。
异常之间的平均t统计量很少说明异常之间的一致性。然而,一个虚假的回归分析似乎不太可能产生甚至相当有利的平均t统计量。例如,对于第一个和第二个假设,syy报告的11个异常和组合策略的t统计数据的平均值分别是2.14和-2.38。对于第三个假设,syy报告的t统计量的平均绝对值是0.69。一个平均t统计量强烈支持第一个假设(即。,大于2.14)是由一个x产生的t 每554个。一个平均t统计量有力地支持第二种假设(即。,小于-2.38)发生于一个xt 每1393人。同时支持两种假设的平均t统计量每2412次出现一次。一个xt 同时产生对第一个的支持与第三个假设同样有利的两个假设——平均绝对t统计量小于0.69——每237,000个假说中只出现一次。调整联合比较的问题后,有效频率仍低于53000分之一。
最后,相当不可能的是,一个虚假的回归器在所有异常情况下给出ˆb的预测信号。表3报告了伪回归器给出长-短差(第一个假设)和短腿回报(第二个假设)异常的预测符号的频率。对于第一个假设,每25个伪回归量中就有一个给出了所有11个异常的预测正信号。对于第二个假设,所有11个异常的预测负号的频率是每21个中有一个。在每43个随机生成的回归量中,一个虚假的预测器只会产生一次。
3.结论
观察到的投资者情绪在股票回报异常中的作用,似乎不太可能由一个虚假的回归指标来填补。在2亿个模拟回归器中,我们一个也没有找到。这些非常渺茫的可能性——似乎并不比一次性赢得强力球头奖的可能性好多少——反映了投资者情绪在SYY三个假设的多种异常情况下产生结果的一致性。同时支持SYY假说本身就很重要,因为即使将所有异常因素组合成单一的多/空策略,支持这些假说的虚假回归因素与投资者情绪一样强烈的几率也只有1/6580。然而,正是个别异常的一致性,为清除虚假回归指标提出了最大的障碍,以发挥投资者情绪的作用。
表 1 获得一个预测器所需的随机生成预测器数量,该预测器产生的结果与投资者情绪一样强烈
这个表报告了随机生成的预测器x的频率的倒数t 会产生与投资者情绪一样强烈的结果t 当xt 取代年代t 的回归,在Ri,t t月的超额回报是长腿,短腿,还是差St Baker and Wurgler(2006)和MKT的投资者情绪指数水平是多少t, SMBt和xmlt是Fama和French(1993)定义的三个股票市场因素。预测xt 为一阶自回归,自相关系数为0.988,St.设t-Si表示当S时11个异常中ˆb (b的估计值)的第i高t统计量t,并让-txi表示当xt 使用。设tSi表示ˆb的第i个最低t统计量,当St,设txi表示当xt使用。设|t|Si表示当St,并设|t|xi表示当xt使用。j异常列反映满足以下条件的频率:
在长-短列中,在i = 1,…,11中,-txi≥t-Si发生了至少j次。
