






项目描述
二元分类是机器学习中最基础的问题之一,在这份教学中,你将学会如何实作一个线性二元分类器,来根据人们的个人资料,判断其年收入是否高于 50,000 美元。我们将以两种方法: logistic regression 与 generative model,来达成以上目的,你可以尝试了解、分析两者的设计理念及差别。
实现二分类任务:
- 个人收入是否超过50000元?
数据集介绍
这个资料集是由UCI Machine Learning Repository 的Census-Income (KDD) Data Set 经过一些处理而得来。为了方便训练,我们移除了一些不必要的资讯,并且稍微平衡了正负两种标记的比例。事实上在训练过程中,只有 X_train、Y_train 和 X_test 这三个经过处理的档案会被使用到,train.csv 和 test.csv 这两个原始资料档则可以提供你一些额外的资讯。
- 已经去除不必要的属性。
- 已经平衡正标和负标数据之间的比例。
特征格式
- train.csv,test_no_label.csv。
- 基于文本的原始数据
- 去掉不必要的属性,平衡正负比例。
- X_train, Y_train, X_test(测试)
- train.csv中的离散特征=>在X_train中onehot编码(学历、状态…)
- train.csv中的连续特征 => 在X_train中保持不变(年龄、资本损失…)。
- X_train, X_test : 每一行包含一个510-dim的特征,代表一个样本。
- Y_train: label = 0 表示 “<=50K” 、 label = 1 表示 " >50K " 。
* 有用的信息:
* data dim =510
* 数据编码好了
* label输出为bool值
#导入库
import numpy as np
import pandas as pd
'''
读取数据,并进行处理,直接读取已经帮我们处理好了的文件。
如果有看数据集,就会发现nolabel总共有511列,而数据描述说data dim为510,
即'id'为不需要信息,需要剔除
'''
x_train_data = pd.read_csv('data/data75837/X_train')
y_train_data = pd.read_csv('data/data75837/Y_train')
x_test_data = pd.read_csv('data/data75837/X_test')
#从数据集的描述也可以知道数据维度是510,即id这列数据并不需要,所以下面对id这一列删除
x_train_data = x_train_data.drop(['id'],1)
x_test_data = x_test_data.drop(['id'],1)
y_train_data = y_train_data.drop(['id'],1)
#转成numpy
x_train_data = x_train_data.to_numpy()
x_test_data = x_test_data.to_numpy()
y_train_data = y_train_data.to_numpy()
#下面这步是将y_train_data1拉平,可分别对其进行输出观察差别。
y_train_data1 = y_train_data.reshape(54256,)
#print(y_train_data)
#print(y_train_data1)
#归一化
eps = 1e-8 #在作业1中也有,这是为了防止除数为零的情况,但我发现这次作业在log中为0时也需要加
x_mean = np.mean(x_train_data,0).reshape(1,-1)#求均值
x_std = np.std(x_train_data,0).reshape(1,-1)#求方差
x_train_data = (x_train_data - x_mean)/(x_std+eps)#归一化
#对预测集同样处理
x_test_mean = np.mean(x_test_data,0).reshape(1,-1)
x_test_std = np.std(x_test_data,0).reshape(1,-1)
x_test_data = (x_test_data - x_test_mean)/(x_test_std+eps)
#划分数据集,0.8的含义为将总的训练80%化为训练集,20%为验证集。
train_counts = int(len(x_train_data)*0.8)
train_x = x_train_data[:train_counts]
val_x = x_train_data[train_counts:]
train_y = y_train_data1[:train_counts]
val_y = y_train_data1[train_counts:]
print('train size is '+ str(train_x.shape[0]))
print('val size is ' + str(val_x.shape[0]))
print('data dim is '+ str(train_x.shape[1]))
print('训练集比例为:'+str(train_x.shape[0]/(train_x.shape[0]+val_x.shape[0])))
train size is 43404
val size is 10852
data dim is 510
训练集比例为:0.799985255086995
#打乱数据
#需要注意,X是训练集,而Y是训练集的标签,如果各自打乱将会导致各自行的序号对应不上,所以需要同一打乱顺序
def data_shuffle(X, Y):
randomindex = np.arange(len(X))
np.random.shuffle(randomindex)
return (X[randomindex], Y[randomindex])
公式需要:三个
-
sigmoid: 逻辑回归的目标函数,在这里我们通过这个函数获得预测值的概率返回(0-1);
-
gradient:求解梯度,用来更新参数。
-
cross_entropy_loss:这个函数用来计算训练出来的预测值y_pred 和验证集 y的误差;
下面是这三个函数的代码实现。
-
sigmoi函数的公式为
σ \sigma σ (z) = 1 1 + e − z \frac{1}{1+e^{-z}} 1+e−z1
