







写在前面
本节首先对前面的内容进行了回顾,然后提出两个核心问题,接着讨论了对hypothesis的分类,然后引出了成长函数和break point。
本文整理自台湾大学林轩田的《机器学习基石》
1. 回顾和预览(Recap and Preview)

对于机器学习来说,当样本
M
M
M 足够多并且
H
y
p
o
t
h
e
s
i
s
Hypothesis
Hypothesis 个数有限时,通过演算法
A
A
A 得到的
g
g
g 基本上会满足
E
o
u
t
(
g
)
≈
E
i
n
(
g
)
E_{out}(g)≈E_{in}(g)
Eout(g)≈Ein(g),此时选择一个较小的
E
i
n
(
g
)
E_{in}(g)
Ein(g), 机器学习会有一个好的结果。
∙
\bullet
∙ 回顾:对于批量处理样本具有监督式学习的二元分类问题来说(第三节),我们尽量要使
g
≈
f
g≈f
g≈f,此时存在
E
o
u
t
(
g
)
≈
0
E_{out}(g)≈0
Eout(g)≈0(第一节),同时使得
E
o
u
t
(
g
)
≈
E
i
n
(
g
)
E_{out}(g)≈E_{in}(g)
Eout(g)≈Ein(g)(第四节)和
E
i
n
(
g
)
≈
0
E_{in}(g)≈0
Ein(g)≈0(第二节) 成立。
∙
\bullet
∙ 处理两个核心问题:
▹ \triangleright ▹ 我们如何确认 E o u t ( g ) E_{out}(g) Eout(g) 和 E i n ( g ) E_{in}(g) Ein(g) 很接近?
▹ \triangleright ▹ 我们如何使得 E i n ( g ) E_{in}(g) Ein(g) 尽可能的小?
∙
\bullet
∙ 样本数量M的两种情况:
▹ \triangleright ▹ M比较小时:得到的 h y p o t h e s i s hypothesis hypothesis 比较少,所以得到效果差的 h y p o t h e s i s hypothesis hypothesis 的可能性也比较低;但是同样由于 h y p o t h e s i s hypothesis hypothesis 的选择比较少,不一定能得到效果好的 h y p o t h e s i s hypothesis hypothesis。
▹ \triangleright ▹ M比较大时:得到的 h y p o t h e s i s hypothesis hypothesis 比较多,所以得到效果差的 h y p o t h e s i s hypothesis hypothesis 的可能性也比较高;但是同样由于 h y p o t h e s i s hypothesis hypothesis 的选择比较多,有很大概率能得到效果好的 h y p o t h e s i s hypothesis hypothesis。
∙ \bullet ∙ 所以可以看出 M 的数量直接影响两个核心问题的结果 。当 M 无限大时,机器学习似乎已经不可行了,但是在 P L A PLA PLA 存在无数条直线,仍然可以进行很好的学习,后面我们对这一问题进行解释。当我们将无限大的 M M M 限制在一个有限的 m H m_{H} mH 内,问题就可以解决了。
2. 有效的直线数(PLA中)
上一节我们讨论过公式为:
P
(
∣
E
i
n
(
h
)
−
E
o
u
t
(
h
)
∣
>
ε
)
≤
2
M
e
−
2
ε
2
N
P(\left | E_{in}(h) - E_{out}(h) \right |>\varepsilon )≤2Me^{-2\varepsilon ^{2}N}
P(∣Ein(h)−Eout(h)∣>ε)≤2Me−2ε2N
当 M M M 取无限大时,等式右边一定会大于1,此时这个式子就没有了意义。但是在 P L A PLA PLA 中当两条直线很接近时,它们划分的部分其实会有很多的重叠,如果按照上面公式直接相加的话,实际上上界会偏大很多。
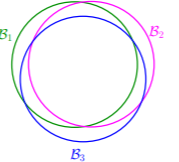
所以我们就想着将直线进行分类,将差别不大的直线划分为同一类,然后将重复的部分给去掉的话,实际上上界会得到一个有限的值,从而使机器学习变的可能。
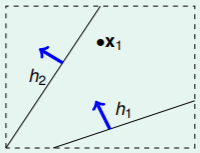
那么具体怎么进行分类呢?我们先从只有第一个点(样本)开始看起:
∙
\bullet
∙ 一个点:可以分为两类,它为负类或者正类。
∙
\bullet
∙ 两个点:最多可以分为四类,分别为正正、负负、正负、负正。

∙
\bullet
∙ 三个点:最多可以分为8类,如下图所示:

但是它不一定会生成8中结果,如果点排列成一条直线的话,最多只能分为6类:

