






前言
提示:这里可以添加本文要记录的大概内容:
例如:随着人工智能的不断发展,机器学习这门技术也越来越重要,很多人都开启了学习机器学习,本文就介绍了机器学习的基础内容。
提示:以下是本篇文章正文内容,下面案例可供参考
一、导数?
导数就是表示某个瞬间的变化量。他可以定义成下面的式子
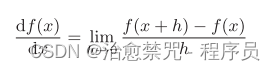
左边的式子表示f(x)关于x的导数,即f(x)相对于x的变化程度。
这个式子可以用一段python代码表示出来
def numerical_diff(f,x):
h=1e-4
return (f(x+h)-f(x-h))/(2*h)
二、偏导数
有多个变量的函数的导数成为偏导数。用数学式表示的话:

如何求偏导:偏导数需要将多个变量中的某一个变量定为目标变量,并将其他变量固定为某个值。
代码如下(示例):
梯度
由全部变量的偏导数汇总而成的向量称为梯度。
梯度指示的方向是各点处的函数值减小最多的方向。
机器学习的主要任务是在学习时寻找最优参数。同样的,神将网络也必须在学习时找到最优参数(权重和偏置)
虽然梯度的方向并不一定指向最小值,但沿着他的方向能狗最大限度的减小函数的值。因此,在寻找函数的最小值(或者尽可能小的值)的位置的任务中,要以梯度为线索,决定前进的方向。
梯度下降法:寻找最小值的梯度法
梯度上升发:寻找最大值的梯度法
用python来求函数的梯度:
def numerical_gradient(f,x):
h=1e-4
grad=np.zeros_like(x)
for idx in range(x.size):
tmp_val=x[idx]
#计算f(x+h)
x[idx]=tmp_val+h
fxh1=f(x)
#计算f(x-h)
x[idx]=tmp_val-h
fxh2=f(x)
grad[idx]=(fxh1-fxh2)/(2*h)
x[idx]=tmp_val
return grad
用python来实现梯度下降法
def gradient_descent(f, init_x,lr=0.01,step_num=100):
x= init_x
for i in range (step_num):
grad =numerical_gradient(f, x)
x- =lr*grad
return x
参数解释:
f:要进行优化的参数
init_x:初始值
lr:学习率learning rate
step_num:梯度法的重复次数
神经网络中的梯度
神经网络中的梯度指的应该是损失函数关于权重参数的梯度。根据梯度下降的方向更新参数,才能让损失函数更快的下降。















 4188
4188











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









