







 本文介绍如何使用Python脚本统计文本中字符及词语的出现频率,并通过实例演示了统计过程及结果展示。
本文介绍如何使用Python脚本统计文本中字符及词语的出现频率,并通过实例演示了统计过程及结果展示。
有时候生活中会遇到这样的问题,需要统计文档里面的出现的字符的次数,或者是所有词语出现的次数,我们需要简便的,自动化的办法去解决。Python脚本是最好的解决办法。
本案例使用的都是读取txt文件,然后去统计其词频,如果你是word文档,可以把文档中的字符复制到txt文件里面,然后再运行代码。
上代码
统计文字出现次数
这里演示的案例文档是我下载的一本玄幻小说 “蛊真人.txt”,我们来统计里面出现的文字的个数。
import pandas as pd
f=open('蛊真人.txt','r')
txt=f.read()
d={}
for word in txt:
d[word]=d.get(word,0)+1
biaodian='‘’,。、!?;:()“” '
for i in biaodian:
del d[i]
f.close()
df=pd.DataFrame([d]).T
df=df.iloc[:,0].sort_values(ascending=False)
df.to_excel('字符统计.xlsx')
上述代码先打开文件,创建了一个空字典,然后将文字一个一个遍历进行统计,已经存在字典里面的文字的值就+1,没有就返回0然后+1。
然后将中文常见的标点写出字符串,将他们都从字典里面一一删除。
最后利用我们的pandas库将字符排个序,存成excel文件。运行后这个文件夹下会多出一个excel文件,结果如下:
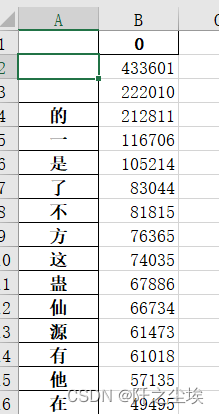
空白也算在里面了....不过问题不大可以手动删除。可以看到除了空白外,出现次数最多的字是“的”,很符合中文的使用情况。
统计词语出现次数
如果需要统计词语,那么就需要借助jieba库进行切词,然后再进行差不多的操作。
import pandas as pd
import jieba
f=open('蛊真人.txt','r')
txt=f.read()
txt=jieba.lcut(txt)
d={}
for word in txt:
d[word]=d.get(word,0)+1
biaodian='‘’,。、!?;:()“” '
for i in biaodian:
del d[i]
f.close()
df=pd.DataFrame([d]).T
df=df.iloc[:,0].sort_values(ascending=False)
df.to_excel('词语统计.xlsx')
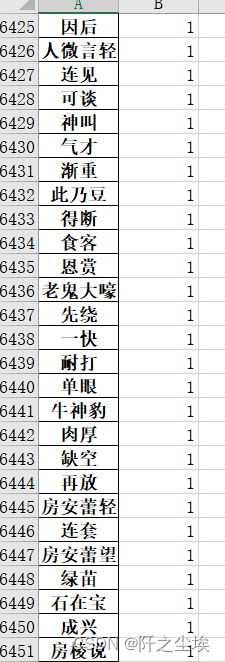
运行结果如下:
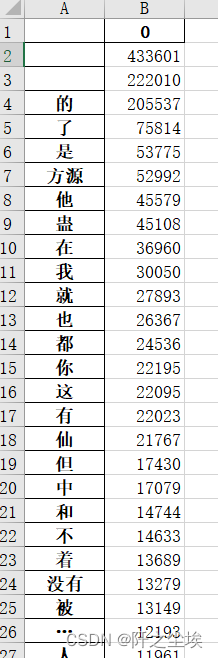
可以看见统计出来的不再全是一个一个的字,有词语的出现了。
前面出现频率高的还是中文里面常见的副词虚词,“方源”是书里面的主角,所以出现次数也多.....
后面频率低的都是各种词语。



















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











