






python-docx读取Word文件
在做数据分析时,虽然操作docx并不是常用操作,但有些时候,数据分析师拿到的文件是docx或doc的Word文件,尤其是对数据具有至关重要的数据字典。接下来以一个数据字典为例来介绍下python-docx读取Word文件的基本操作。并将Word中的表格内容写入excel中。
python-docx官网地址
https://python-docx.readthedocs.io/en/latest/dev/analysis/index.html
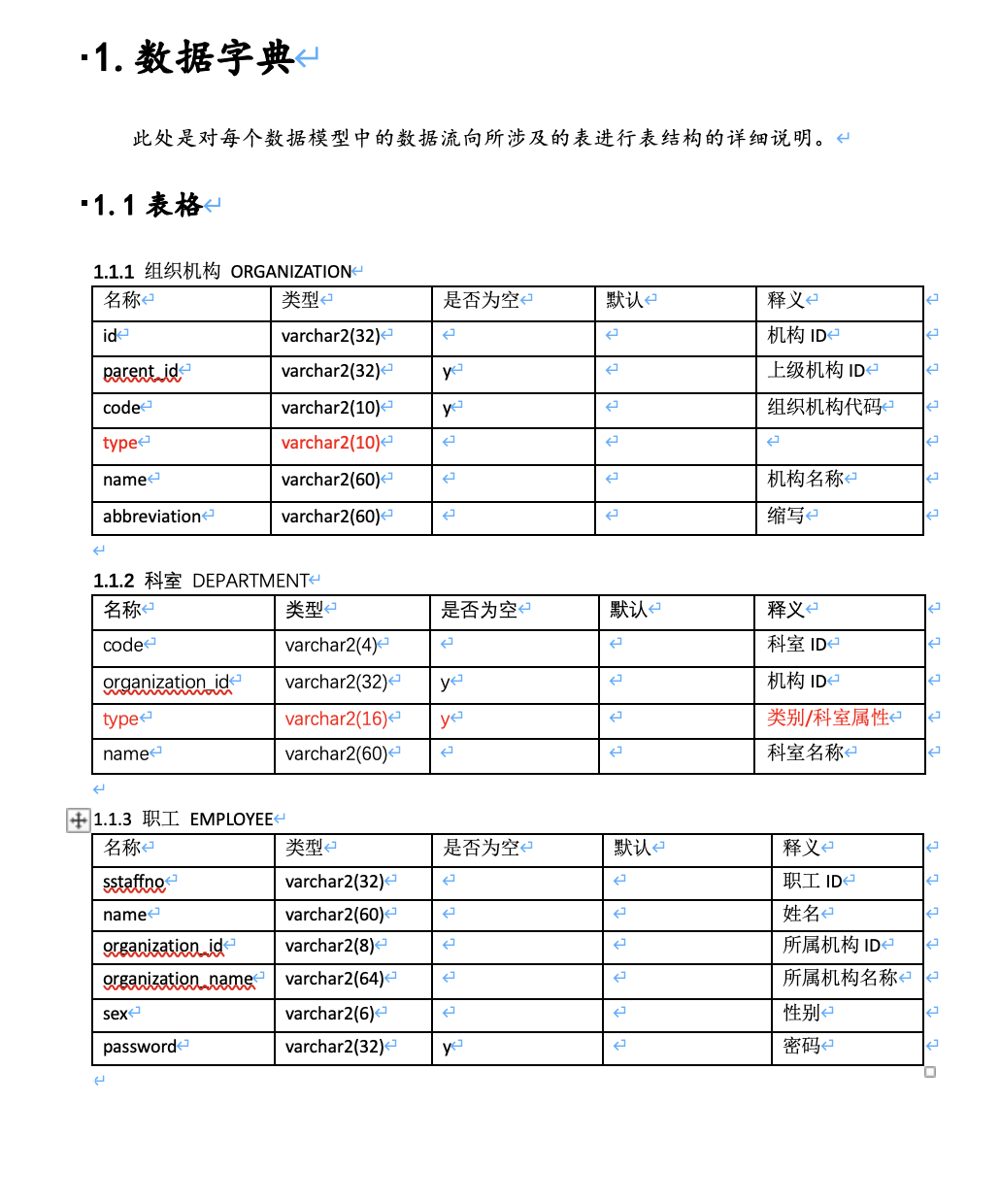
Word原文件
安装python-docx
>>> pip install python-docx
Collecting python-docx
Downloading python-docx-0.8.10.tar.gz (5.5 MB)
|████████████████████████████████| 5.5 MB 1.1 MB/s
Requirement already satisfied: lxml>=2.3.2 in
...
