







An Efficient Deep Reinforcement Learning Algorithm for Solving Imperfect Information Extensive-Form Games (一种求解不完全信息可拓形式博弈的高效深度强化学习算法)
摘要
在大规模不完全信息可拓形式博弈imperfect information extensive form games (IIEFGs)博弈中,学习纳什均衡Nash equilibrium (NE)的最流行方法之一是反事实遗憾最小化的神经变体neural variants of counterfactual regret minimization(CFR)。CFR是**跟随正规化领导者 FTRL(Follow The-Regularized-Leader)**的一个特例。
在每次迭代中,CFR的神经变体通过估计的反事实遗憾来更新代理的策略。然后,他们使用神经网络来近似新策略,这会产生近似误差。这些近似误差将累积,因为迭代t处的反事实遗憾是使用代理的过去近似策略来估计的。这种累积的近似误差导致较差的性能。
为了解决这种累积的近似误差,我们提出了一种新的FTRL算法称为FTRL-ORW,它不利用代理的过去的策略来选择下一个迭代策略。更重要的是,FTRL-ORW可以**通过从博弈中采样的轨迹来更新其策略,**这适合于解决大规模的IIEFG,因为在这样的游戏中,为每个信息集采样多个动作太昂贵了。
然而,仍然不清楚当在迭代t处仅显示这样的采样轨迹时,使用哪种算法来计算FTRL-ORW的下一迭代策略。为了解决这个问题并将FTRL-ORW扩展到大规模的博弈,我们提供了一种称为Deep FTRL-ORW的无模型方法,该方法使用无模型最大熵深度强化学习来计算下一次迭代策略。在two-player zero-sum IIEFGs上的实验结果表明,Deep FTRL-ORW显著优于现有的无模型神经方法和OS-MCCFR。
不完全信息可拓形式博弈(英语:Imperfect Information Extensive-Form Games,简称IIEFG)
是一种在顺序决策框架中捕捉参与者之间策略交互的博弈模型,其中参与者对博弈状态的信息不完全。与完全信息扩展形式的游戏相比,在完全信息扩展形式的游戏中,玩家对过去的行为和游戏状态有完整的了解,IIEFG允许隐藏或私人信息,这些信息对某些玩家来说是未知的。在IIEFG中,游戏被表示为树状结构,其中每个节点表示玩家的决策点,边表示玩家可以采取的行动。然而,与完美信息博弈不同的是,一些节点可能是“信息集”而不是单个决策点。信息集是决策点的集合,这些决策点由于其不完整的信息而无法被玩家区分。玩家在不知道自己处于哪个特定决策点的情况下选择行动,因为他们无法观察到先前信息集中采取的行动。
为了模拟IIEFG,引入了其他概念,例如信念和策略的概念。信念是在信息不完全的情况下,玩家对游戏可能状态的主观概率分布。策略定义了玩家的决策规则,根据玩家的信念,指定在每个决策点或信息集采取的行动。解决IIEFG涉及博弈论和决策论的概念,如扩展形式的合理化和子博弈完美均衡。可拓形式合理化通过排除与参与人信念不一致的策略来细化可能的策略集。子博弈完美均衡将纳什均衡的概念扩展到序列博弈,确保参与者的策略不仅在每个决策点上是最优的,而且在每个可能的子博弈(子树)中也是最优的。
**纳什均衡(Nash equilibrium,NE)**非合作博弈均衡
是博弈论中的一个概念,它代表了一种稳定的状态或结果,在这种状态下,没有一个参与者有动机单方面偏离他们所选择的策略。换句话说,这是一个解决方案的概念,它描述了一组策略,每个参与者一个,其中没有参与者可以通过改变自己的策略来提高他们的收益,假设所有其他参与者的策略保持不变。形式上,在有多个参与者的博弈中,纳什均衡是策略的组合,其中每个参与者的策略是对其他参与者选择的策略的最佳反应。在这种情况下,在其他参与人的策略下,没有参与人有任何动机转向不同的策略。博弈论者利用纳什均衡来分析几个决策者的战略互动结果。在战略互动中,每个决策者的结果取决于其他人以及他们自己的决定。
纳什均衡可以存在于同时移动博弈(标准形式博弈)和顺序移动博弈(扩展形式博弈)中。在同时移动游戏中,玩家同时选择他们的策略,而在顺序移动游戏中,玩家顺序选择他们的策略,考虑到前一个玩家的行动。在一个博弈中可以有多个纳什均衡,它们可能会导致不同的结果,给参与者带来不同的收益。一个博弈也可能没有纳什均衡,在这种情况下,结果被认为是不稳定的或处于冲突状态。纳什均衡提供了一个基本概念,用于分析策略互动和预测游戏中可能的结果,玩家根据自己的利益做出决定。
反事实后悔最小化(CFR)
算法是博弈论和人工智能领域中一个广泛应用的算法,用于寻找不完全信息博弈中的近似纳什均衡。它在解决大型游戏时特别有效,例如扑克或其他复杂的战略互动。CFR背后的关键思想是通过后悔最小化来迭代改进策略。Regret是一个衡量一个玩家在观察游戏结果后 会有多喜欢 不同的行动的指标。该算法保留了游戏中每个决策点的后悔值,表示所获得的回报与通过选择不同行动所获得的回报之间的预期差异。
在CFR的每次迭代中,算法遍历博弈树,根据使用当前策略进行的博弈的结果更新遗憾值。
然后,后悔值被用来计算平均策略,它代表了在每个决策点选择不同行动的概率。平均策略在多次迭代中得到改进,朝着纳什均衡收敛。CFR中的“反事实”一词指的是考虑反事实场景的想法,在这种场景中,玩家可以在过去选择不同的行动。通过评估基于这些反事实的遗憾,CFR旨在学习策略,最大限度地减少潜在的遗憾,并收敛到纳什均衡。CFR已经成功地解决了像单挑无限制德州扑克这样的游戏,其中游戏涉及不完整的信息和大量可能的策略。它也被应用到其他领域,包括拍卖和资源分配问题中的策略投标。尽管其有效性,CFR是计算密集型的,可能需要大量的计算资源来解决复杂的游戏。
FTRL(Follow-The-Regularized-Leader)算法
是一种流行的在线学习算法,用于机器学习和优化。它对于涉及大规模数据集和高维特征空间的问题特别有效。FTRL用于求解凸优化问题,其目标是找到最小化某个目标函数的最佳参数集。它通常应用于数据顺序到达的场景,并且模型需要增量更新。FTRL背后的关键思想是在一组可能的参数值上保持概率分布。FTRL不是直接更新参数,而是根据观测数据更新分布。该分布通常表示为参数向量的加权平均值,权重由每个参数向量引起的累积损失确定。