如果用这个定义,会出现溢出警告,原因是z有可能为绝对值很大的负数,这会导致e指数的值很大。
def sigmoid(z):
return np.clip(1 / (1.0 + np.exp(-z)),1e-8,(1-(1e-8)))
优化sigmoid函数,如下:
def sigmoid(x):
x_ravel = x.ravel() # 将numpy数组展平
length = len(x_ravel)
y = []
for index in range(length):
if x_ravel[index] >= 0:
y.append(1.0 / (1 + np.exp(-x_ravel[index])))
else:
y.append(np.exp(x_ravel[index]) / (np.exp(x_ravel[index]) + 1))
return np.array(y).reshape(x.shape)
关于公式可对照课节5:分类 文档第十一页。
w的更新公式如下:
w i w_i wi ← \leftarrow ← w i w_i wi - η \eta η ∑ n \displaystyle\sum_{n} n∑-( y ^ n \hat{y}^{n} y^n - f w , b f_{w,b} fw,b( x n x^n xn)) x i n x_{i}^{n} xin
b的梯度更新,文档好像没给
b i b_i bi ← \leftarrow ← b i b_i bi - η \eta η ∑ n \displaystyle\sum_{n} n∑-( y ^ n \hat{y}^{n} y^n - f w , b f_{w,b} fw,b( x n x^n xn))
我们在这里只定义梯度,即这一部分
-
∑ n \displaystyle\sum_{n} n∑-( y ^ n \hat{y}^{n} y^n - f w , b f_{w,b} fw,b( x n x^n xn)) x i n x_{i}^{n} xin
-
∑ n \displaystyle\sum_{n} n∑-( y ^ n \hat{y}^{n} y^n - f w , b f_{w,b} fw,b( x n x^n xn))
参数完整地更新在迭代里实现
#损失函数分别对w,b求导,得到w,b的梯度
def gradient(X, Y_label, w, b):
y_pred = sigmoid(np.matmul(X, w) + b)
pred_error = Y_label - y_pred
w_grad = -np.sum(pred_error * X.T, 1)
b_grad = -np.sum(pred_error)
return w_grad, b_grad
交叉熵损失函数,课节5:分类,文档第七页。公式如下:
L(w,b) = ∑ n \displaystyle\sum_{n} n∑-[ y ^ n \hat{y}^{n} y^nln f w , b f_{w,b} fw,b( x n x^n xn)+(1- y ^ n \hat{y}^{n} y^n)ln(1- f w , b f_{w,b} fw,b( x n x^n xn))]
代码实现,一一对照。
#损失函数为交叉熵,直接套公式
def cross_entropy_loss(y_pred, Y_label):
cross_entropy = -np.dot(Y_label, np.log(y_pred+eps)) - np.dot((1 - Y_label), np.log(1 - y_pred+eps))
return cross_entropy
#三个主要公式定义完后还需要计算准确率
# y_pred为训练得出的预测值,y_label为答案。
def accuracy(y_pred, y_label):
acc = 1 - np.mean(np.abs(y_pred - y_label))
return acc
将定义的函数实现逻辑回归的迭代步骤如图: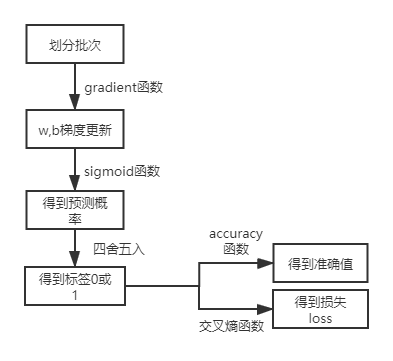
'''
迭代实现
'''
#w,b设置初始值0
data_dim = 510
w = np.zeros((data_dim,))
b = np.zeros((1,))
iters = 10 #相当于epoch
batch_size = 8 #批次
learning_rate = 0.2 #学习率
train_loss = [] #存放每次的训练误差
val_loss = [] #存放每次的验证误差
train_acc = []#存放每次的训练准确率
val_acc = []#存放每次的验证准确率
step = 1 #为了更新学习率用的
train_size = train_x.shape[0]
val_size = val_x.shape[0]
for epoch in range(iters):
train_x, train_y = data_shuffle(train_x, train_y)
for idx in range(int(np.floor(train_size / batch_size))):
X = train_x[idx*batch_size:(idx+1)*batch_size]
Y = train_y[idx*batch_size:(idx+1)*batch_size]
#求w,b梯度
w_grad, b_grad = gradient(X, Y, w, b)
#根据前面所说的公式更新参数,除以step的平方是学习率的更新,可以对照课节四:梯度下降文档第六页。
#即采用Adaptive learing rates
w = w - learning_rate/np.sqrt(step) * w_grad
b = b - learning_rate/np.sqrt(step) * b_grad
#这里是加入正则化的更新,0.02为正则项系数,可自行调,效果会好一丢丢。
#w = w - learning_rate / np.sqrt(step) * (w_grad + 0.02 * w)
#b = b - learning_rate / np.sqrt(step) * b_grad
step = step + 1
y_train_pred = sigmoid(np.matmul(train_x, w) + b)