Successfully built python-docx
Installing collected packages: python-docx
Successfully installed python-docx-0.8.10
读取文件
from docx import Document
# 打开文档
doc = Document('word.docx')
# 读取每段内容
pl = [ paragraph.text for paragraph in doc.paragraphs]
# 输出读取到的内容
for i in pl:
print(i)
1.数据字典
此处是对每个数据模型中的数据流向所涉及的表进行表结构的详细说明。
1.1表格
1.1.1 组织机构 ORGANIZATION1.1.2 科室 DEPARTMENT
1.1.3 职工 EMPLOYEE
读取标题
from docx import Document
doc = Document('word.docx')
for p in doc.paragraphs:
style_name = p.style.name
if style_name.startswith('Heading'):
print(style_name,p.text,sep=':')
Heading 1:1.数据字典
Heading 2:1.1表格
这边主要用到style属性,可以通过p.style.name查看每段内容的style。
for p in doc.paragraphs:
print(p.style.name)
Heading 1
List Paragraph
Heading 2
Normal
Normal
Normal
Normal
Normal
Normal
读取一级标题
for p in doc.paragraphs:
style_name = p.style.name
if p.style.name == 'Heading 1':
print(p.text)1.数据字典
读取所有标题
import re
for p in doc.paragraphs:
if re.match('^Heading \d+$', p.style.name):
print(p.text)1.数据字典
1.1表格
读取正文
for p in doc.paragraphs:
if p.style.name == 'Normal':
print(p.text)读取其他内容
from docx.enum.style import WD_STYLE_TYPE
for s in doc.styles:
if .name == WD_STYLE_TYPE.PARAGRAPH:
print(s.name)都有哪些style.name可以在官网查看(https://python-docx.readthedocs.io/en/latest/api/enum/WdBuiltinStyle.html):
读取表格
使用tables属性,可以读取所有的表格;
from docx import Document
document = Document("word.docx")
for each in document.tables:
print(each)
print(document.tables[0].cell(0,0).text)
<docx.table.Table object at 0x7fb75c042450> # 表格对象
<docx.table.Table object at 0x7fb75c042210>
<docx.table.Table object at 0x7fb75c042650>
名称 # 第一个表格中第一个单元格的内容
本例读取方法如下:
# 读取表格材料,并输出结果
tables = [table for table in doc.tables]
for table in tables:
for row in table.rows:
for cell in row.cells:
print(cell.text,end=' ')
print()
print('\n')
名称 类型 是否为空 默认 释义
id varchar2(32) 机构ID
parent_id varchar2(32) y 上级机构ID
code varchar2(10) y 组织机构代码
type varchar2(10)
name varchar2(60) 机构名称
abbreviation varchar2(60) 缩写名称 类型 是否为空 默认 释义
code varchar2(4) 科室ID
organization_id varchar2(32) y 机构ID
type varchar2(16) y 类别/科室属性
name varchar2(60) 科室名称名称 类型 是否为空 默认 释义
sstaffno varchar2(32) 职工ID
name varchar2(60) 姓名
organization_id varchar2(8) 所属机构ID
organization_name varchar2(64) 所属机构名称
sex varchar2(6) 性别
password varchar2(32) y 密码
下面扩展两个常用操作。
doc转docx
由于python-docx只能处理docx格式的Word文档,如果需要对doc格式的文档进行处理,则需要将doc转docx,再进行处理。
安装
python -m pip install pypiwin32
完整操作
import os
import time
import win32com
from win32com.client import Dispatch
def doc_to_docx(path):
# 调用word程序
w = win32com.client.Dispatch('Word.Application')
# 后台运行,不显示,不警告
w.Visible = 0
w.DisplayAlerts = 0
