







 文章介绍了在准备统计建模比赛论文时,使用不同数据库如国研网、国家统计局、CSMAR、Wind和CNKI等收集和处理数据的经验。其中,国研网的数据结构友好,适合面板数据,而国家统计局的数据需手动整合。CSMAR不能跨表查询,Wind能跨表但数据结构不友好。文章还讨论了数据从宽到长的转换方法,使用stata的reshape命令。对于无权限的用户,国家统计局网站可能是主要的数据来源。
文章介绍了在准备统计建模比赛论文时,使用不同数据库如国研网、国家统计局、CSMAR、Wind和CNKI等收集和处理数据的经验。其中,国研网的数据结构友好,适合面板数据,而国家统计局的数据需手动整合。CSMAR不能跨表查询,Wind能跨表但数据结构不友好。文章还讨论了数据从宽到长的转换方法,使用stata的reshape命令。对于无权限的用户,国家统计局网站可能是主要的数据来源。
最近在准备统计建模比赛论文,用到了统计年鉴的数据,尤其是中国统计年鉴。然而收集数据也巨多坑,填一下方便后来需要者。
根据数据时效性、完整性、结构友好性综合从高到底对各数据库收集数据进行记录
国研网
百度直接搜 国研网
我需要研究省级经济数据,我会示范一下数据收集的基本过程
- 点击省级经济
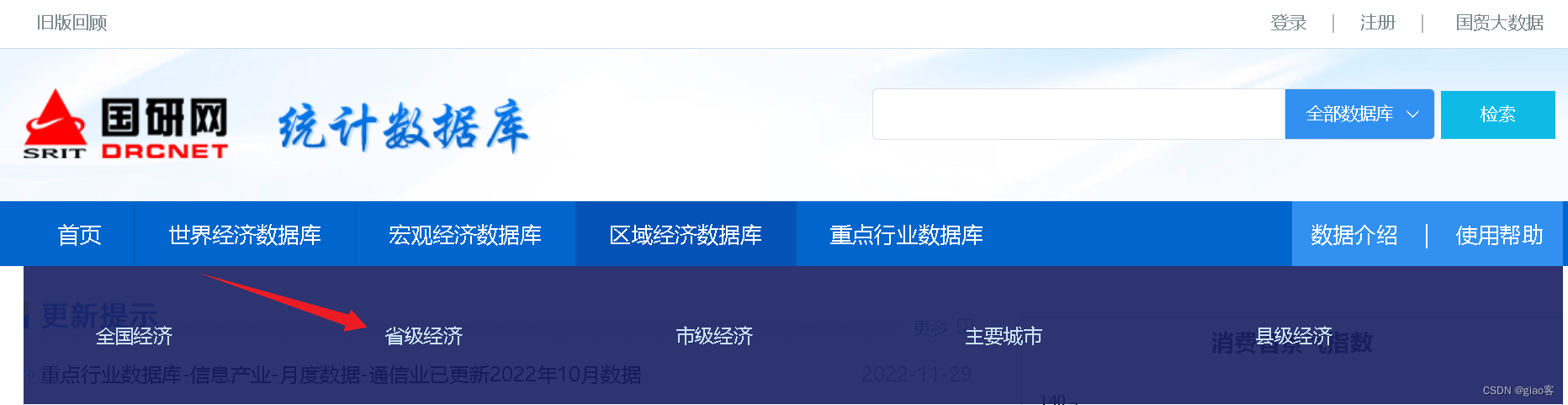
- 选择自己的数据频率
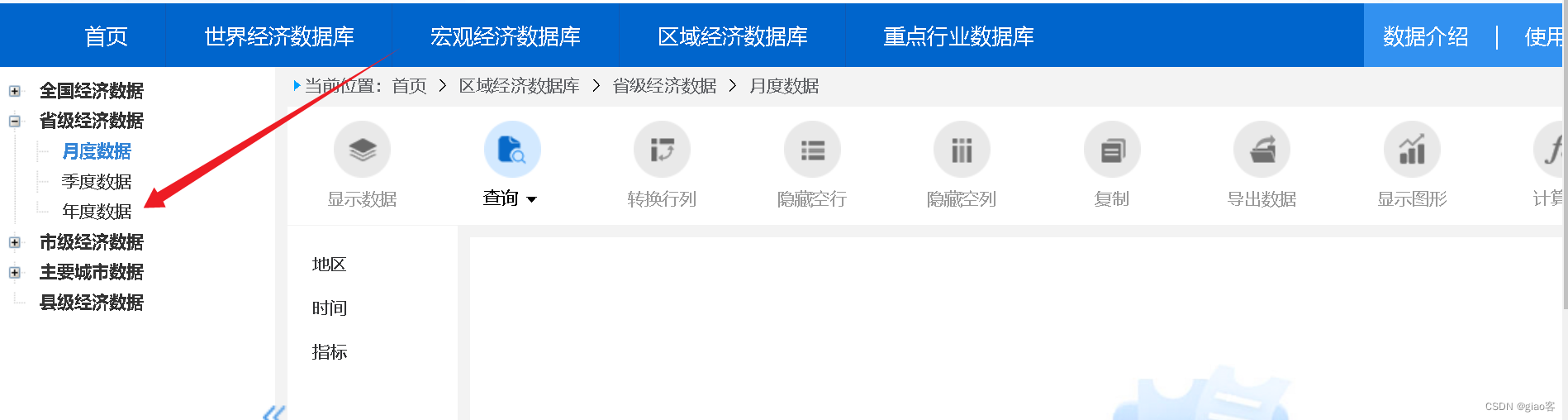
- 选择地区

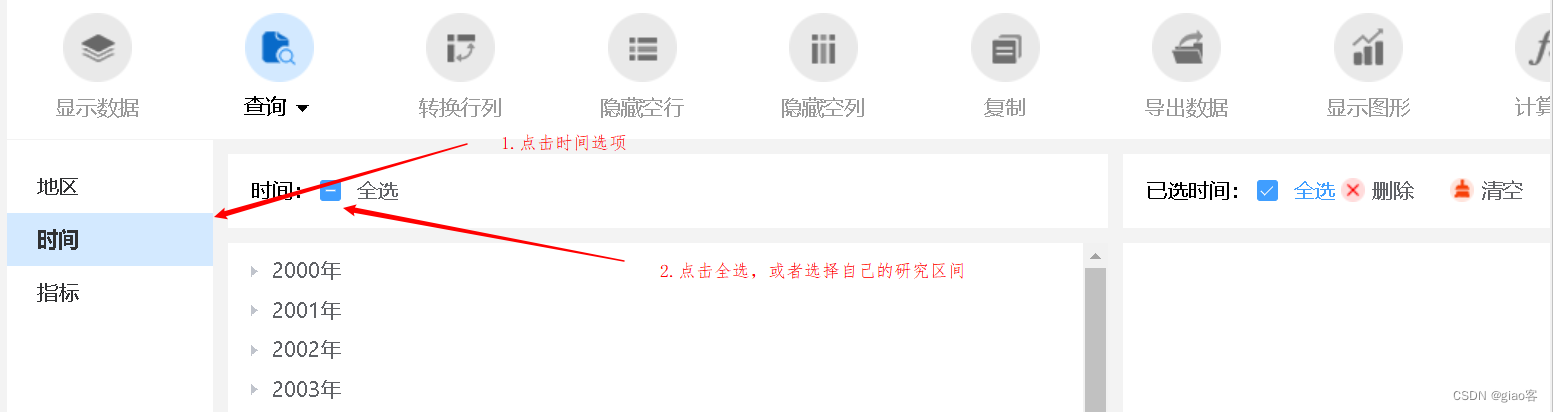
- 选择时间