#y_train_pred 返回的是将这轮次的w,b代入方程 (W^T)X+b后的输出值经过sigmoid变成的概率(0-1)
Y_train_pred = np.round(y_train_pred)#将返回值四舍五入即为标签,0 or 1
train_acc.append(accuracy(Y_train_pred, train_y))#计算准确率
train_loss.append(cross_entropy_loss(y_train_pred, train_y) / train_size) #计算loss
y_val_pred = sigmoid(np.matmul(val_x, w) + b)
Y_val_pred = np.round(y_val_pred)
val_acc.append(accuracy(Y_val_pred, val_y))
val_loss.append(cross_entropy_loss(y_val_pred, val_y) / val_size)
print('Epoch {}/{}, training loss: {}'.format(epoch+1,iters,train_loss[-1]))
print('Epoch {}/{}, training acc: {}'.format(epoch+1,iters,train_acc[-1]))
print('--------------eval result--------------')
print('After {} epoch, val loss: {}'.format(iters,val_loss[-1]))
print('After {} epoch, val acc: {}'.format(iters,val_acc[-1]))
#训练完将得到的参数保存下来
np.save('weight_1.npy', w)
Epoch 1/10, training loss: 0.3106906196360508
Epoch 1/10, training acc: 0.8757027002119621
Epoch 2/10, training loss: 0.28692780445840804
Epoch 2/10, training acc: 0.879596350566768
Epoch 3/10, training loss: 0.28094551638757315
Epoch 3/10, training acc: 0.8811169477467514
Epoch 4/10, training loss: 0.27671736734631047
Epoch 4/10, training acc: 0.882614505575523
Epoch 5/10, training loss: 0.27545578533310594
Epoch 5/10, training acc: 0.8823380333609806
Epoch 6/10, training loss: 0.2732135706233216
Epoch 6/10, training acc: 0.8846189291309556
Epoch 7/10, training loss: 0.27111051630200195
Epoch 7/10, training acc: 0.8833748041655147
Epoch 8/10, training loss: 0.2717668035956711
Epoch 8/10, training acc: 0.8829831351949129
Epoch 9/10, training loss: 0.2708009078736617
Epoch 9/10, training acc: 0.8839277485945995
Epoch 10/10, training loss: 0.2685795683122868
Epoch 10/10, training acc: 0.8840659847018708
--------------eval result--------------
After 10 epoch, val loss: 0.2943104604044454
After 10 epoch, val acc: 0.8745853298931072
看看loss和acc 的曲线长啥样
import matplotlib.pyplot as plt
%matplotlib inline
#画loss 的图
plt.plot(train_loss)
plt.plot(val_loss)
plt.title('Loss')
plt.legend(['train', 'val'])
plt.show()
#画准确率的图
plt.plot(train_acc)
plt.plot(val_acc)
plt.title('acc')
plt.legend(['train', 'val'])
plt.show()


拿我们训练好得到模型来预测test集。
w = np.load('weight_1.npy') # 加载参数
file_path='work/output_{}.csv'#想要生成的预测结果csv文件存放路径
#预测结果
predictions=np.round(sigmoid(np.matmul(x_test_data, w) + b)).astype(np.int)
with open(file_path.format('logistic_new'), 'w') as f:
f.write('id,label\n')
for i, label in enumerate(predictions):
f.write('{},{}\n'.format(i, label))
#如果是在作业里,本身数据集中有一个output_logistic.csv,我们这里生成的是output_logistic_new.csv
这是最近在飞桨平台参加李宏毅老师课程的一次作业学习。
课程链接: https://aistudio.baidu.com/aistudio/course/introduce/1978?directly=1&shared=1
欢迎来一起学习,一起探讨作业。
关于数据集部分可以fork一下公开的作业项目:
手把手教你从公式到代码实现:逻辑回归vs.概率生成模型















 259
259











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









