







Python学习笔记
课程笔记参考B站视频: Python全栈开发教程。
第七站 夫妻站
1. 什么是字典
score = {'张三':100, '李四':98, '王五':45}
score = dict(张三=100, 李四=98, 王五=45)
字典是Python内置的数据结构之一,一个典型的字典如上述代码所示。和列表中所有的元素相互独立不同,字典中存在键值对的概念:冒号之前叫做键,冒号之后叫做值,合称键值对。字典具有以下特性:
- 与列表一样是一个可变序列。可变意味着可以进行增、删、改的操作。
- 字典以键值对的方式存储数据,是一个无序的序列。之所以无序是因为字典根据哈希函数计算出存放位置,所以要求 键一定是不可变序列(不能进行增删改,如字符串、整数序列)。
下图给出了字典的内存示意图,可以看出其根据键的哈希值来存放value:
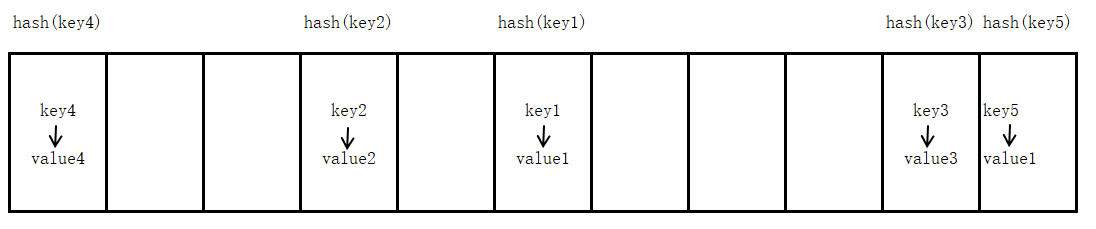
而这种数据结构之所以称之为字典,是因为其实现原理与查字典类似。查字典是先根据部首或拼音查找汉字对应的页码,Python中的字典是根据key计算出其哈希值,进而得到value所在的位置。这种查找方式的效率不会随着元素个数的增多而减少,查找效率非常快。
于是,字典的特点主要有:
- 字典中的所有元素都是一个 key-value对,key不允许重复(否则会出现值覆盖),value可以重复。
- 字典中的元素是无序的。
- 字典中的key必须是不可变对象(比如列表就不可以)。
- 字典也可以根据需要动态地伸缩。
- 字典会浪费较大的内存,是一种使用空间换时间的数据结构。
下面是代码示例:
dic1 = {'name':'张三', 'name':'李四'}
print(dic1)
dic2 = {'name':'张三', 'nickname':'张三'}
print(dic2)
- 运行结果
{'name': '李四'}
{'name': '张三', 'nickname': '张三'}
根据上述代码可以看出,重复定义键会出现值覆盖的问题。下面来具体介绍字典的语法。
2. 字典的创建
字典的创建方式有两种:
- 使用花括号(最常用)。
- 使用内置函数
dict()。
下面是代码示例:
'''
字典的创建方式
'''
print('--------使用花括号创建--------')
score = {'张三':100, '李四':98, '王五':45}
score1 = {'张三':100, '李四':98, '王五':45}
print(type(score), id(score), score)
print(type(score1), id(score1), score1)
print('--------使用dict()创建--------')
height = dict(张三=100, 李四=98, 王五=45)
print(type(height), id(height), height)
print('--------创建空字典------------')
weight = {}
print(type(weight), id(weight), weight)
- 运行结果
--------使用花括号创建--------
<class 'dict'> 1416939971904 {'张三': 100, '李四': 98, '王五': 45}
<class 'dict'> 1416939971968 {'张三': 100, '李四': 98, '王五': 45}
--------使用dict()创建--------
<class 'dict'> 1416940505664 {'张三': 100, '李四': 98, '王五': 45}
--------创建空字典------------
<class 'dict'> 1416940504832 {}
可以看到,由于字典属于可变序列,所以即使元素都相同的两个字典,也会开辟出两个不同内存进行存储。
3. 字典的查询操作
1. 获取字典元素
通常,获取字典中的元素有两种方法:
- 使用方括号
[ ],若字典中不存在指定的key,抛出keyError异常。- 使用字典方法
.get(),若字典中不存在指定的key,返回None,也可以设置返回的值。
下面是代码示例:
'''
获取字典中的元素
'''
score = {'张三':100, '李四':98, '王五':45}
print('--------使用花括号获取---------')
print('张三的值:', score['张三'])
# print('陈六的值:', score['陈六']) # KeyError: '陈六'
print('--------使用.get()获取--------')
print('李四的值:', score.get('张三'))
print('陈六的值:', score.get('陈六', -1)) # -1就是在找不到时返回的值
print('赵七的值:', score.get('赵七')) # 默认值时None
- 运行结果
--------使用花括号获取---------
张三的值: 100
--------使用.get()获取--------