FTRL在目标函数中加入了一个正则化项,这有助于防止过拟合,并鼓励学习参数的稀疏性。正则化项有助于控制模型的复杂性,并防止它对数据中的噪声过于敏感。在FTRL的每次迭代期间,算法接收新的数据点并计算每个参数向量所引起的损失。然后,该算法通过基于观察到的损失调整参数向量的权重来更新分布。这个过程允许FTRL自适应地更新模型并从新数据中学习,同时保持探索和利用之间的平衡。FTRL以其效率,可扩展性和处理大规模问题的能力而闻名。该算法在后悔界限方面有理论保证,该界限量化了学习模型和最优模型之间的性能差距。总的来说,FTRL算法为在线学习和凸优化提供了一个有效的框架,允许模型随着新数据的到来而增量更新,同时结合正则化来控制模型的复杂性。
FTRL-ORW(Follow-The-Regularized-Leader with Online Regret Weighting)
是Follow-The-Regularized-Leader(FTRL)算法的扩展,其中包含了在线后悔权重的概念。它是一种用于在线凸优化的学习算法,并在机器学习和数据分析中有应用。FTRL-ORW算法旨在最大限度地减少遗憾,这量化了事后最佳动作序列的性能损失。它通过保持参数向量的加权平均值来实现这一点,类似于FTRL,但权重由每个参数向量引起的累积Regret 决定。在FTRL-ORW中,遗憾加权用于将较高的权重分配给过去表现良好的参数向量,并将较低的权重分配给那些表现不佳的参数向量。这允许算法基于其历史性能自适应地将重要性分配给不同的参数向量。在FTRL-ORW的每次迭代期间,该算法接收新的数据点,并基于当前的加权参数向量集预测动作。然后,它观察每个参数向量产生的损失,并相应地更新权重。更新规则考虑了与每个参数向量相关联的瞬时损失和累积遗憾。在FTRL-ORW中引入在线后悔权重,提供了一种基于不同参数向量的历史性能动态调整其影响的机制。这在数据分布随时间变化或最佳参数向量在不同时间段内变化的情况下特别有用。FTRL-ORW具有适应不断变化的环境、对噪声和离群值的鲁棒性以及处理大规模数据集的能力等优点。总的来说,FTRL-ORW扩展了FTRL算法,将在线Regret 加权,使其能够有效地平衡在线优化问题中的探索和利用,并实现更好的后悔界限。
Deep FTRL-ORW(Deep Follow-The-Regularized-Leader with Online Regret Weighting)
是FTRL-ORW算法的扩展,结合了深度学习和在线凸优化的概念。它专门用于解决深度神经网络的大规模在线学习问题。Deep FTRL-ORW集成了深度神经网络在复杂模式和表示建模方面的强大功能,以及FTRL-ORW在线后悔加权方案的优势。通过结合这两种方法,Deep FTRL-ORW旨在学习高质量的表示,并在在线设置中增量更新模型参数。在Deep FTRL-ORW中,神经网络架构作为参数空间,神经网络的权重基于观察到的损失和在线后悔加权方案进行更新。该算法处理数据点的顺序到达,更新模型参数,并相应地调整后悔权值。Deep FTRL-ORW中的在线后悔权重允许算法为过去表现良好的神经网络权重分配更高的权重,同时为导致更高后悔的权重分配较低的权重。该机制确保算法基于其历史性能和观察到的损失自适应地更新神经网络权重。
深度FTRL-ORW有几个优点。
首先,它利用了深度神经网络的表示学习能力,允许对数据中的复杂关系进行建模。
其次,它结合了在线后悔加权计划,它提供了一种机制,动态调整不同的神经网络权重的影响,根据其历史表现。这种适应性在不断变化或非静态数据环境中特别有用。深度FTRL-ORW在有连续数据流的场景中特别有效,并且模型需要以在线方式更新,同时保留深度学习和基于遗憾的优化的好处。总体而言,Deep FTRL-ORW将深度学习的力量与在线后悔加权方案相结合,以解决大规模在线学习问题。它能够有效地适应不断变化的数据分布,并提供了一个在线设置中有效更新深度神经网络参数的框架。
two-player zero-sum IIEFGs两人零和不完全信息可拓形式博弈(英语:Two-player zero-sum Imperfect Information Extensive-Form Games,简称IIEFG)
是一种特殊类型的博弈模型,它在序列决策框架中捕捉两个博弈者之间的策略交互,其中博弈具有零和性质。
在零和游戏中,一个玩家的总收益正好等于另一个玩家的收益的负数,这意味着一个玩家的任何收益对应于另一个玩家的相等损失。在两人零和IIEFG中,游戏被表示为树状结构,类似于其他扩展形式的游戏。树中的每个节点代表一个参与者的决策点,边代表参与者可以采取的行动。然而,与完美信息博弈不同,一些节点可能是信息集,其中玩家对博弈状态的信息不完整。游戏中的两个玩家有相互冲突的目标,因为一个玩家在效用上的任何收益都会导致另一个玩家的相等和相反的损失。他们在考虑其他参与者的行动和可能的策略的同时,有策略地选择自己的行动,以最大化自己的收益。解决两人零和IIEFG通常涉及寻找均衡解决方案,例如纳什均衡。
纳什均衡是一对策略,每个参与人一个,其中没有一个参与人有动机单方面偏离他们选择的策略,考虑到另一个参与人的策略。各种解决方案的概念和算法可以应用于寻找两个玩家零和IEFG中的均衡,包括极大极小算法,线性规划和反事实遗憾最小化(CFR)。这些技术旨在确定策略,最大化一个玩家的预期收益,同时最小化其他玩家的预期收益。两人零和IIEFG用于建模和分析竞争性互动,如扑克,战略棋盘游戏和谈判,其中两个玩家有相反的利益,并在不完全信息的情况下进行顺序决策过程。
1、介绍
不完全信息可拓形式博弈(英语:Imperfect information extensive-form games,缩写:IIEFG)是一种标准的博弈类型,可以模拟多个代理、不完全信息和随机事件。IIEFG已被广泛用于模拟现实世界的情况,如医疗(Sandholm 2015),安全游戏(Lis`y,Davis和Bowling 2016),网络安全游戏(Chen et al. 2017年),和娱乐游戏(布朗和桑德霍姆2018年,2019年)。对于这些游戏,共同的目标是找到纳什均衡(NE),因为它规定了理性行为的概念,其中没有参与者可以从单方面偏离均衡中获益。
为了在IIEFG中学习NE,最有力的方法之一是反事实遗憾最小化(CFR)(Zinkevich et al. 2007)算法。CFR是Follow-The-Regularized-Leader(FTRL)(Shalev-Shwartz and Singer 2007)算法的特殊情况,其利用FD扩张距离生成函数(FD扩张DGF)(Liu et al. 2022年)。**CFR通过迭代遍历整个博弈 并最小化每个信息集(infoset)上的遗憾来学习NE。**由于大多数现实场景中的大规模状态空间,不可能遍历整个博弈树并使用表格来表示策略。为了回避这个问题,已经提出了CFR的许多神经变体(Brown et al. 2019; Li et al. 2019; Gruslys等人2020; Hennes et al. 2020; Steinberger,Lerer和Brown 2020; Fu等人,2021; McAleer等人2022年)。在每一次,他们估计反事实的遗憾,并使用估计的遗憾更新策略。然后,他们通过神经网络近似新策略。然而,每个近似都会引起近似误差。由于迭代t时的反事实遗憾是用代理人先前的近似策略估计的,因此这些误差会累积。由于这种累积的近似误差,这些方法具有较差的性能。反事实遗憾与FD扩张的DGF有关。不幸的是,FD扩张DGF在迭代t是依赖于代理的过去的策略,这是为什么CFR的神经变体遭受这样的累积近似误差的根本原因。
