







不问你为何流眼泪,再多的苦,我也愿意背
RDD编程
上文说到创建RDD有两种方式,
- 读取外部文件
value = sc.textFile()2.读取数据集合
value = sc.makeRDD(List(1,2,3,4)) value = sc.parallelize(List(1,2,3,4))通过上面两种方式就可以创建RDD。
RDD的转换操作
RDD的转换操作是返回新的RDD的操作,RDD转换算子是惰性的,在只有行动操作用到RDD的时候才会被计算。
先举一例子
有一个日志文件log.txt,里面包含运行的信息,筛选出来报错的信息
val inputRdd = sc.textFile("log.txt") val errorsRdd = inputRdd.filter(_.contains("error"))RDD不会改变数据,也不会存储数据,RDD只是对数据进行操作,上述的操作中,经过filter之后,就会产生一个新的RDD(errorsRdd),这个errorsRdd的结果就是包含error的信息
筛选出来警告的信息
val inputRdd = sc.textFile("log.txt") val warningsRdd = inputRdd.filter(_.contains("warn"))将警告信息和报错信息结合起来
val badLineRdd = warningsRdd.union(errorsRdd)
刚开始inputRDD经过不同的转换算子操作之后,形成了新的RDD,通过union将信息
合并起来。
上面介绍的是通过sparkContext对象来读取一个外部文件创建RDD。
下面介绍通过SparkContext对象来通过集合创建RDD。

通过读取List集合创建RDD,使用map操作对List里面的数据进行操作,将数据加倍
原来的数据 1 2 3 4
转换后的数据 2 4 6 8
通过collect动作算子和foreach动作算子将数据输出。
上面所有的RDD并不会在创建的时候就运行,在动作算子执行的时候才会对RDD进行操作。
在平常的练习中,最常用的算子就是map算子,如果希望对每个输入的元素生成多个元素,可以使用flatMap()。
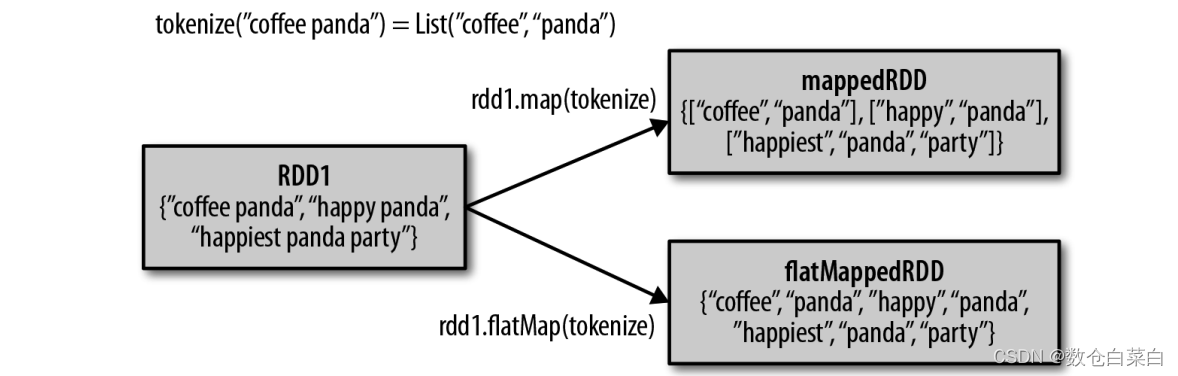
下面来看看flatmap的图解

通过一个例子来讲解flatmap。

将 List里面的单词进行WordCount。
- 将单词分成单独的一个
hadoop hive spark flink flume kudu hbase sqoop storm2.对单词进行计数
(hadoop,1) (hive,1) (spark,1)3.分组聚合
对上面的元组(hadoop,1)进行分组聚合
4.计算1的个数
下面的而这行图片来自于<Spark快速大数据分析>里面的图片

行动算子
最常用的行动算子就是collect foreach reduce
行动算子运行的时候,会开始从rdd运行,没运行一次行动算子,rdd就会从头再算一遍。为了避免这样多次计算,可以先将前面的rdd存入内存中。再次使用行动算子的时候就可以直接从内存中拿到所需的。
把数据返回驱动程序中最简单,最常见的操作是collect,它会将整个RDD的内容返回,collect()通常在单元测试中使用,collect()要求所有数据都能必须一同放入单台机器的内存中
take(n)返回RDD中的n个元素,如果需要求TopN,那么可以根据从大到小排列,然后取take
foreach()行动算子可以对每个元素进行操作。
下面介绍一下spark中的行动算子

总结:
后面将会对这些行动算子和转换算子进行一一介绍。














 2809
2809











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