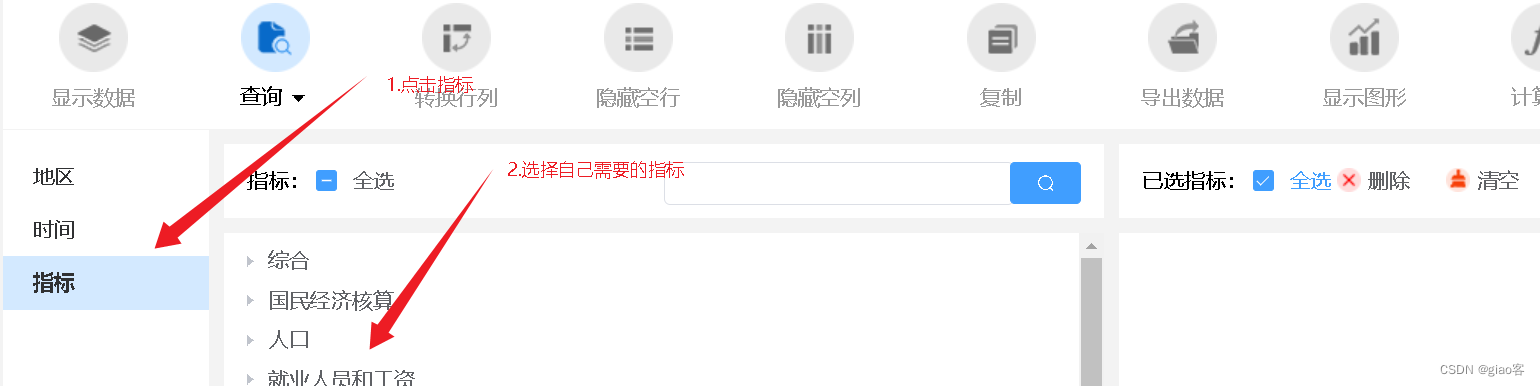
- 选择指标
- 显示数据

国研网的数据结构友好,就是常用的计量经济学的那种面板数据结构(长数据结构),而且数据操作界面友好易懂
国家统计局
这个没得说是中国统计年鉴的编制单位,所以数据权威性得到保证,但是自己的数据管理也存在问题,比如2013年之前收集的一些统计数据居然没有整合到数据库中,需要自己查询具体的年鉴查询。
- 选择自己需要的数据子库
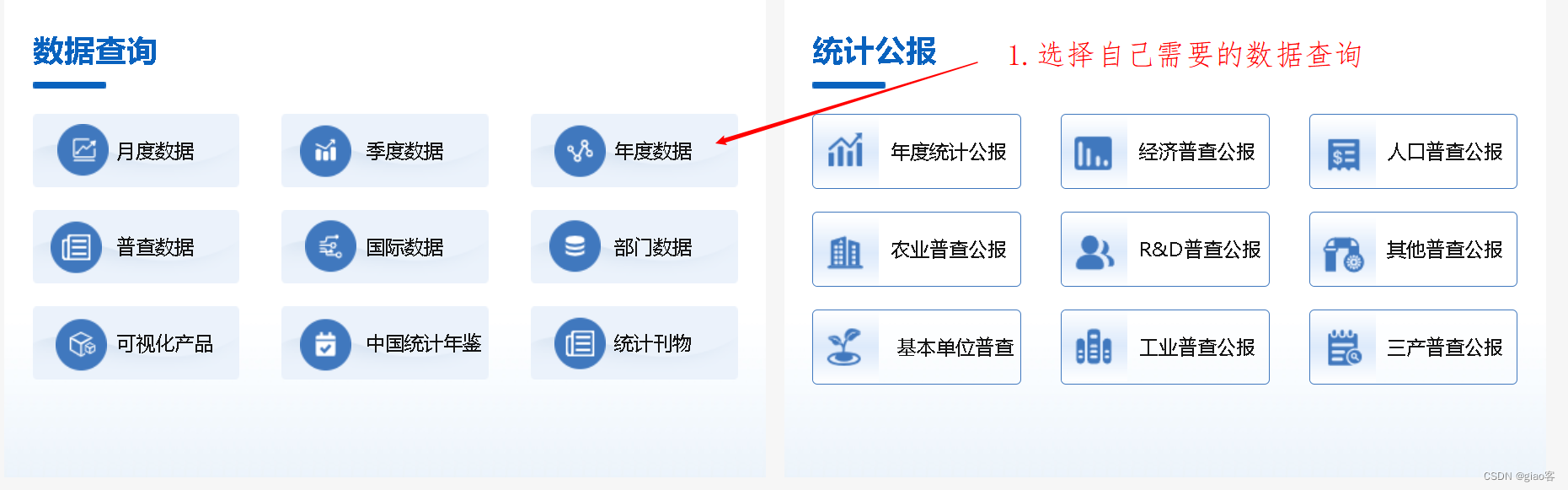
2. 选择具体的数据查询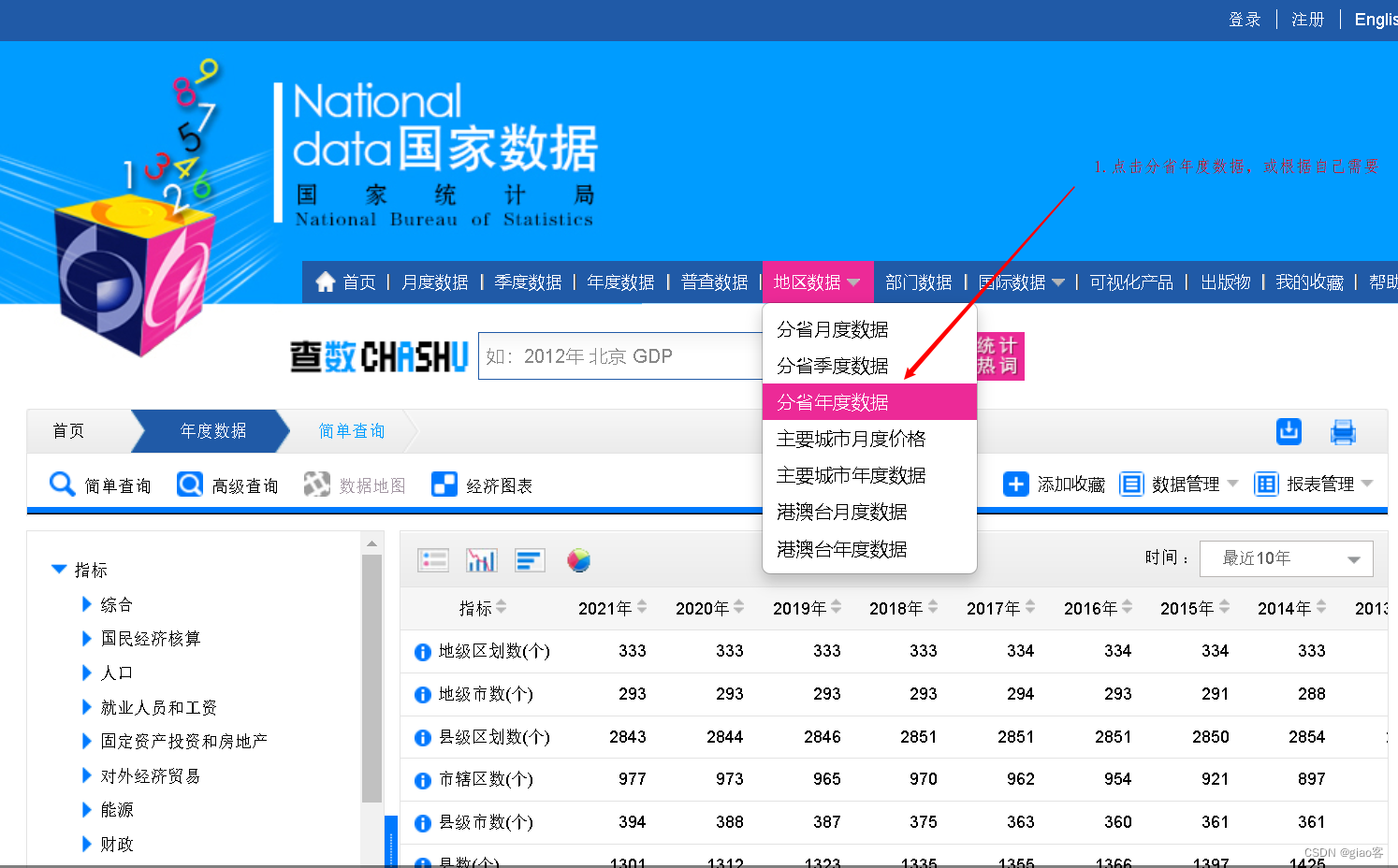
3. 选着地区和指标
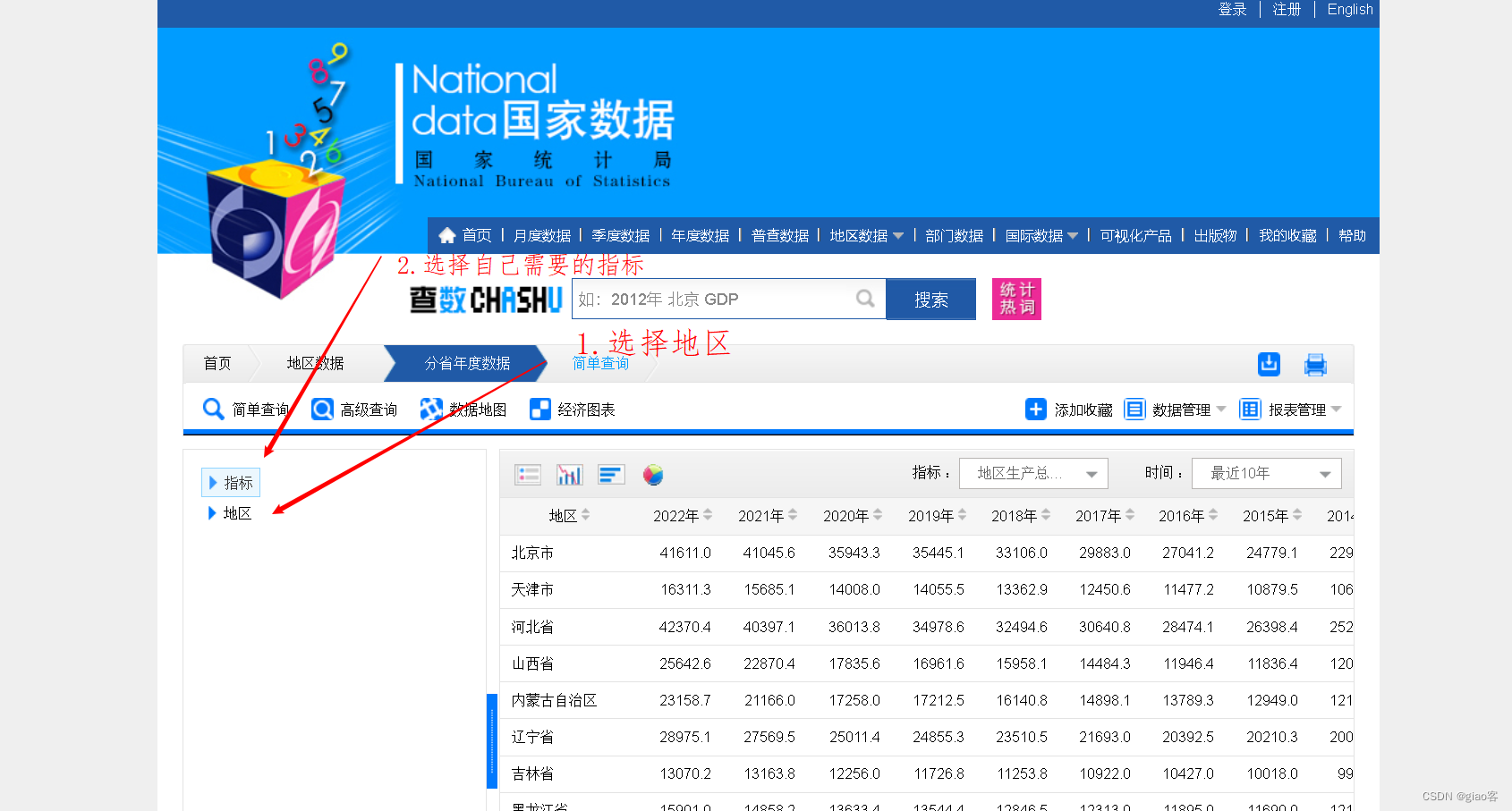