为了解决累积的近似误差,我们建议将神经网络与FTRL相结合,其DGF在迭代t时独立于代理的先前策略。
- 为了实现这一目标,我们提供了我们的第一个关键贡献一种新的DGF称为对手相关的扩张DGF(ORD-DGF),这与代理的过去策略无关。更重要的是,策略的ORD-DGF值可以通过从博弈中采样的轨迹来估计。它允许FTRL-ORW算法通过采样轨迹更新其策略。这个属性使FTRL-ORW适合于解决大规模的博弈,因为在这样的游戏中,为每个信息集采样多个动作太昂贵了。然而,如果我们仅在迭代t处获得这样的采样轨迹,则仍然不清楚如何计算FTRL-ORW的下一迭代策略。
- 为了解决这个问题并将FTRL-ORW扩展到大规模博弈,我们做出了第二个关键贡献-Deep FTRL-ORW算法。Deep FTRL-ORW采用无模型最大熵深度强化学习(MEDRL)算法(Haarnoja et al. 2018)https://github.com/haarnoja/sacFTRL-ORW的下一次迭代策略。深度FTRL-ORW是一种无模型方法,它从采样轨迹中学习。
- 第三,我们证明了FTRL-ORW和Deep FTRL-ORW在完美召回率的two-player zero-sum IIEFGs中分别收敛到
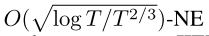 和
和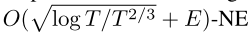 ,其中T是迭代次数,E是MEDRL的解误差界。**请注意,迭代t时的解误差仅对NE的收敛性能产生一次性影响,不会影响后续更新。**相反,迭代t时CFR神经变体的近似误差影响所有后续更新。换句话说,它会多次影响收敛性能。
,其中T是迭代次数,E是MEDRL的解误差界。**请注意,迭代t时的解误差仅对NE的收敛性能产生一次性影响,不会影响后续更新。**相反,迭代t时CFR神经变体的近似误差影响所有后续更新。换句话说,它会多次影响收敛性能。 - 最后,在三个标准的IIEFG基准测试,即,Kuhn Poker、Leduc Poker和Goofspiel证明,与CFR相比,FTRL-ORW实现了有竞争力的性能,**与其他无模型神经方法和OS-MCCFR相比,Deep FTRL-ORW具有最低的可利用性(Lanctot et al. 2009年)。**在大型游戏的实验中,例如phantom tic tac toe和dark hex,Deep FTRL-ORW比现有的无模型神经方法具有更高的实用性。
2、相关工作
在本文中,我们专注于学习NE在 two-player zero- sum IIEFGs与完美召回率。已经提出了许多方法来学习近似NE在这样的游戏。这些方法通常需要遍历整个博弈树。然而,由于在大多数真实世界场景中的大尺寸,不可能遍历整个游戏。因此,已经提出了许多随机方法,这些方法在每个信息集上采样动作以减少计算开销。
种群学习方法这些方法是策略空间响应神谕(PSRO)的变体(Lanctot et al. 2017年)。它们存储过去的策略和它们上的元分布,通过计算对过去策略的混合的最佳响应来增量地将新策略添加到策略集。神经虚构自我游戏(NFSP)(Heinrich and银2016)可以被视为PSRO的一个特例,其中元分布是均匀分布。这些方法可以扩展到大规模的游戏,因为它们只需要模拟的政策和汇总数据(Vinyals等人。2019年)。然而,它们的收敛速度通常与游戏策略空间的大小有关。因此,他们可能有一个大的分支因素和长的视野,因为这样的游戏的策略空间太大的IIEFG的表现不佳。
表列遗憾最小化方法这些方法(Lanctot等人2009年;法里纳、克罗尔和桑德霍尔姆2020;法里纳、施莫克和桑德霍尔姆2021;法里纳和桑德霍尔姆2021;科祖诺等人。2021年;Bai等人。2022)估计当前损耗梯度,并将估计的损耗梯度馈送到全反馈遗憾最小器,例如CFR(Zinkevich等人。2007)和OMD(Duchi、Hazan和Singer 2011)。这些方法收敛到概率为1−p(p∈(0,1))的O(根号下1/T)-NE,其中T为迭代次数。然而,它们是表格方法,昂贵的内存开销限制了它们在大型游戏中的应用。
CFR的神经变体这些方法也是遗憾最小化的方法。尽管表格后悔最小化方法减少了计算开销,但它们仍然存在较大的内存开销。因此,已经提出了许多CFR的神经变体。他们通过神经网络近似CFR的行为,以适应大规模游戏(Brown等人。2019年;Li等人。2019;Steinberger 2019;Gruslys等人。2020年;Hennes等人。2020;Fu等人。2021年;McAleer等人。2022年)。在每次迭代中,这些方法估计反事实遗憾,并使用估计的反事实遗憾来更新策略。然后,他们通过神经网络逼近新策略。然而,这种逼近在每次迭代时都会产生逼近误差。此外,他们根据先前的近似策略估计迭代t处的反事实遗憾,这累积了这些错误。为了解决这一累积误差,我们提出了一种新的表格遗憾最小化方法,并用神经网络逼近其行为。
3、预备工作
在本节中,我们将介绍必要的术语。
首先,我们介绍了一些关于可拓形式博弈的概念。
然后,我们说明了学习纳什均衡(NE)通过后悔最小化方法的过程。
3.1 可拓形式博弈
不完全信息可拓形式博弈(英语:Imperfect Information Extensive Form Games,缩写:IIEFG)是一种涉及多个智能体的顺序交互模型,由一棵以根节点r为根的树表示。树中的每个节点h属于集合{0,1,c}中的一个参与者,其中0是最小参与者,1是最大参与者,c是机会参与者。我们用Hi来表示属于参与人 i 的节点集合。符号A(h)表示在节点h处可用的动作。每个节点 z 使得A(z)= 空集,称为叶节点,代表博弈的终端状态。叶节点的集合由 Z 表示。对于每个叶节点z,有一对(v0(z),v1(z))∈ R2,分别表示最小参与人(参与人0)和最大参与人(参与人1)的收益。在我们的设置中,对于所有z ∈ Z,v0(z)= −v1(z)。为了表示私人信息,每个参与者 i 的节点被划分为一个集合Ii,称为信息集(infosets)。完美召回率意味着没有玩家会忘记任何已经透露的信息。
