






前言
为什么要学习数据库的信息筛选?当我们的应用需要对数据库的数据进行筛选的时候,一般有两种情况,一种是在数据库发送过来之前就筛选好信息,发送过来的就是处理后的信息;另一种是让数据库把所有信息都发过来再进行处理。对于前者来说,提前在数据库端处理好信息,可以精简化所需信息,减少应用的整体宽带,特别是当在线用户特别多的时候,数据库可能面临特别大的负担,这样的优化就非常有必要了
strapi的数据层级
接触过strapi的朋友应该知道,strapi的数据词条有以下几种:链接: link.
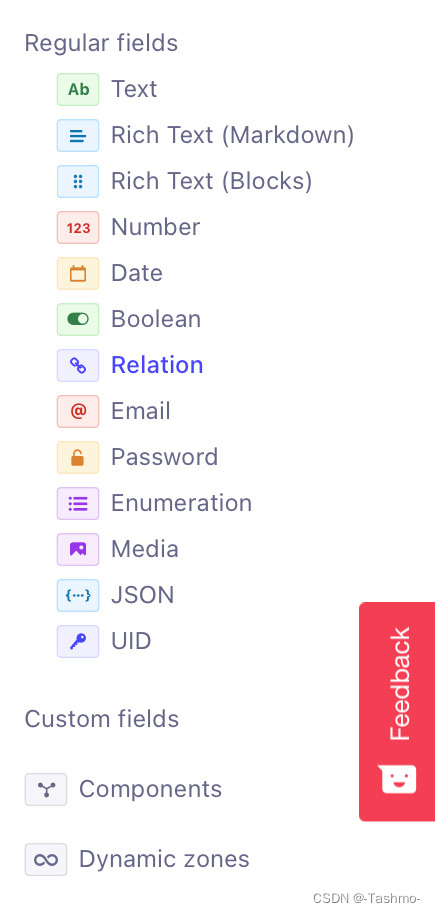
假设我们的这项内容有以下三个数据:
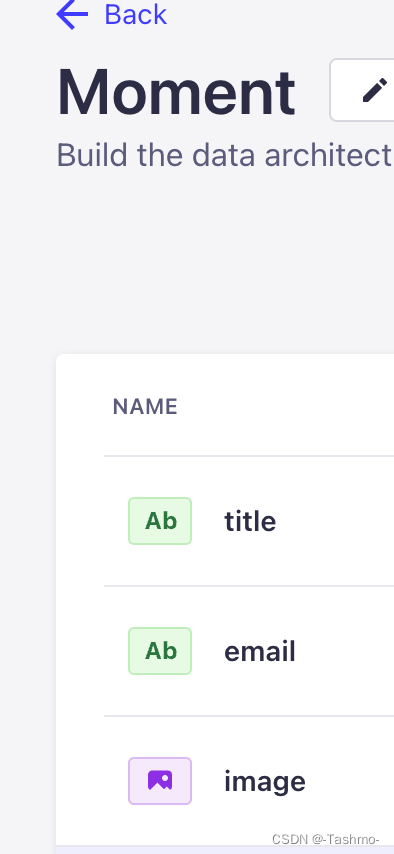
当我们通过url访问数据库对它进行查看时,例如:
http://xxx.xxx.xxx.xxx/api/moments
response
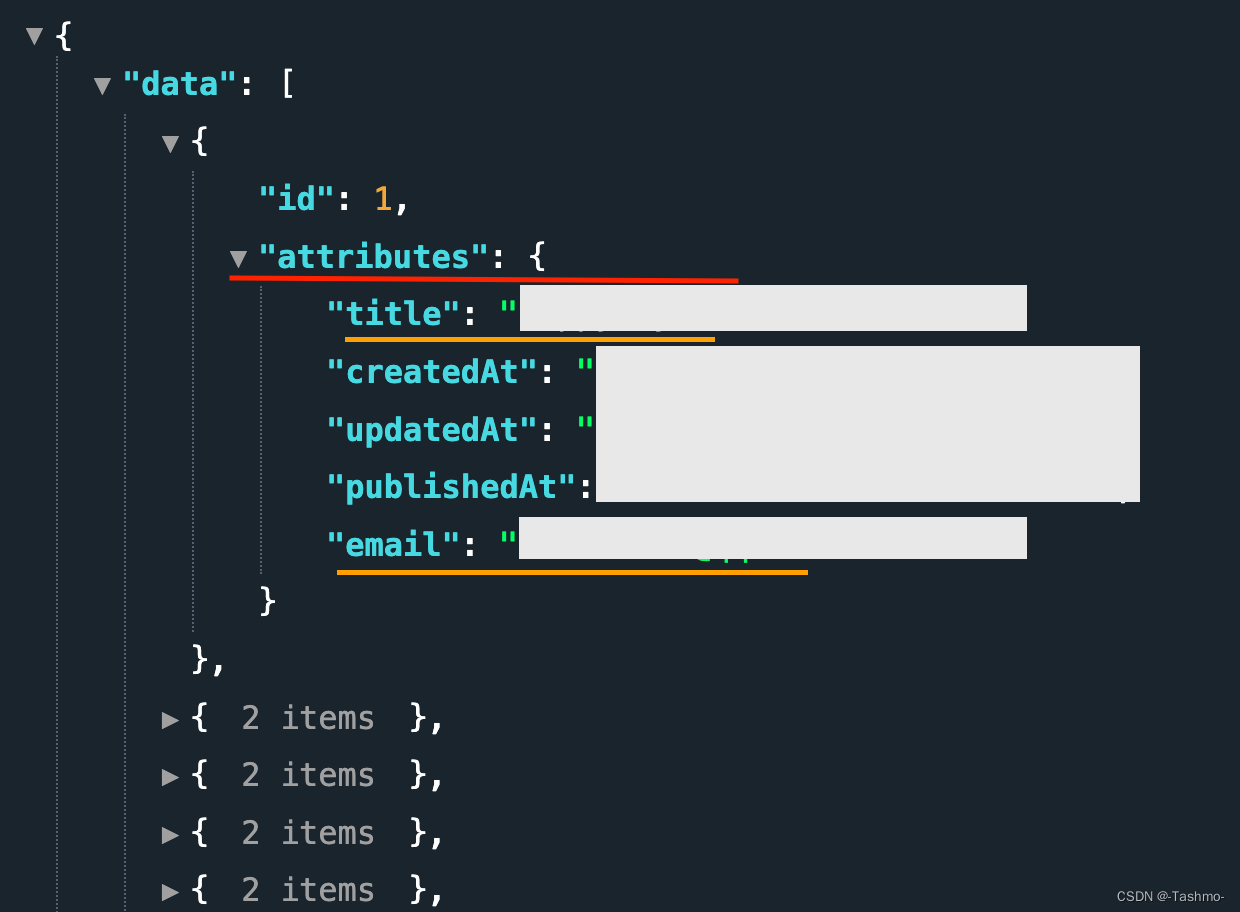
可以看见只有title和email被访问到了,而image则访问不了,这是因为在strapi中只有以下类型词条可以被直接访问到(参考文章:
1. string types: string, text, richtext, enumeration, email, password, and uid,
2. date types: date, time, datetime, and timestamp,
3. number types: integer, biginteger, float, and decimal,
4. generic types: boolean, array, and JSON.
也就是这些词条:

其他的内容被strapi默认隐藏了,如果你要访问,就要在url路径中使用到populate 了
populate的使用
参考populate使用文章
populate 的本意是填充,在数据库中就意味着填充词条,也就是将没有的内容展现出来。
上面给的文章中介绍的很全面了,这里就简单说几个常见用法:
查看全部词条
populate=*
http://xxx.xxx.xxx.xxx/api/moments?populate=*
查看一个词条
populate[0]=a-relation-name
http://xxx.xxx.xxx.xxx/api/moments?populate[0]=userinfo
查看多个词条
populate[0]=relation-name&populate[1]=another-relation-name&populate[2]=yet-another-relation-name
http://xxx.xxx.xxx.xxx/api/moments?populate[0]=userinfo&populate[1]=image&populate[2]=likes
查看两层词条
populate[first-level-relation-to-populate][populate][0]=second-level-relation-to-populate
http://xxx.xxx.xxx.xxx/api/moments?populate[userinfo][populate][0]=name
tips: 如果查看的数据层级和数量比较繁多复杂,手写url可能不是一个很好的方法,建议使用stapi提供的路径转换工具:interactive query builder tool
filters的使用
filters就是用来筛选数据库中符合条件的数据,比如筛选一项内容中邮箱(email)都是 Tashmo111@qq.com 的数据,其他的不要。
参考filters教程
这里我就讲一个filters最简单最常用的用法:
filters[field][operator]=value
http://xxx.xxx.xxx.xxx/api/moments?filters[email][$eq]=Tashmo111@qq.com
这里¥eq是等于的意思,操作符operator还有很多可以对数据进行不同的筛选判断,完整表单都放在文章链接了,请自取。
结语
最后,如果看了本文还有许多疑惑的,我这里推荐一个视频和教程,个人认为讲的比较好,可以先看完视频再去看文章,因为文章就是对视频内容的解析。















 2143
2143











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