李四的值: 100
陈六的值: -1
赵七的值: None
2. key的判断
在6.2节中说到使用in、not in两个布尔运算符主要用于查找字符串或列表中是否有相应的元素。当然这对于字典元素来说也适用,但只是用来查找键(key)是否存在。
下面是代码示例:
'''
键的判断
'''
score = {'张三':100, '李四':98, '王五':45}
print('张三' in score)
print('李四' not in score)
- 运行结果
True
False
3. 获取字典视图
字典的视图就是字典的键、值、键值对,获取字典视图的方法见下表:
| 字典方法 | 操作描述 |
|---|---|
| .keys() | 获取字典中所有key |
| .values() | 获取字典中所有value |
| .items | 获取字典中所有key,value对 |
下面是代码示例:
score = {'张三':100, '李四':98, '王五':45}
print('---------获取字典中所有的键---------')
names = score.keys()
print(type(names), id(names), names)
names = list(names)
print(type(names), id(names), names) # 将其转化成列表
print('---------获取字典中所有的值---------')
points = score.values()
print(type(points), id(points), points)
print('---------获取字典中所有的键值对------')
kv_s = score.items()
print(type(kv_s), id(kv_s), kv_s)
kv_s = list(kv_s)
print(type(kv_s), id(kv_s), kv_s) # 每个列表元素都是一个元组
- 运行结果
---------获取字典中所有的键---------
<class 'dict_keys'> 2560759785936 dict_keys(['张三', '李四', '王五'])
<class 'list'> 2560759942144 ['张三', '李四', '王五']
---------获取字典中所有的值---------
<class 'dict_values'> 2560759785936 dict_values([100, 98, 45])
---------获取字典中所有的键值对------
<class 'dict_items'> 2560759864816 dict_items([('张三', 100), ('李四', 98), ('王五', 45)])
<class 'list'> 2560759942080 [('张三', 100), ('李四', 98), ('王五', 45)]
4. 字典元素的遍历
字典元素的遍历与列表基本一直,都是采用for循环完成。只不过字典元素遍历的元素只是键(key)。
下面是代码示例:
'''
字典元素的遍历
'''
score = {'张三':100, '李四':98, '王五':45}
for i in score:
print(i, score[i], score.get(i))
- 运行结果
张三 100 100
李四 98 98
王五 45 45
4. 字典元素的增、删、改操作
| 分类 | 字典方法 | 操作描述 |
|---|---|---|
| 增加、修改 | 使用方括号赋值 | 增加、修改字典中一个键值对 |
| 删除 | .clear() | 清空所有键值对,成为空字典 |
| del(内置函数) | 若有索引,则删除字典中一个键值对; 若无索引,删除整个字典。 |
下面是代码示例:
score = {'张三':100, '李四':98, '王五':45}
print('原字典:', score)
print('---------增加字典元素----------')
score['陈六'] = 100
print('增加元素:', score)
print('---------修改字典元素----------')
score['陈六'] = 60
print('修改元素:', score)
print('---------删除字典元素----------')
del score['张三'] # 删除单个元素
print('del删除:', score)
score.clear() # 删除所有元素
print('clear清空', score)
- 运行结果
原字典: {'张三': 100, '李四': 98, '王五': 45}
---------增加字典元素----------
增加元素: {'张三': 100, '李四': 98, '王五': 45, '陈六': 100}
---------修改字典元素----------
修改元素: {'张三': 100, '李四': 98, '王五': 45, '陈六': 60}
---------删除字典元素----------