**行为策略 ** 参与人 i 的行为策略σi在每个信息集上定义。对于任何信息集I ∈ Ii,动作a ∈ A(I)的概率记为σi(I,a)。参与人 i 以外的策略记为σ−i。如果每个参与者都按照σ进行博弈 并到达信息集 I,则到达概率用πσ(I)表示。i 对这个概率的贡献是πσ i(I)和πσ −i(I),对于其他的 i 。我们使用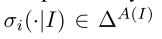 表示在信息集I上的动作的概率分布,其中∆A(I)是n维单形(n = A(I)− 1)。
表示在信息集I上的动作的概率分布,其中∆A(I)是n维单形(n = A(I)− 1)。
序列形式策略一个序列是一个信息集动作对(I,a),其中 I 是一个信息集,a是属于A(I)的动作。每个序列标识从根节点到信息集 I 的路径,并选择动作a。参与人 i 的序列集记为Σi.。从r到I 的路径上遇到的最后一个序列记为ρI。参与人i 的序列形式策略是一个非负向量x在序列集Σi上的索引。对于每个序列q =(I,a)∈ n i,如果她遵循策略下,则xq是参与人i 在遵循策略 x 的情况下到达序列 q的概率。在本文中,我们将序列形式的策略空间表述为树丛(Hoda et al. 2010)。令X和Y表示最小参与者和最大参与者的序列形式策略集。它们是欧氏空间Ex,Ey中的非空凸紧集。我们使用xI表示给定策略x对应于属于信息集I的序列的切片。已经证明,在具有完美召回率的IIEFGs中,行为策略与序列形式策略是实现等价的(Von Stengel 1996)。更多细节见附录。
我们在不同的情况下使用不同的策略表示,因为这两种表示有其优点和局限性。为了方便起见,我们在附录中提供了两种策略表示之间的符号转换表。
3.2 后悔最小化方法
Regret这个概念来自在线凸优化框架(Zinkevich 2003),其中决策者从凸紧集U ∈ Rd中选择一个点ut,并在每次迭代 t 时面临损失梯度ℓt ∈ Rd。这个regret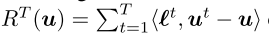 表示序列输出u1,· · ·,uT的累积损失梯度与固定点 u 的损失梯度间的差。
表示序列输出u1,· · ·,uT的累积损失梯度与固定点 u 的损失梯度间的差。
在具有完美召回率的two-player zero-sum IIEFGs(双人零和博弈)中,纳什均衡(NE)可以用公式表示为双线性鞍点问题(BSPP)的解决方案(也称为序列形式表示):
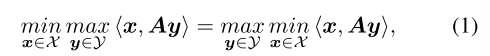
其中x和y分别是最小参与人 和 最大参与人 的 序列形式策略,A是收益矩阵。用鞍点间隙来 量化解[x; y] ∈ X × Y的精度
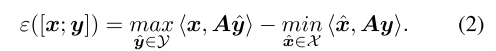
**Learning NE via Regret Minimization通过后悔最小化学习纳什均衡 **
为了学习NE,我们希望找到一个鞍点间隙收敛到0的一对[x; y]。Regret 最小化方法可以用来实现这一目标。
- 第一步是为策略集 X 和 Y 实例化两个Regret 最小化器R0和R1。
- 然后,在每次迭代 t,Regret 最小化器R0和R1面对损失梯度
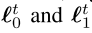 ,并输出策略 xt+1和yt+1。
,并输出策略 xt+1和yt+1。 - 然后,它们用于在下一次迭代t + 1产生损失梯度
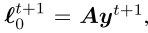 和
和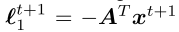 。令x和y的均值表示 R0和R1输出的 平均策略。一个经典定理表示如下,
。令x和y的均值表示 R0和R1输出的 平均策略。一个经典定理表示如下,
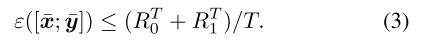
双线性鞍点问题(BSPP)
是在凸优化和博弈论研究中出现的一个数学优化问题。它涉及到在凸集上寻找双线性目标函数的鞍点。
形式上,BSPP可以定义如下:
最小化:f(x,y)
服从:x ∈ X,y ∈ Y其中f(x,y)是双线性目标函数,X和Y是分别表示变量x和y的可行区域的凸集。
目标函数f(x,y)是双线性的,因为它对变量x和y都是线性的。它可以写为f(x,y)= x^T A y,其中A是适当维数的矩阵。
BSPP的鞍点是满足以下条件的一对值(x*,y*):
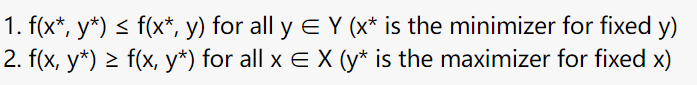
换句话说,鞍点是同时 最小化关于x的目标函数和 最大化关于y的目标函数 的解。
由于目标函数的双线性和凸集的存在,找到BSPP的鞍点可能具有挑战性。各种优化算法和技术,如鞍点法,可以用来解决BSPP有效。
它出现在诸如两人零和博弈、投资组合优化和二次规划等问题中。
The saddle-point gap
指的是两人零和博弈中上界和下界的值之差。在博弈论中,两个玩家的零和游戏是一个游戏,其中一个玩家的收益与另一个玩家的损失完全平衡,导致零和结果。saddle-point gap的概念在确定此类博弈的最优策略和最优值时出现。
上界表示一个参与者通过选择最优策略来对抗另一个参与者选择的任何策略所能达到的最大值。
下限表示对手玩家可以确保对抗第一个玩家选择的任何策略的最小值。
鞍点间隙是这两个界限之间的差。
从数学上讲,如果V是博弈的值,V_upper是上界,V_lower是下界,那么鞍点差距可以表示为:鞍点间隙= V_upper - V_lower。
在理想情况下,当上下界重合时,鞍点差距为零,表明博弈有一个鞍点,这对双方来说都是最优策略。然而,在实践中,确定博弈的最优策略和值可能具有挑战性,并且鞍点差距可能不是零。鞍点差距提供了对游戏竞争力的见解。差距越小,表明参与者的最优策略越接近,使其成为更具竞争性的游戏。相反,差距越大,表明最优策略之间的差距越大,这使得一个参与者更容易获得优势。了解鞍点缺口有助于分析两人零和博弈中的战略互动和决策。它提供了一个衡量参与者可能获得的潜在收益或损失的标准,并可能影响他们的战略选择和考虑。
在数学中,凸集是向量空间或仿射空间的一个子集,它包含连接任何两个点的所有线段。
更正式地说,一个集合S被称为凸的,如果对于S中的任意两个点x和y,连接x和y的线段,记为[x,y],完全包含在S内。