doc = w.Documents.Open(path)
# 这里必须要绝对地址,保持和doc路径一致
newpath = allpath+'\\转换后的文档.docx'
time.sleep(3) # 暂停3s,否则会出现-2147352567,错误
doc.SaveAs(newpath,12,False,"",True,"",False,False,False,False)
# doc.Close() 开启则会删掉原来的doc
w.Quit()# 退出
return newpath
allpath = os.getcwd()
print(allpath)
doc_to_docx(allpath+'\\转换前的文档.doc')
转换word为pdf
import win32com
from win32com.client import Dispatch, constants
import os
# 生成PDF文件
def funGeneratePDF():
word = Dispatch("Word.Application")
word.Visible = 0 # 后台运行,不显示
word.DisplayAlerts = 0 # 不警告
doc = word.Documents.Open(os.getcwd() + "\\win32com转换word为pdf等格式.docx")
# 打开一个已有的word文档
doc.SaveAs(os.getcwd() + "\\win32com转换word为pdf等格式.pdf", 17)
# txt=4, html=10, docx=16, pdf=17
doc.Close()
word.Quit()
openpyxl写入Excel
使用第三方模块:openpyxl
pip install openpyxl
新建一个新的Excel
先导入openpyxl模块,并且创建一个工作簿,且创建了一个只包含一个工作表的工作簿。
import openpyxl
mywb = openpyxl.Workbook()
确认工作表的名字,数量和活动的工作表。
>>> mywb.get_sheet_names()
['Sheet']
>>> sheet = mywb.active
>>> sheet.title
'Sheet'
修改工作表名称,并保存。
>>> sheet.title = 'DataDict'
>>> wb.get_sheet_names()
['DataDict']
>>> mywb.save('NewExcelFile.xlsx')
载入Excel文件并保存
在把一个现有的excel文件读入内存,并对它进行一系列修改之后,必须使用save()方法,将其保存,否则所有的更改都会丢失。
import openpyxl
mywb = openpyxl.load_workbook('filetest.xlsx')
sheet = mywb.active
sheet.title = 'Working on Save as'
mywb.save('example_filetest.xlsx')
创建一个新工作表sheet
>>> import openpyxl
>>> mywb = openpyxl.Workbook()
>>> mywb.get_sheet_names()
['Sheet']
>>> mywb.create_sheet()
<Worksheet "Sheet1">
>>> mywb.get_sheet_names()
['Sheet', 'Sheet1']
>>> wb.create_sheet(index=0, title='1st Sheet')
<Worksheet "1st Sheet">
>>> mywb.get_sheet_names()
['1st Sheet', 'Sheet', 'Sheet1']
>>> mywb.create_sheet(index=2, title='2nd Sheet')
<Worksheet "2nd Sheet">
>>> mywb.get_sheet_names()
['1st Sheet', 'Sheet', '2nd Sheet', 'Sheet1']
使用create_sheet()方法创建的新工作表默认排在工作簿的最后一个,也可以用index具体规定新建工作表的位置,并且可以在创建的同时对其命名。使用index排序的规则继承了python的排序方法,index 从0开始。
删除工作表
>>> mywb.get_sheet_names()
['1st Sheet', 'Sheet', '2nd Sheet', 'Sheet1']
>>> mywb.remove_sheet(mywb.get_sheet_by_name('1st Sheet'))
>>> mywb.remove_sheet(mywb.get_sheet_by_name('Sheet1'))
>>> mywb.get_sheet_names()
['Sheet', '2nd Sheet']
在最后不要忘记使用save()方法对所作更改进行保存。
向单元格中写入数据
>>> import openpyxl
>>> mywb = openpyxl.Workbook()
>>> mysheet = mywb.get_sheet_by_name('Sheet')
>>> mysheet['F6'] = 'Writing new Value!'
>>> mysheet['F6'].value
'Writing new Value'
cell
同样可以用cell()函数指向单元格,并且对其写入数据。
>>> import openpyxl
>>> mywb = openpyxl.Workbook()
>>> mysheet = mywb.get_sheet_by_name('Sheet')
>>> mysheet.cell(row=2, column=4).value = 'Let\'s try again!'