在短腿列i=1,…,11中,txi≤tSi至少出现j次。
在长腿列i=1,…,11中,|t|xi≤|t|Si至少出现了j次。
“组合”行反映了当R时,模拟预测器产生满足上述不等式的t统计量的频率i,t是11种异常策略的同等权重组合。最后一行反映了11个异常满足上述不等式的频率以及组合策略。最后两列反映了在前一列中共同满足不等式的频率。表 2 获得一个预测器所需的随机生成预测器的基准数量,该预测器产生的结果与另一个随机预测器一样强
这个表报告了随机生成的预测器x的频率的倒数t 产生的结果与另一个随机生成的预测器y一样强t当xt和yt取代年代t的回归,
在Ri,t t月的超额回报是长腿,短腿,还是差St Baker and Wurgler(2006)和MKT的投资者情绪指数水平是多少t,SMBt和xmlt是Fama和French(1993)定义的三个股票市场因素。预测xt和yt为一阶自回归,自相关系数为0.988,St.让t¯yi表示在11个异常中,ˆb (b的估计值)的第i高t统计量t,并让t¯xi表示当xt 使用。设tyi表示ˆb的第i个最低t统计量t,设txi表示当xt使用。设|t|yi表示当y时第i小的t统计量的绝对值t,并设|t|xi表示当xt使用。j异常列反映满足以下条件的频率:
-txi≥t-yi在I=1,…,11这一长一短列中发生了至少j次。
在短腿列I=1,…,11中,Txi≤tyi至少出现j次。
在长腿列I=1,…,11中,|t|xi≤|t|yi至少出现了j次。
“组合”行反映了当R时,模拟预测器产生满足上述不等式的t统计量的频率i,t 是11种异常策略的同等权重组合。最后一行反映了11个异常满足上述不等式的频率以及组合策略。最后两列反映了在前一列中共同满足不等式的频率。
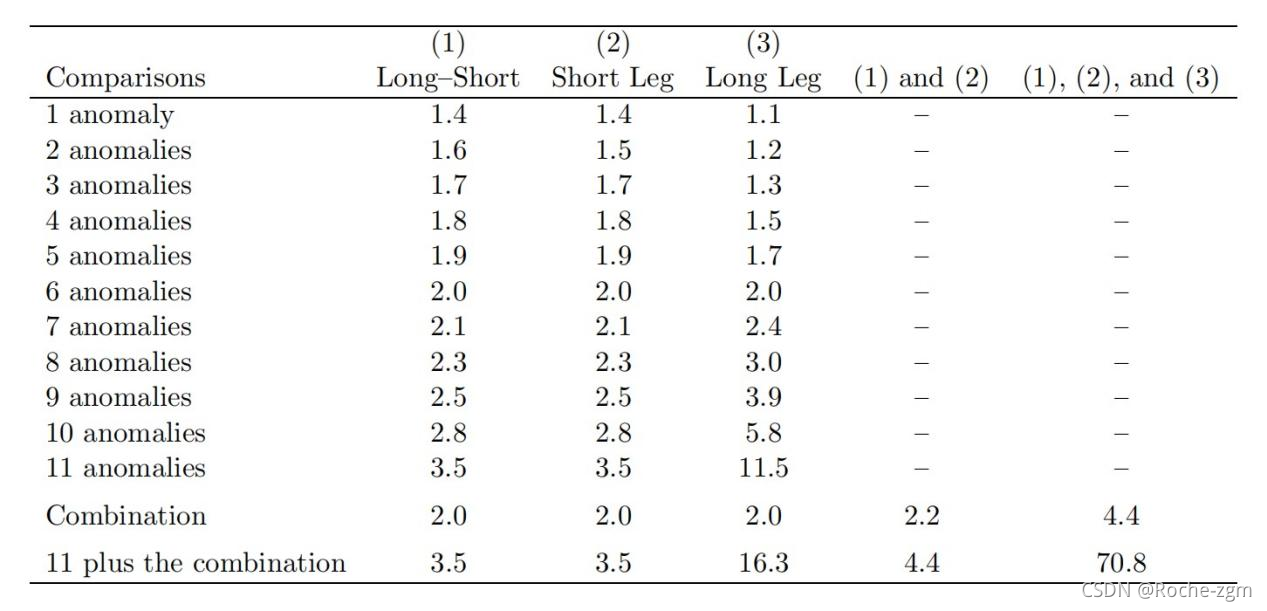
表 3 获得一个具有正确符号的预测器所需的随机生成预测器数量
这个表报告了随机生成的预测器x的频率的倒数t产生b的估计值和x时的预测符号t取代年代t的回归,
在Ri,t t月的超额回报是长腿,短腿,还是差St Baker and Wurgler(2006)和MKT的投资者情绪指数水平是多少t,SMBt和xmlt是Fama和French(1993)定义的三个股票市场因素。预测xt 为一阶自回归,自相关系数为0.988,St.
j异常的行反映了模拟预测器对至少j个具有预测符号(长-短列为正,短腿列为负)的异常产生b估计值的频率。“组合”行反映了当R时,模拟预测器产生带有预测符号的b估计值的频率i,t是11种异常策略的同等权重组合。最后一列反映了通过前一列联合获得预测符号的频率。



















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