在数学上,这可以表示为:对于S中的所有x,y和[0,1]中的所有t,点tx +(1 - t)y也在S中。简单地说,一个集合是凸的,如果它是“向外弯曲的”,并且不包含任何凹痕或“凹痕”。“任何连接集合中两点的直线段都应该完全位于集合内。
凸集的例子包括:
1.真实的数线上的闭区间[a,B]。
2.n维空间中的封闭半空间,由a1 x1 + a2 x2 +.形式的不等式定义。+ anxn ≤ B,其中a1,a2,…,an是常数,x1,x2,…,xn是变量。3.平面上的凸多边形。
4.整个向量空间或仿射空间本身。
凸集有几个重要的性质,例如:
1.任何凸集的交也是凸的。
2.一组点的凸船体是包含所有这些点的最小凸集。
3.凸集可以用凸组合来表征,凸组合是集合内点的加权平均。凸集在凸优化中起着重要的作用,其目标是最小化凸集上的凸函数。凸集的性质使其适合于有效的优化算法,为研究优化问题提供了坚实的基础。
4、FTRL-ORW
在本节中,我们首先描述FTRL。
其次,我们说明了为什么CFR的神经变体遭受累积近似误差。然后,为了解决这种累积误差,我们提出了一种新的DGF称为Opponent Related Dilated Distance Generating Function(对手相关的扩张距离生成函数)(ORD-DGF)。ORD-DGF与智能体先前的策略无关。此外,可以从采样的轨迹估计ORD-DGF。它允许FTRL-ORW算法从采样轨迹更新其策略,这使得FTRL-ORW能够扩展到大规模的IIEFG。
最后证明了FTRL-ORW算法的收敛性。
4.1 Follow-The-Regularized-Leader跟随规则化领导者(FTRL)
Follow-The-Regularized-Leader(FTRL)是最重要的regret最小化方法之一。假设我们是最小参与者,在每次迭代 t ,FTRL最小化具有正则化项(也称为镜像映射算子)的累积损失梯度之和。
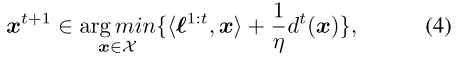
其中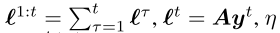 是步长参数,并且dt(x)是距离生成函数(DGF),是1-强凸的。序列形式策略多胞形上的一个特定范数。在本文中,我们考虑了一种特殊类型的DGF,它在求解IIEFG时证明了SOTA结果:扩张的DGF(the dilated DGFs Hoda et al. 2010; Kroer et al. 2015,2020; Farina,Kroer,and Sandholm 2019,2021; Liu et al. 2022)。通过对每个信息集的合适的局部DGF求和来构造扩张的DGF,其中每个局部DGF由导致信息集的父变量扩张:
是步长参数,并且dt(x)是距离生成函数(DGF),是1-强凸的。序列形式策略多胞形上的一个特定范数。在本文中,我们考虑了一种特殊类型的DGF,它在求解IIEFG时证明了SOTA结果:扩张的DGF(the dilated DGFs Hoda et al. 2010; Kroer et al. 2015,2020; Farina,Kroer,and Sandholm 2019,2021; Liu et al. 2022)。通过对每个信息集的合适的局部DGF求和来构造扩张的DGF,其中每个局部DGF由导致信息集的父变量扩张:
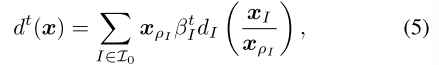
其中dI(x)是信息集 I 处的局部DGF,βt I是迭代t处局部DGF dI(x)上的权重。由序列型策略的定义,我们得到xI / xρI ∈ λ A(I)。为方便起见,xI / xρI在下文中用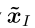 表示。此外,我们有
表示。此外,我们有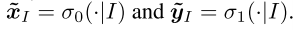
4.2 为什么CFR的神经变体会受到累积近似误差的影响
在这一小节中,我们将说明为什么CFR的神经变体会受到累积近似误差的影响。我们首先描述反事实遗憾最小化(CFR)。CFR是FTR的一种特殊情况,其使用FD扩张的DGF(Liu等人,2022)。形式上,假设我们是最小参与者,FD扩张的DGF将权重βt I设置为
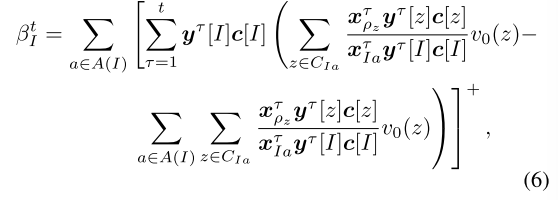
其中yτ[I](yτ[z])是最大(max)玩家在遵循策略yτ 的情况下,到达信息集I(叶节点z)的概率,c[I](c[z])是机会(chance)玩家到达信息集 I(叶节点z)的机会概率,[x]+ = max(x,0),CIa是玩家在信息集 I 选择行动 a 时可能遇到的叶节点集合。
在每次迭代t,为了选择下一次迭代策略,CFR通过智能体的过去策略 x1,…,xt 计算每个信息集 I 处的局部DGF权重 βt I。CFR的神经变体通过神经网络近似这些策略,这会引起近似误差。这些近似误差累积,因为权重βt I是通过过去的近似策略估计的,并且估计的权重用于更新智能体的策略。
4.3 Opponent Related Dilated DGF(对手相关DGF扩张)
为了解决累积的近似误差,我们提出了一个扩张的DGF称为对手相关扩张DGF(ORD-DGF),这是独立的智能体的过去的策略xt,· · ·,xt。此外,策略 x 的ORD-DGF d(x)的值可以从采样轨迹估计。The mirror-mapping operator(镜像映射算子)是一个单智能体优化问题。由于第一项累积损失梯度和第二项镜像映射算子的DGF值可以从采样轨迹中估计,因此这种单智能体优化问题也可以从采样轨迹中解决。它适合于解决大型游戏,因为在这样的游戏中,为每个信息集采样多个动作太昂贵了。
在本小节中,我们首先描述了ORD-DGF,然后说明为什么给定策略的ORD-DGF的值可以从采样轨迹估计,而其他现有的DGF(除了FD扩张的DGF)不能。假设我们是最小参与者,迭代t处的ORD-DGF被定义为:
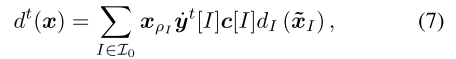
和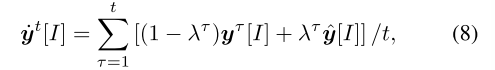
其中λτ是迭代t时的突变权重,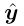 是固定策略,yt[I](y[I])是最大参与者在遵循策略yt(y)的情况下到达信息集I的概率。注意,c[I]是 已知的 并且是 时不变 的。对于最小参与者,等式7中的概念yt [I]和Io分别用xt [I]和I1 代替。在本文中,我们将dI设置为负熵DGF d(u)=