需要注意的是,有时即使你在第一步选择了分省年度数据,查询的结果也只有北京市的数据,这时通过步骤二中的地区选项可以选择所有的省。这是国家统计局数据库一个需要注意的点。
CSMAR国泰安
不能跨表查询(除非是个人账号),数据结构友好,操作通俗易懂
Wind万得
能够跨表查询,数据结构不友好(输出是宽数据),操作性不友好,而且需要指定终端才能使用该数据。
CNKI知网统计数据
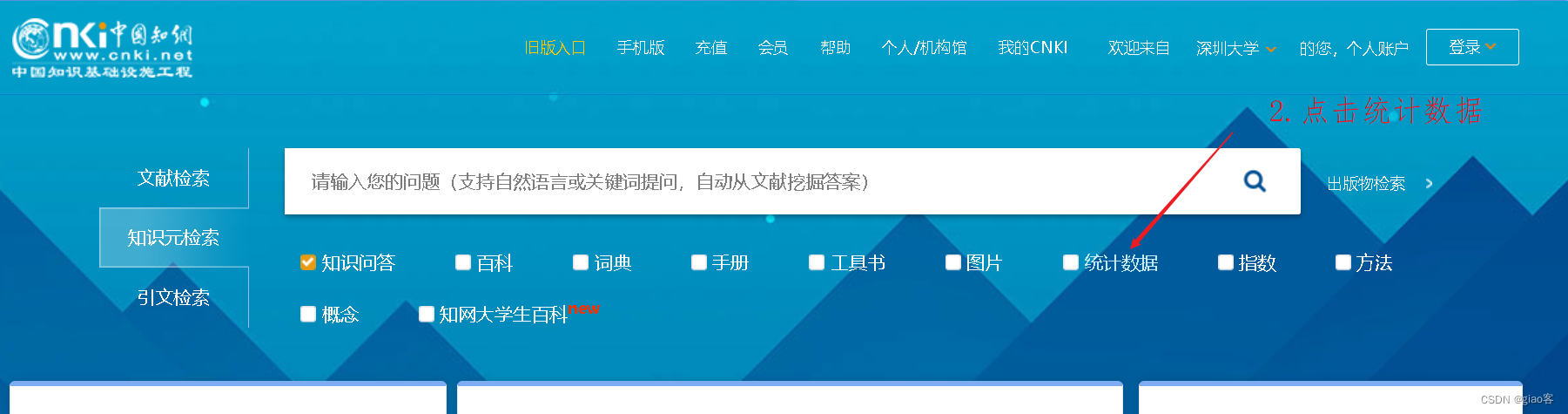
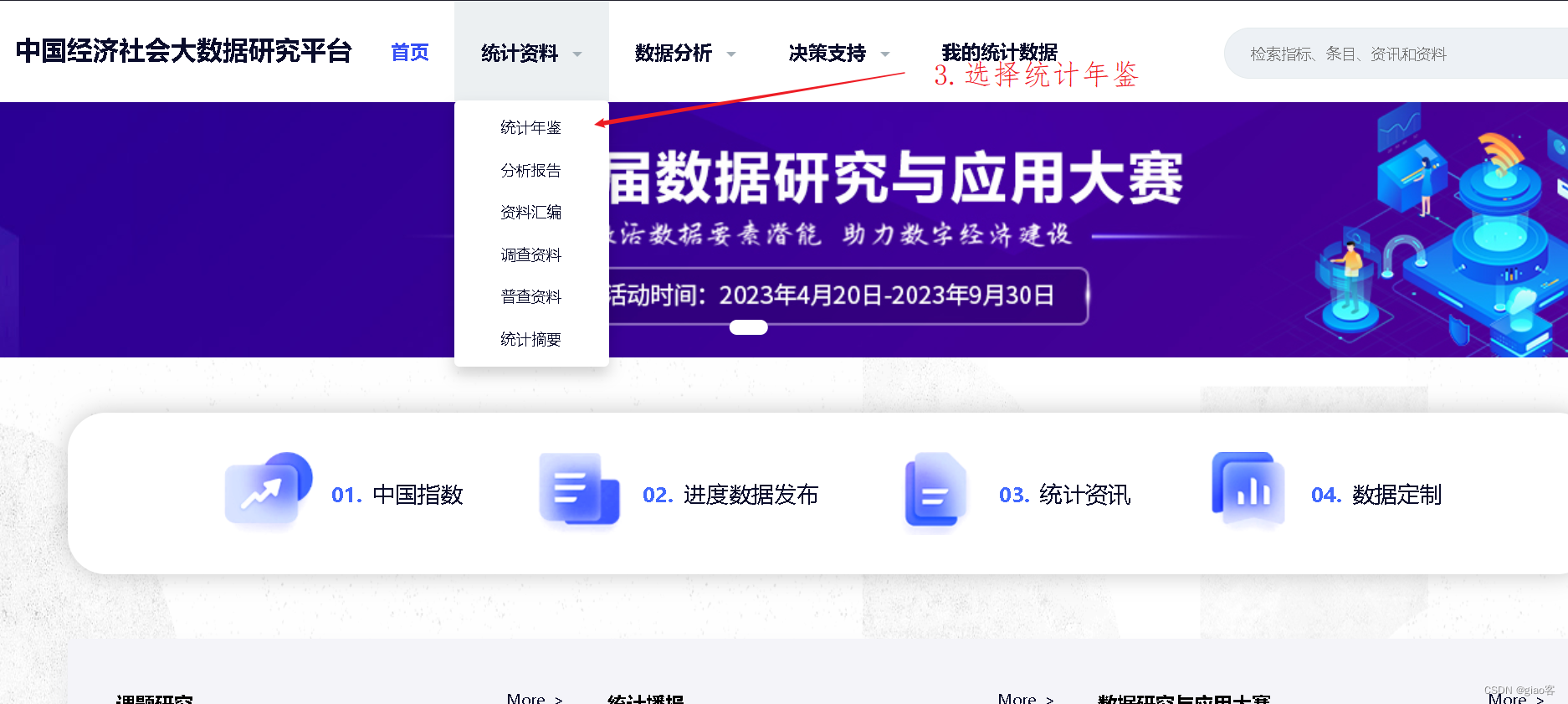
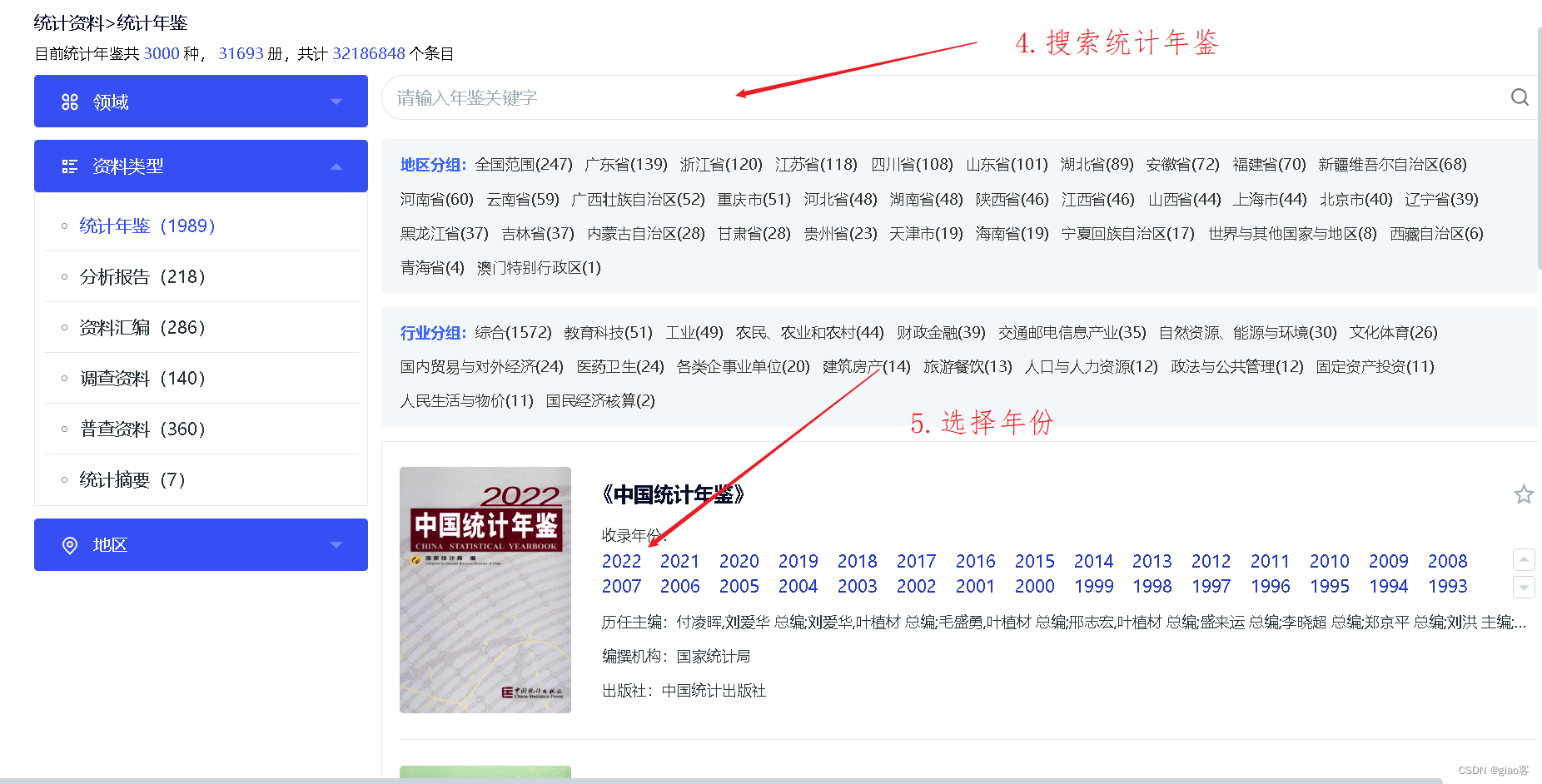
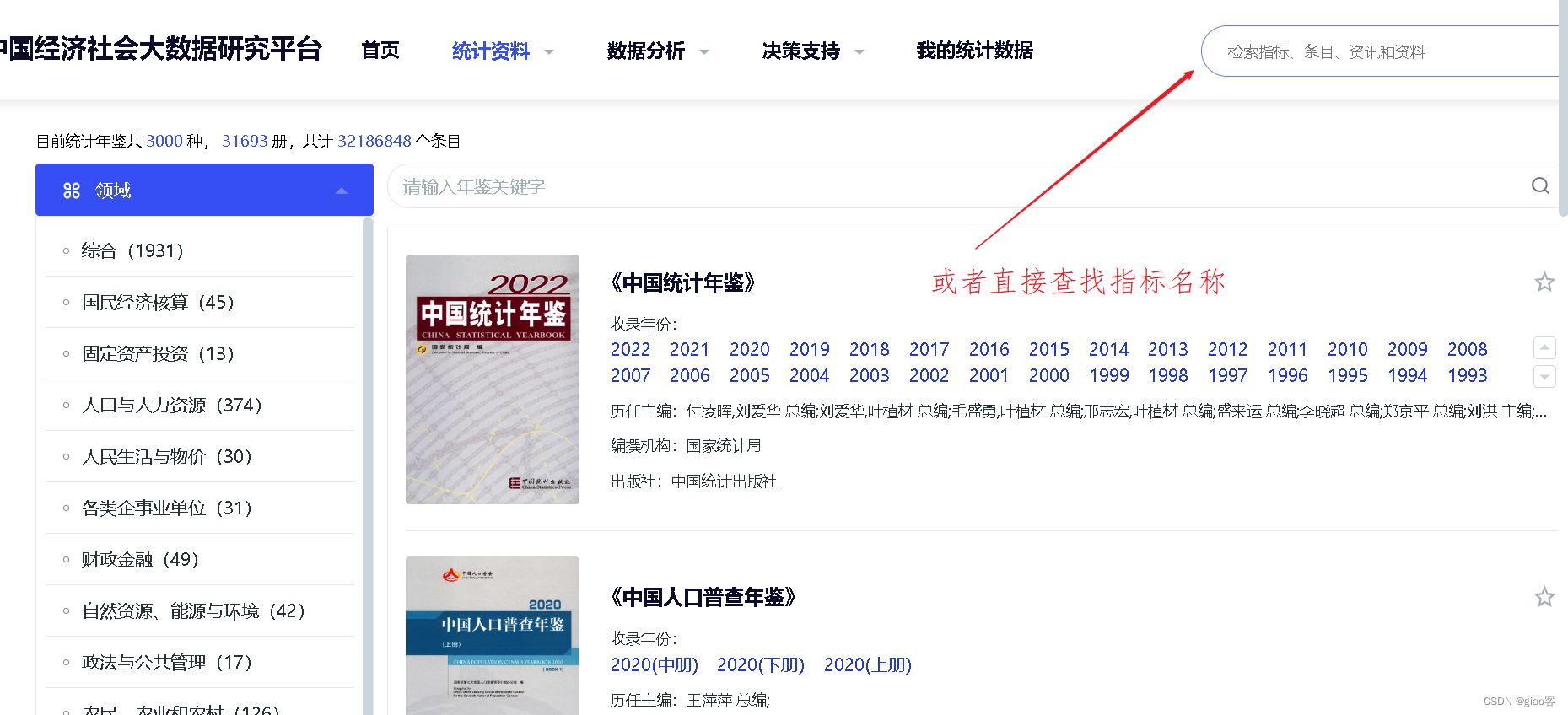