del删除: {'李四': 98, '王五': 45, '陈六': 60}
clear清空 {}
5. 字典推导式
现在给出两个列表,字典推导式就可以根据这两个列表生成相应的字典。方法就是使用内置函数zip(),其用于将可迭代的对象作为参数,将对象中对应的元素打包成一个元组,然后返回由这些元组组成的列表。基本格式为:
{ 键运算表达式:值运算表达式 for 变量名称1,变量名称2 in zip(列表1,列表2)}
下面是代码示例:
names = ['Jack', 'Jenny', 'LiMing']
points = [92, 88, 98, 100]
print('--------使用字典生成式---------')
dic1 = {i:j for i,j in zip(names, points)}
print(type(dic1), id(dic1), dic1)
print('--------使用字典定义直接生成----')
dic2 = dict(zip(names, points))
print(type(dic2), id(dic2), dic2)
- 运行结果
--------使用字典生成式---------
<class 'dict'> 3139282609472 {'Jack': 92, 'Jenny': 88, 'LiMing': 98}
--------使用字典定义直接生成----
<class 'dict'> 3139283079488 {'Jack': 92, 'Jenny': 88, 'LiMing': 98}
注意zip()会按照元素更少的列表将两个列表进行打包。
6. 本章作业
1. 根据星座测试性格特点
说明:
将十二星座及其对应的像个特点存成一个字典,然后允许用户查询。
下面是代码示例(只有部分星座):
constellation = ['白羊座','金牛座','双子座','巨蟹座','狮子座','处女座','天秤座','天蝎座']
nature = ['积极乐观','固执内向','圆滑世故','多愁善感','迷之自信','精明计较','犹豫不决']
# 将两个列表转成字典
# dic={con:nat for con,nature in zip(constellation,nature)}
dic1 = dict(zip(constellation, nature))
print(dic1)
key = input('请输入您的星座名称:')
print(key,'的性格特点为:', dic1.get(key))
- 运行结果
{'白羊座': '积极乐观', '金牛座': '固执内向', '双子座': '圆滑世故', '巨蟹座': '多愁善感', '狮子座': '迷之自信', '处女座': '精明计较', '天秤座': '犹豫不决'}
请输入您的星座名称:jkijjko
jkijjko 的性格特点为: None
2. 模拟12306火车票订票下单
说明:
下面是代码示例:
dict_ticket = {'G1569': ['北京南-天津南','18:05','18:39','00:34'],
'G1567': ['北京南-天津南','18:15','18:49','00:34'],
'G8917': ['北京南-天津西','18:20','19:19','00:59'],
'G203' : ['北京南-天津南','18:35','19:09','00:34']}
print('车次\t\t出发站-到达站\t\t出发时间\t\t到达时间\t\t历时时长')
for item in dict_ticket:
print (item, end='\t')
for i in dict_ticket[item]:
print(i, end='\t\t')
print() # 换行
#输入要购买的车次
train_no = input('请输入要购买的车次:')
persons = input('请输入乘车人,如果是多人请使用逗号分隔:')
s = f'您已购买了 {train_no} 次列车车票,'
s_info = dict_ticket[str(train_no)] # 获取车次详细信息
s += s_info[0] + ' ' + s_info[1] + ' 开,'
print(f'{s}请 {persons} 尽快取走纸制车票。[铁路客服]')
- 运行结果
车次 出发站-到达站 出发时间 到达时间 历时时长
G1569 北京南-天津南 18:05 18:39 00:34
G1567 北京南-天津南 18:15 18:49 00:34
G8917 北京南-天津西 18:20 19:19 00:59
G203 北京南-天津南 18:35 19:09 00:34
请输入要购买的车次:G1567
请输入乘车人,如果是多人请使用逗号分隔:张三,李四
您已购买了 G1567 次列车车票,北京南-天津南 18:15 开,请 张三,李四 尽快取走纸制车票。[铁路客服]
注:上述程序在输入不存在的列车车次时会报错。



















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