∙
\bullet
∙ 四个点:最多可以分成14中情况(当四个点排列围绕成圈时),其他情况下分类会更少。但是类数一定不超过 2N。

∙
\bullet
∙ 结论:当有n个点时,M最多为2N,实际情况下有效的类数用
e
f
f
e
c
t
i
v
e
(
N
)
effective(N)
effective(N) 来表示,当该数远小于 2N时,即使
M
M
M 趋向无穷大我们也可以认为
P
L
A
PLA
PLA 是可行的。(2D perceptrons)
3. 有效的假设数
∙
\bullet
∙ dichotomy(二分类):输出一个结果向量表示一个
d
i
c
h
o
t
o
m
y
dichotomy
dichotomy,一条直线对应一个
d
i
c
h
o
t
o
m
y
dichotomy
dichotomy,但是一个
d
i
c
h
o
t
o
m
y
dichotomy
dichotomy 至少对应一条直线,我们把所有
d
i
c
h
o
t
o
m
y
dichotomy
dichotomy 相同的直线视为一类,它的上界就为
2
N
2^{N}
2N。
∙ \bullet ∙ 我们以四个点为例,对 H y p o t h e s i s Hypothesis Hypothesis 和 d i c h o t o m y dichotomy dichotomy 进行区分。
| \ | Hypotheses H | dichotomies H(x1,x2,…xN) |
|---|---|---|
| 例子 | 二维平面内的所有直线 | {ooxx,ooox,oooo,…} |
| 数量 | 无数条 | 上限为2N |
∙
\bullet
∙ 成长函数(growth function):
N
N
N 个点组成的而不同集合中最多有多少种
d
i
c
h
o
t
o
m
y
dichotomy
dichotomy,这个值用
m
H
m_{H}
mH 来表示,它的上界为:
m
H
(
N
)
=
m
a
x
x
1
,
x
2
,
.
.
.
x
N
∈
X
∣
H
(
x
1
,
x
2
,
.
.
.
x
N
)
∣
m_{H}(N) = \underset{x_{1},x_{2},...x_{N}∈X}{max} \left | H(x_{1},x_{2},...x_{N}) \right |
mH(N)=x1,x2,...xN∈Xmax∣H(x1,x2,...xN)∣
▹ \triangleright ▹ P o s i t i v e R a y s : m H ( N ) = N + 1 {\color {Violet}Positive \ Rays:m_{H}(N)=N+1} Positive Rays:mH(N)=N+1
这种情况对应在一维直线坐标系中的点,从一个位置开始进行划分,左边的全为负类,右边的全为正类。

当有
N
N
N 个点时,一共有
N
+
1
N+1
N+1 个不同的划分位置,所以最终
d
i
c
h
o
t
o
m
y
dichotomy
dichotomy 共有
N
+
1
N+1
N+1 种。当
N
N
N 很大的时候,
(
N
+
1
)
≪
2
N
(N+1) \ll 2^{N}
(N+1)≪2N。
▹ \triangleright ▹ P o s i t i v e I n t e r v a l s : m H ( N ) = 1 2 N 2 + 1 2 N + 1 {\color{Violet}Positive Intervals:m_{H}(N)=\frac{1}{2}N^{2}+\frac{1}{2}N+1} PositiveIntervals:mH(N)=21N2+21N+1
这种情况同样对应于一维直线坐标系中的点,选中一个范围,使得范围内的点为正类,其他部分的点为负类。

一共N个点将直线划分为N+1段,首先我们从这N+1个部分随机挑选两个点(不在同一段中)出来,此时一共有 C n 2 C_{n}^{2} Cn2 种情况,在加一种两个点在同一边的情况,一共为 1 2 N 2 + 1 2 N + 1 \frac{1}{2}N^{2}+\frac{1}{2}N+1 21N2+21N+1 种情况。当N很大的时候, 1 2 N 2 + 1 2 N + 1 ≪ 2 N \frac{1}{2}N^{2}+\frac{1}{2}N+1\ll 2^{N} 21N2+21N+1≪2N。
▹ \triangleright ▹ C o n v e x S e t s : m H ( N ) = 2 N {\color{Violet}Convex Sets:m_{H}(N)=2^{N}} ConvexSets:mH(N)=2N
在二维平面内进行点的选取,我们先让 N N N 个点围成一个圆圈,然后随便选取一些点设置为正类,将这些点连接起来就组成了一个凸多边形,这个范围内的部分为正类,其他部分为负类。

每个点都有两种选择,正类或者负类,所以一共有
2
N
2^{N}
2N 种情况。
4. Break Point
∙ \bullet ∙ B r e a k P o i n t Break \ Point Break Point 指的是从 k k k 开始,就开始满足 m H ( k ) < 2 k m_{H}(k)<2^{k} mH(k)<2k 这个式子。这个 k k k 我们就叫做 b r e a k p o i n t break \ point break point。
那么对与我们前面提到过的各种 m H m_{H} mH 来说,它们的 b r e a k p o i n t break point breakpoint 是不同的。对于 p o s i t i v e r a y s positive \ rays positive rays来说,当 k = 2 k=2 k=2 时就开始满足;对于 p o s i t i v e i n t e r v a l s positive \ intervals positive intervals 来说,当 k = 3 k=3 k=3 时就开始满足;对于 c o n v e x s e t s convex \ sets convex sets 来说,一直不满足,也就是不存在 b r e a k p o i n t break \ point break point;对于 2 D p e r c e p t r o n s 2D \ perceptrons 2D perceptrons来说,根据本节第二部分的内容,我们可以知道它的 b r e a k p o i n t break \ point break point 为4。我们似乎可以发现可以通过 m H ( N ) = O ( N k − 1 ) m_{H}(N)=O(N^{k-1}) mH(N)=O(Nk−1) 来对k进行求解,按照这么说的话 2 D p e r c e p t r o n s 2D \ perceptrons 2D perceptrons 的 m H m_{H} mH 结构应该也为多项式,这个放在后面进行证明。
















 160
160











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