宽数据转换为长数据——stata的reshape
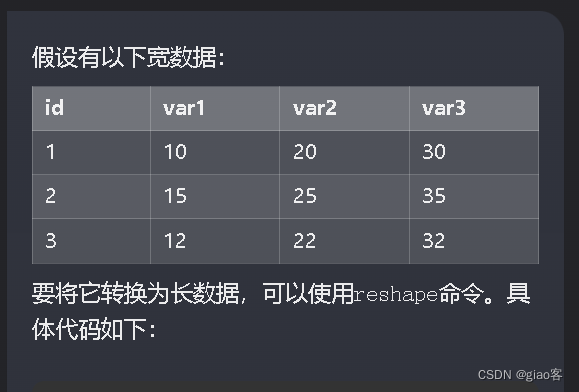
长宽数据转换—— reshape命令
在面板数据中,如果包含两个标识变量,则数据有两种表现形式,一种是长数据,一种是宽数据。在长宽数据的转换中,所使用到的命令为
reshape,具体命令语句为:
reshape long stubnames, i(varlist) [options]
reshape wide stubnames, i(varlist) [options]
语句中,
reshape代表数据转换的命令,
long表示将宽数据转化为长数据,
wide表示将长数据转化成宽数据,
stubnames表示需要转化的变量名称前缀,
i(varlist)表示识别变量。