是固定策略,yt[I](y[I])是最大参与者在遵循策略yt(y)的情况下到达信息集I的概率。注意,c[I]是 已知的 并且是 时不变 的。对于最小参与者,等式7中的概念yt [I]和Io分别用xt [I]和I1 代替。在本文中,我们将dI设置为负熵DGF d(u)= 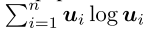 ,因为与其他常用的局部DGF相比,它为FTRL-ORW提供了更好的收敛性,其中n是向量u的维数。从行为策略与序列形式策略的实现等价性出发,我们有
,因为与其他常用的局部DGF相比,它为FTRL-ORW提供了更好的收敛性,其中n是向量u的维数。从行为策略与序列形式策略的实现等价性出发,我们有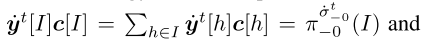
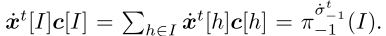
由于ORD-DGF只与观测到的对手策略相关,因此它不会受到累积逼近误差的影响。
现在,我们说明了为什么一个策略的ord-dGF的值可以从采样轨迹估计,而其他现有的DGFs不能。假设我们遵循策略x,对手遵循策略yt,我们从博弈中抽取N个轨迹。对于ORD-DGF,我们有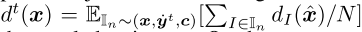
其中In是第n个采样轨迹。相反,如果我们使用除了FD扩张DGF之外的任何其他现有DGF,我们有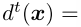
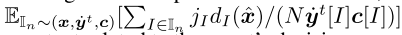
其中,jI是与智能体的决策空间相关的常数。如果不遍历整个博弈树 或 不使用昂贵的领域知识,我们就无法获得yt [I]c[I]的值。
将ORD-DGF代入等式(4)中,在此基础上,我们用ORD-DGF算法(FTRL-ORW)得到了FTRL。假设我们是最小参与者,在每次迭代 t ,FTRL-ORW根据公式9 选择下一个迭代策略xt+1:
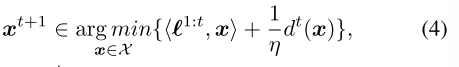
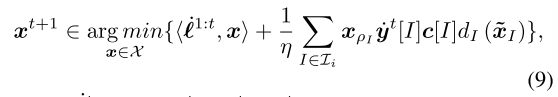
其中,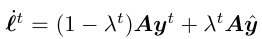
由于ORD-DGF是用观察到的对手的平均策略构建的。在一个有着最后回归率的两人零和博弈IIEFG中,如果每个参与者都运行FTRL-ORW T迭代,那么他们的平均策略收敛到一个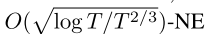 。证据在附录中。
。证据在附录中。
命题1根据Hoda et al.(2010)的分析,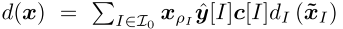 是Υ-strongly convex强凸。因此,
是Υ-strongly convex强凸。因此,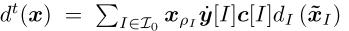
是λt Y强凸的。设λt = t的负三分之一次方,B为正常数,使得对每个信息集 I,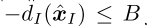 ,C为任意信息集中包含的最大节点数。如果每个参与人都运行FTRL-ORWT迭代(T ≥ 3),则平均策略[x均值;y均值]的鞍点间隙由下式限定:
,C为任意信息集中包含的最大节点数。如果每个参与人都运行FTRL-ORWT迭代(T ≥ 3),则平均策略[x均值;y均值]的鞍点间隙由下式限定:
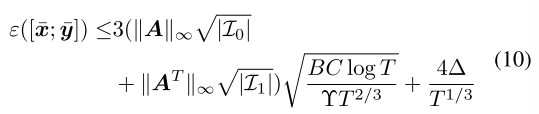
5、Deep FTRL-ORW
FTRL-ORW的镜像映射算子(等式(9))是一个单智能体优化问题,可以从采样轨迹解决。在本节中,我们描述了Deep FTRL-ORW,它采用了无策略模型的最大熵深度强化学习(MEDRL)算法来解决仅显示采样轨迹时的优化问题。
我们首先解释使用MEDRL计算等式9 的原因。
然后,我们介绍了Deep FTRL-ORW的整体架构,其伪代码在算法1中给出。
最后,我们给出了深度FTRL-ORW的收敛性分析。

5.1 通过 最大熵深度强化学习 计算方程(9)
最大熵深度强化学习(MEDRL)
是一种结合最大熵强化学习和深度神经网络原理的方法。它旨在解决强化学习问题,其中代理需要学习最大化预期回报和策略熵的策略。在传统的强化学习中,目标是找到最大化预期累积奖励的最优策略。然而,在许多现实世界的场景中,探索不同的动作集并在其行为中表现出一定程度的随机性对智能体是有益的。这种随机性可以帮助代理发现新的策略,避免陷入次优解决方案。MEDRL将最大熵的概念纳入强化学习框架,以明确鼓励探索和随机行为。最大熵原理指出,当面对不确定性时,代理人应该选择具有最大熵的行动(即,最大的随机性),同时仍然最大化预期回报。
在MEDRL中使用深度神经网络来近似策略函数。神经网络将环境的状态作为输入,并输出动作的概率分布。通过使用深度神经网络参数化策略,MEDRL可以处理高维状态空间并学习复杂的表示。MEDRL的训练涉及优化政策参数,同时最大化预期收益和政策的熵。这通常使用基于梯度的优化算法来完成,例如随机梯度下降(SGD)或类似策略梯度方法的变体。在学习过程中包含最大熵允许MEDRL探索更广泛的行动和政策,从而更好地探索并可能找到更优的解决方案。它通过促进代理人行为的随机性,。通过结合最大熵原理并利用深度神经网络的代表性,MEDRL为复杂强化学习问题中的学习策略提供了一个灵活有效的框架。
假设我们是参与人i,参与人1 − i 遵循策略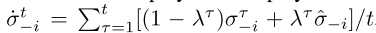 ,其中σt −i是参与人1 − i 的策略,
,其中σt −i是参与人1 − i 的策略,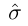 是固定策略。
是固定策略。
**计算等式(9)在迭代t中,找到单智能体优化问题的最优解:**智能体 i 在信息集Il上选择一个动作al,然后转移到信息集Il+1或叶节点z,并分别获得奖励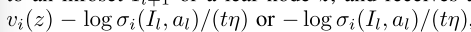 。
。
如果智能体转换到一个新的信息集,它将继续选择一个动作,否则终止。此单智能体优化问题的最优解定义为
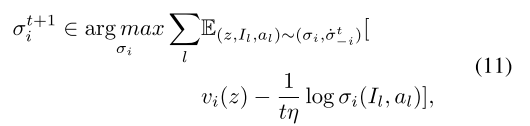
