







为了完成布置的作业,需要用到spark的本地模式,根本用不到集群,就不想搭建虚拟机,hadoop集群啥的,很繁琐,最后写作业还用不到集群(感觉搭建集群对于我完成作业来说没有什么意义),所以才想办法在windows环境下,直接安装jdk、scala、spark等,使用spark的本地模式来写作业
步骤:
1. 安装jdk
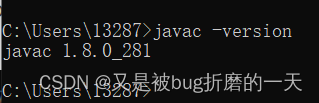
检查了,发现我自己电脑(windows)上已经安装过jdk了,环境变量也配置好了,
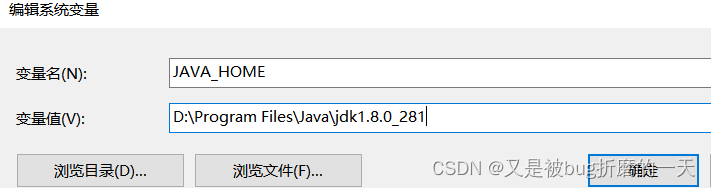
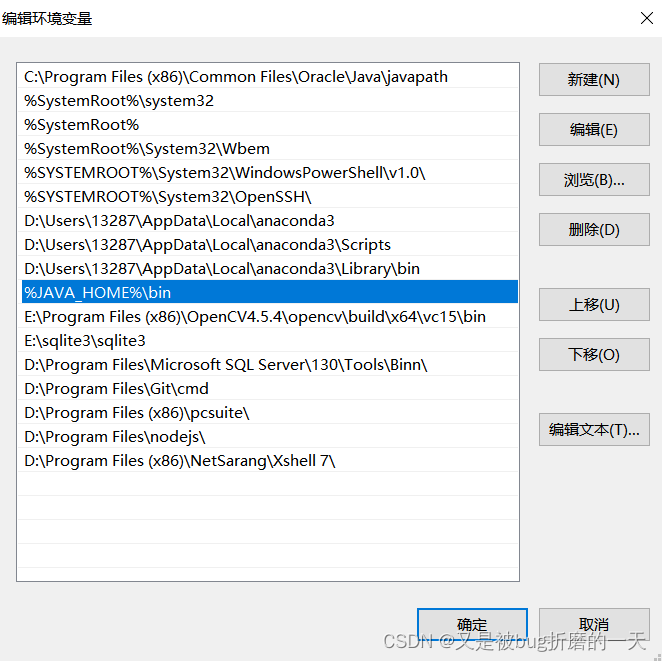
path路径中也设置好了jdk的路径
2. 下载安装scala
检查自己电脑上有没有安装scala

很好,没有安装scala,那就从官网上下载2.11.12版本,官网:
The Scala Programming Language (scala-lang.org)


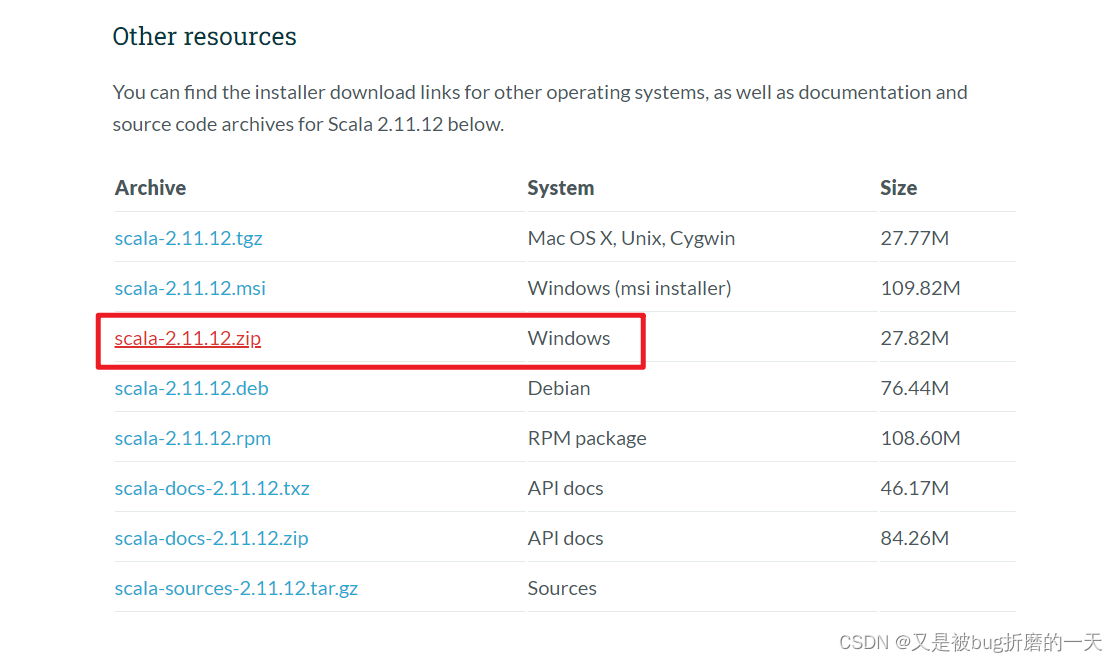
路径是在E盘下:
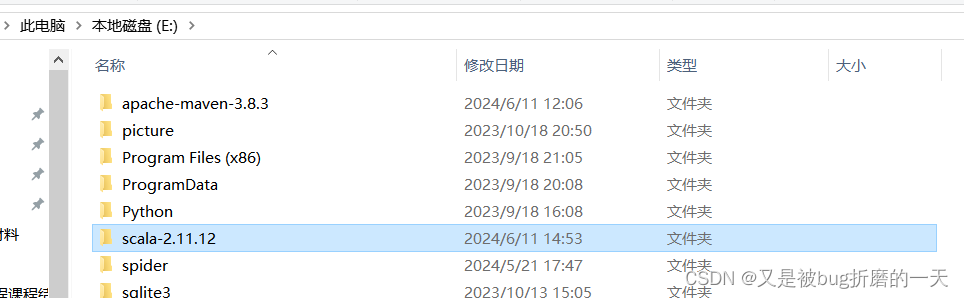
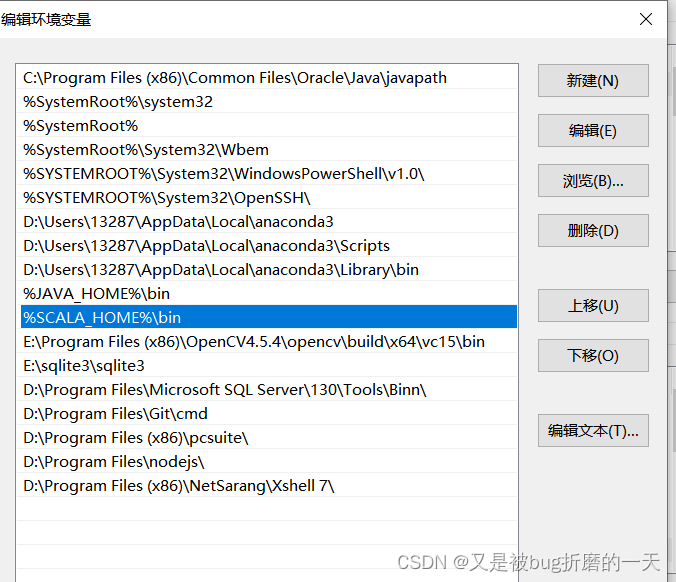
配置环境变量:

进入cmd,scala的路径下,输入scala,如下图所示,即为成功安装scala
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章




















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