options最常用的为 j(varname [values]),它表示用来进行长宽变换的变量名称,通常为时间变量。
参考资料
// 导入数据
clear
input id var1 var2 var3
1 10 20 30
2 15 25 35
3 12 22 32
end
// 将宽数据转换为长数据
reshape long var, i(id) j(variable)
rename var value
// 查看转换后的数据
list
wide to long (宽数据转化为长数据)
reshape long X1 X2,i(ID) j(list) string
Note: 每个样本的唯一识别码是ID,需要转换的变量是X1*、X2*(星号表示通配符),可将X1_1 X1_2转换为X1,并将"_1"和"_2"作为新生成变量list的值,list不是数值型,因此需要加上string选项
long to wide (长数据转化为宽数据)
reshape wide X1 X2,i(ID) j(list) string
Note: 转换为宽数据后,ID应作为唯一识别码,需要将X1、X2转换为X1*、X2*,其中*是对应list的取值。若list不是数值型,应当加上string选项
参考资料
综合评价
根据个人研究方向,和使用情况进行评价。
| 数据库 | 界面友好性 | 数据结构(长/短数据) | 能否跨表查询 | 数据更新情况 | 使用权限 |
|---|---|---|---|---|---|
| 国研网 | 好 | 长数据,友好 | 能 | 较好,可能会有一年延迟 | 需要权限 |
| 国家统计局 | 较好 | 宽数据,不友好 | 能,但是有限制 | 自己收集的数据,更新情况没得说 | 无需购买,但是要注册 |
| CSMAR | 好 | 长数据,友好 | 不能,只能在单表中查询 | 好,数据更新情况良好 | 需要权限 |
| wind | 不友好,需要去指定终端使用 | 宽数据,不友好 | 能,但是有输出限制 | 较好,可能会有一年延迟 | 需要权限 |
总的来说,就《中国统计年鉴》的数据查询来说。如果没有权限的话,只能去国家统计局自己一个一个下载数据。若是学校有条件的话,首先推荐国研网数据库,然后再使用国家统计局和csmar数据库对部分数据进行补充。


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