**这样的单智能体优化问题是Partially Observable Markov Decision Process部分可观测马尔可夫决策过程(POMDP)。**解决POMDPs最流行的方法是深度强化学习(DRL)算法。由于这种单智能体优化问题中的奖励与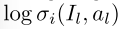 项相关,因此我们采用最大熵深度强化学习(MEDRL)算法来解决此优化问题。MEDRL算法的目标是学习一个策略σi,使一般熵奖励的期望和最大化:
项相关,因此我们采用最大熵深度强化学习(MEDRL)算法来解决此优化问题。MEDRL算法的目标是学习一个策略σi,使一般熵奖励的期望和最大化:
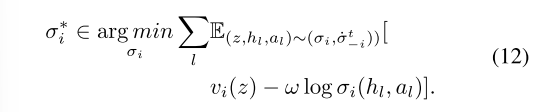
其中h l是encountered node遇到节点。显然,在完全信息可拓形式博弈(PIEFG)中,如果我们设置ω = 1 / tη,方程(12)的最优解 等于等式(11)的最优解。换句话说,FTRL-ORW的镜像映射算子的解等于PIEFG中的MEDRL算法的解。事实上,已经证明MEDRL在PIEFG中收敛(Geist,Scherrer和Pietquin 2019)。虽然我们认为IIEFG,而不是PIEFG,我们直接利用MEDRL算法计算方程(11)。
为了计算FTRL-ORW(等式(9))的镜像映射算子的最优解使用MEDRL,每个深度FTRL-ORW智能体使用两个神经网络,一个soft Q-function Qθ(I,a)和一个当前的MEDRL策略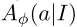 。这些网络I的参数分别为θ和
。这些网络I的参数分别为θ和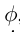 。此外,每个代理使用重放 缓冲区MRL来记忆其博弈转换的过程。在训练中,每个智能体交替使用随机梯度下降优化两个网络。准确地说,Qθ(I,a)被训练成最小化软Bellman残差
。此外,每个代理使用重放 缓冲区MRL来记忆其博弈转换的过程。在训练中,每个智能体交替使用随机梯度下降优化两个网络。准确地说,Qθ(I,a)被训练成最小化软Bellman残差
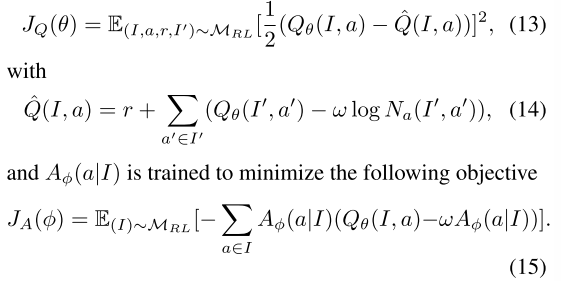
为了降低样本的复杂性,我们希望所有玩家在相互对抗的同时学习。在这种情况下,所有智能体都遵循其平均策略。然而,智能体仍然需要对额外的轨迹进行采样,以跟踪当前的MEDRL策略,用于训练平均策略网络。
为了解决这个问题,Deep FTRL-ORW采用预期动态(Shamma和Arslan 2005)来采样其当前的MEDRL策略,并同时跟踪对手行为的变化。准确地说,在每次迭代t,每个智能体 i 都遵循混合策略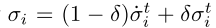 ,而不是策略σti,其中δ ∈ [0,1]是预期参数,σt i是当前MEDRL策略。如果我们使用预期动力学,请注意,只有非策略MEDRL算法是可行的,因为智能体根据混合策略对轨迹进行采样
,而不是策略σti,其中δ ∈ [0,1]是预期参数,σt i是当前MEDRL策略。如果我们使用预期动力学,请注意,只有非策略MEDRL算法是可行的,因为智能体根据混合策略对轨迹进行采样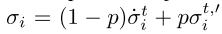 ,而不是当前策略
,而不是当前策略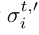 对轨迹进行采样。
对轨迹进行采样。
5.2 Deep FTRL-ORW概述
在Deep FTRL-ORW中,玩家由一个单独的Deep FTRL-ORW智能体控制。所有Deep FTRL-ORW智能体都从彼此的同步游戏中学习。**每个Deep FTRL-ORW智能体在两个不同的重放缓冲区MRL和MSL中记忆其游戏转换的经验及其当前的MEDRL策略。**每个Deep FTRL-ORW智能体有三个网络,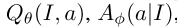 和平均策略
和平均策略 。这些网络的参数是
。这些网络的参数是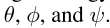 前两个网络 和 重放缓冲器MRL 用于MEDRL算法训练 以 计算 等式(9)。网络表示评估期间的平均策略。它通过优化MSL中存储的数据的交叉熵损失来 定期训练 近似平均策略
前两个网络 和 重放缓冲器MRL 用于MEDRL算法训练 以 计算 等式(9)。网络表示评估期间的平均策略。它通过优化MSL中存储的数据的交叉熵损失来 定期训练 近似平均策略
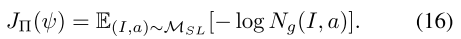
为了避免从有限存储器采样引起的窗口伪影(windowing artifacts),MSL使用储层采样。
如上所述,在每次迭代 t,每个Deep FTRlORW智能体 i 遵循混合策略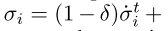 δσt i。无论使用什么策略,智能体都将转换元组(Il,al,rl+1,Il+1)存储在MRL中。只有当智能体根据MEDRL策略选择动作时,她才在MSL中存储转换元组(Il,al)。请注意,在训练期间,平均策略
δσt i。无论使用什么策略,智能体都将转换元组(Il,al,rl+1,Il+1)存储在MRL中。只有当智能体根据MEDRL策略选择动作时,她才在MSL中存储转换元组(Il,al)。请注意,在训练期间,平均策略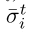 是通过从存储的过去策略中均匀采样策略来实现的,以解决由近似平均策略引起的近似误差。在评估期间,平均策略由神经网络神经网络
是通过从存储的过去策略中均匀采样策略来实现的,以解决由近似平均策略引起的近似误差。在评估期间,平均策略由神经网络神经网络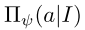 减少评价费用。
减少评价费用。
5.3 深度FTRL-ORW的收敛性
在每次迭代t,MEDRL计算等式(9)并分别输出最小参与者和最大参与者的策略xt和yt。我们假设等式(9)对于最小参与者和最大参与者的最优解,分别是xt,∗ 和 yt,∗。然后xt 和 xt,∗之间的距离,表示为ϵt0。类似地,yt 和 yt,∗之间的距离表示为ϵt 1。MEDRL的解的精度可以通过每次迭代t时的ϵt 0和ϵt 1的大小来衡量。命题2指出,深度FTRL-ORW的收敛界与两项正相关:
(i)FTRL-ORW的收敛速度(等式(17)中的第一项)
(ii)MEDRL的解决方案的准确性(方程(17)的第二项)。