>>> mysheet['D2'].value
'Let\'s try again!'
append
对于写入,只需要建立一个list进行append就好了,如果excel为空的那append就从第一行开始递增操作,你也可以理解为一个ws.append()操作就相当于写入一行,如果excel为有数据的时候,那写入操作从没有数据的那一行开始写入。
# coding=utf-8
from openpyxl import Workbook
import numpy as np
wb = Workbook()
ws = wb.create_sheet("test")
label = [[0],
[1],
[2],
[3]]
feature = [[11, 12, 13, 14, 15],
[21, 22, 23, 24, 25],
[31, 32, 33, 34, 35],
[41, 42, 43, 44, 55],]
# 多数时候是在numpy格式下计算的,因此此处模拟一下预处理
label = np.array(label)
feature = np.array(feature)
label_input = []
for l in range(len(label)):
label_input.append(label[l][0])
label_input
>>> [0, 1, 2, 3]
ws.append(label_input)
for f in range(len(feature[0])):
ws.append(feature[:, f].tolist())
wb.save("test.xlsx")
得到结果如下:

因此,我们将上面读取过程稍作修改,边读取边写入。
from openpyxl import Workbook
from docx import Document
# 打开文档
doc = Document('word.docx')
# 新建一个工作簿
wb = Workbook()
# 新建一个工作表,并命名为'word'
ws= wb.create_sheet("word")
# 读取表格材料,并输出结果
tables = [table for table in doc.tables]
for table in tables:
for row in table.rows:
list_rows = []
for cell in row.cells:
list_rows.append(cell.text)
# print(list_rows)
ws.append(list_rows)
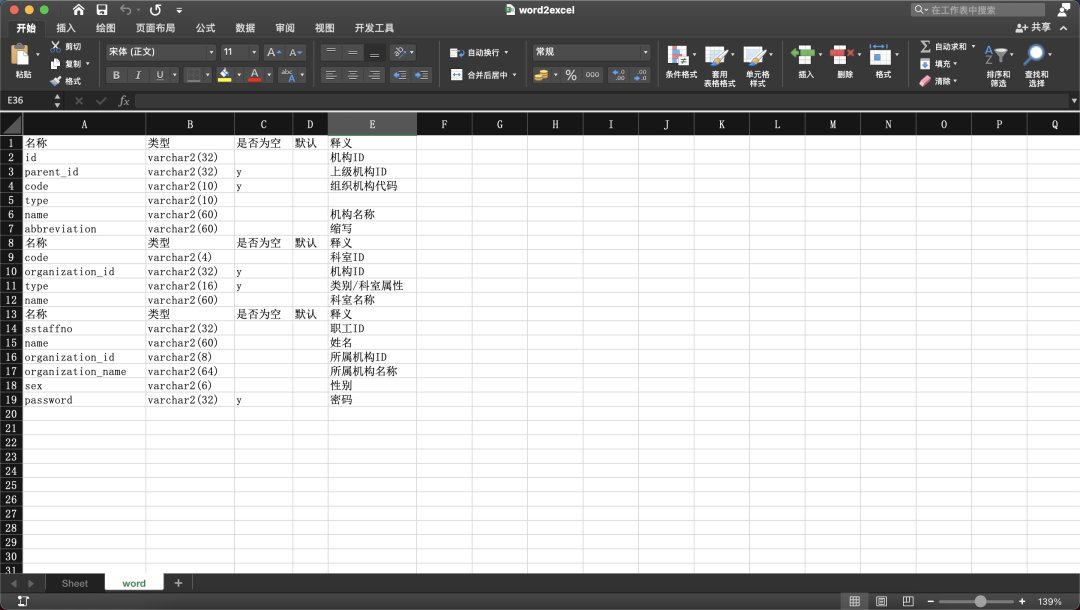
wb.save("word2excel.xlsx")
得到:
报错处理
最后介绍一个报错,避免踩坑。
-- 数据STUDIO --moduleNotFoundError:No module named 'exceptions'
主要还是直接下载docx版本不兼容
如果pip install docx 过请先卸载,输入如下指令:
pip uninstall docx
方法一:
pip install python-docx
方法二:
下载:python_docx-0.8.6-py2.py3-none-any.whl
下载地址:http://www.lfd.uci.edu/~gohlke/pythonlibs/
命令行输入pip install python_docx-0.8.6-py2.py3-none-any.whl 重新下载docx包,问题解决。(豆瓣源)
pip(3) install python-docx -i http://pypi.douban.com/simple/ --trusted-host pypi.douban.com


















 3138
3138

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