命题2在一个具有完美回归率的两人零和IIEFG中,假设每个参与者都运行Deep FTRL-ORW。令T表示深度FTRL-ORW迭代的次数,[xt; yt]是最大熵深度强化学习在迭代 t 处输出的策略简档,[xt,∗; yt,∗]是等式9的解。(9)在迭代t,[xt; yt]-[xt,∗; yt,∗] = [ϵt0; ϵt1],E是正常数,使得||ϵti||l ≤ E,其中i ∈ 0,1且所有t ∈ [T]。经过T次迭代(T ≥ 3)后,鞍点间隙的界为:
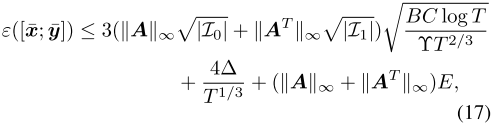
其中,**B,C,Υ 在命题1中定义,**x均值,y均值分别是最小参与人和最大参与人的平均策略。
6、实验
在本节中,我们通过大量的实验来评估Deep FTRLORW的性能。FTRL-ORW的实验结果见附录。
在本节中,我们首先在三个标准IIEFG基准上证明了深度FTRL-ORW近似NE的经验收敛,即,Kuhn Poker、Leduc Poker和Goofspiel(5),其中Goofspiel(5)表示卡片的数量为5。在这种情况下,可利用性被用作测量到NE的差距的性能度量。它是鞍点间隙的一半。
然后,我们进行了实验在大型游戏phantom tic tac toe and dark hex上。由于这些游戏的规模很大,我们通过与随机智能体进行比赛来比较性能。所有测试游戏均由OpenSpiel提供(Lanctot et al. 2019)。所有测试的神经网络算法在实验中具有相似的网络结构,在隐藏层中有128个神经元。所有实验都在一台配备四个20核3.10GHz CPU、394 GB内存和两个RTX3060 GPU的计算机上运行。我们的代码可以在https://github.com/menglinjian/Deep-FTRL-ORW上找到。
向均衡收敛
Configurations在本小节中,我们研究了三个标准IIEFG基准上的深度FTRL-ORW到NE的经验收敛,即,Kuhn Poker,Leduc Poker和Goofspiel(5)。我们将Deep FTRL-ORW与其他无模型方法进行了比较,如NFSP,QPG/ RPG(Srinivasan et al. 2018),OS-Deep CFR和OS-MCCFR(Lanctot et al. 2009)。OS-Deep CFR是Deep CFR的一种特殊情况(Brown等人,2019),其使用结果采样。实际上,OSDeep CFR是OS-MCCFR的表格版本。**OpenSpiel提供了NFSP和两种PG算法的实现。**在Kuhn Poker和Leduc Poker中,NFSP的超参数是根据OpenSpiel的建议调整的,而两种PG算法的超参数是由Farina和Sandholm(2021)提供的。在Goofspiel(5)中,测试神经网络算法的超参数是从Leduc Poker中使用的超参数进行微调的。超参数见附录。OS-MCCFR的勘探项为0. 1,由Farina和Sandholm(2021)提供。
Results我们用不同的随机种子运行每个算法四次。结果如图1所示。Deep FTRL-ORW在所有测试游戏中提供了最低的可利用性。两种PG算法表现出较差的性能,这与Farina和Sandholm(2021)的结果一致。我们猜测这是因为它们对超参数太敏感了。与NFSP相比,Deep FTRL-ORW通常需要大约40-50%的剧集才能在所有测试游戏中达到与NFSP相似的结果。与理论一致的是,Deep FTRL-ORW的理论收敛性远远优于NFSP。与OSMCCFR相比,Deep FTRL-ORW的初始性能较差,最终可利用性较低。我们的直觉是,由重要性抽样引起的高估计方差最终导致了较差的性能。OS-Deep CFR显示出比OS-MCCFR差得多的性能,这可能是由累积的近似误差引起的。
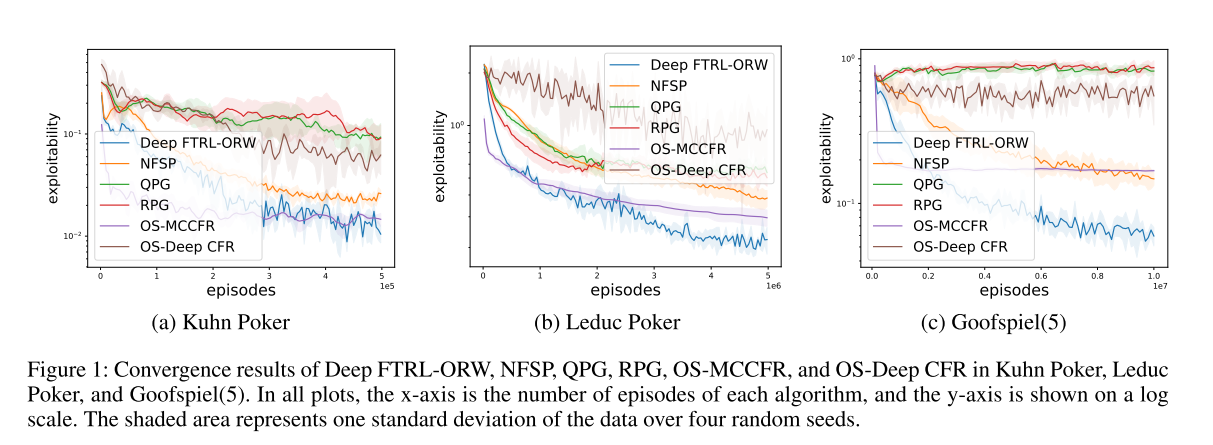
图1:Kuhn Poker、Leduc Poker和Goofspiel中Deep FTRL-ORW、NFSP、QPG、RPG、OS-MCCFR和OS-Deep CFR的收敛结果(5)。在所有图中,x轴是每个算法的迭代次数,y轴以对数标度显示。阴影区域表示四个随机种子上的数据的一个标准差。
对随机代理的性能表现
在本小节中,我们展示了Deep FTRLORW在大型游戏中的性能,例如Phantom Tic Tac Toe(Phantom TTT)和Dark Hex。这些博弈是在正方形棋盘上进行的完全信息博弈的不完全信息版本。由于这些游戏的规模很大,无法获得可利用性。
因此,我们通过与随机智能体进行比赛来比较性能。我们运行1000次以获得平均奖励作为度量。在我们的实验中,我们将Phantom TTT的板尺寸设置为3 × 3,并将dark hex的板尺寸设置为4 × 4(暗十六进制(4))和5 × 5(暗十六进制(5))。我们只比较了Deep FTRL-ORW和NFSP,因为OS-MCCFR由于游戏尺寸大而无法扩展到这些游戏,而OS-Deep CFR/QPG/RPG即使在小游戏中也表现不佳。每个算法的超参数在所有测试的游戏中都是不变的。我们用不同的随机种子运行每个算法四次。结果如图2所示。在所有测试的游戏中,我们看到我们的方法具有最好的性能。此外,深FTRL-ORW的回报曲线总是高于NFSP。
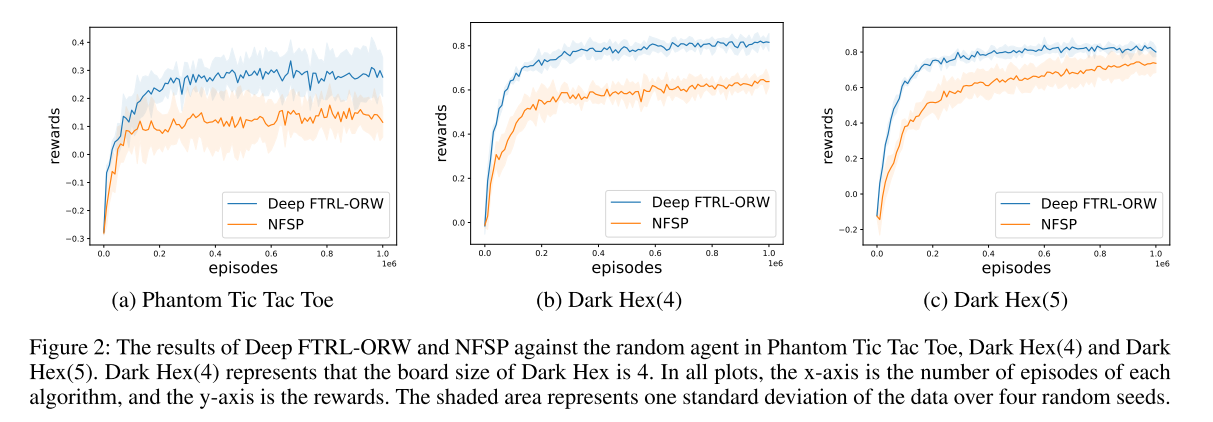
图2:在Phantom Tic Tac Toe、Dark Hex(4)和Dark Hex(5)中,Deep FTRL-ORW和NFSP对抗随机药剂的结果。Dark Hex(4)表示Dark Hex的棋盘大小为4。在所有图中,x轴是每个算法的迭代次数,y轴是奖励。阴影区域表示四个随机种子上的数据的一个标准差。
7、总结
在本文中,我们考虑学习NE在两个球员零和IIEFG完美的回忆。我们提出了一种新的FTRL算法称为FTRL-ORW,它利用对手相关的扩张DGF(ORD-DGF),以解决累积的近似误差所造成的FD扩张DGF。为了将FTRL-ORW算法扩展到大型游戏,我们引入了一种新的神经方法,称为Deep FTRL-ORW。在每次迭代中,它采用最大熵深度强化学习(MEDRL)来计算FTRL-ORW的下一次迭代策略。深度FTRL-ORW是一种无模型方法,它完全从采样轨迹中学习。我们证明了FTRL-ORW和Deep FTRL-ORW分别收敛于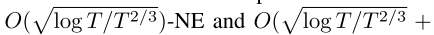

实验结果表明,FTRL-ORW与CFR相比具有竞争力的性能,并且Deep FTRL-ORW显著优于现有的无模型神经方法和OS-MCCFR。















 5428
5428











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









