






一、LZW编解码原理
编码:LZW的编码思想是不断地从字符流中提取新的字符串,通俗地理解为新“词条”,然后用“代号”也就是码字表示这个“词条”。这样一来,对字符流的编码就变成了用码字去替换字符流,生成码字流,从而达到压缩数据的目的。LZW编码是围绕称为词典的转换表来完成的。LZW编码器通过管理这个词典完成输入与输出之间的转换。LZW编码器的输入是字符流,字符流可以是用8位ASCII字符组成的字符串,而输出是用n位(例如12位)表示的码字流。
解码:解码器首先将数组的前n个位置初始化为单个字符(如n=256),然后从输入流中读入一个码字,用每个指针来定位字典中的一个字符,第一步:读入第一个指针,用它检索字典的第I项,并把找到的字符I写入解码器输出流中。需要将Ix存入字典,但字符x此时仍未知,它将是下一个从字典中取出的串的首字符, 此后的每一步中,解码器输入下一个指针,用它从字典中取出下一个字符串J并记录到解码器输出流中。假设指针为8,则解码器检查dict[8].index字段,如果它也是8,那么节点就是所要找的,否则解码器检查相继的数组位置,直到找到正确的节点,一旦找到了所要的树节点,就利用parent字段返回到树的上层,并按相反顺序取出字符串中的单个字符,再将江这些字符按正常顺序置于J中。解码器把第一个字符x从字符串J中分离出来,并将字符串Ix存入下一个可用的数组单元中(字符串I是前面找到的,所以只需添加一个带有字符x的节点),然后解码器将J送入I,继续下一步解码。
二、编程实现的算法
1、编码
LZW编码算法的步骤如下:

步骤1:将词典初始化为包含所有可能的单字符,当前前缀P初始化为空。
步骤2:当前字符C=字符流中的下一个字符。
步骤3:判断P+C是否在词典中
(1)如果“是”,则用C扩展P,即让P=P+C,返回到步骤2。
(2)如果“否”,则
输出与当前前缀P相对应的码字W;
将P+C添加到词典中;
令P=C,并返回到步骤2
LZW编码算法可用下述函数实现。首先初始化词典,然后顺序从待压缩文件中读入字符并按照上述算法执行编码。最后将编得的码字流输出至文件中。

2、解码
LZW解码算法开始时,译码词典和编码词典相同,包含所有可能的前缀根。具体解码算法如下:
步骤1:在开始译码时词典包含所有可能的前缀根。
步骤2:令CW:=码字流中的第一个码字。
步骤3:输出当前缀-符串string.CW到码字流。
步骤4:先前码字PW:=当前码字CW。
步骤5:当前码字CW:=码字流的下一个码字。
步骤6:判断当前缀-符串string.CW 是否在词典中。
(1)如果”是”,则把当前缀-符串string.CW输出到字符流。
当前前缀P:=先前缀-符串string.PW。
当前字符C:=当前前缀-符串string.CW的第一个字符。
把缀-符串P+C添加到词典。
(2)如果”否”,则当前前缀P:=先前缀-符串string.PW。
当前字符C:=当前缀-符串string.CW的第一个字符。
输出缀-符串P+C到字符流,然后把它添加到词典中。
步骤7:判断码字流中是否还有码字要译。
(1)如果”是”,就返回步骤4。
(2)如果”否”,结束。
LZW解码算法可用下述函数实现。首先初始化词典,然后顺序从压缩文件中读入码字并按照上述算法执行解码。最后将解得的字符串输出至文件中。

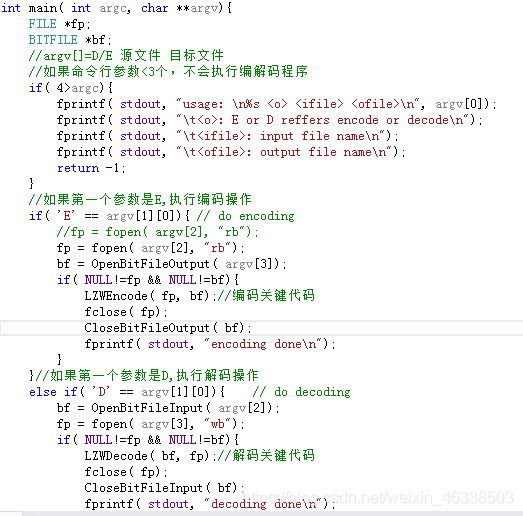
3、main函数
4、其他函数
void InitDictionary( void)
初始化字典
void PrintDictionary( void)
打印词典
int InDictionary( int character, int string_code)
判断P+C是否在词典中
void AddToDictionary( int character, int string_code)
如果不在将P+C放入词典
三、实验结果
1、以一个文本文件作为输入,得到输出的LZW编码文件

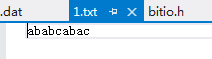
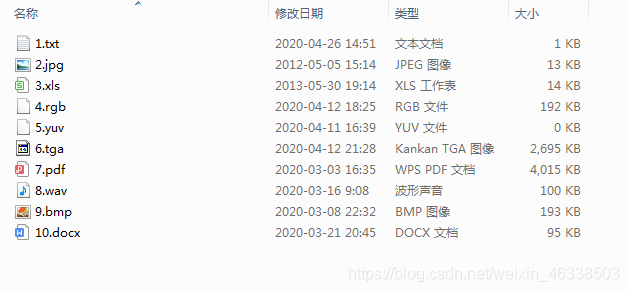
2、选择至少十种不同格式类型的文件,使用LZW编码器进行压缩得到输出的压缩比特流文件。对各种不同格式的文件进行压缩效率的分析
编码前:
编码后:
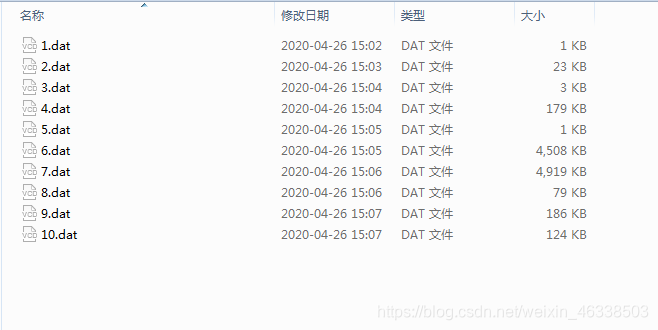
| 文件类型 | 压缩比 |
|---|---|
| txt | 1 |
| jpg | 0.57 |
| xls | 4.67 |
| rgb | 1.07 |
| yuv | 0 |
| tga | 0.60 |
| 0.82 | |
| wav | 1.26 |
| bmp | 1.04 |
| docx | 0.77 |
四、代码实现
bitio.h
#include <stdio.h>
typedef struct{
FILE *fp;
unsigned char mask;
int rack;
}BITFILE;
BITFILE *OpenBitFileInput( char *filename);
BITFILE *OpenBitFileOutput( char *filename);
void CloseBitFileInput( BITFILE *bf);
void CloseBitFileOutput( BITFILE *bf);
int BitInput( BITFILE *bf);
unsigned long BitsInput( BITFILE *bf, int count);
void BitOutput( BITFILE *bf, int bit);
void BitsOutput( BITFILE *bf, unsigned long code, int count);
#endif // __BITIO__
bitio.cpp
/*
* Definitions for bitwise IO
*
* vim: ts=4 sw=4 cindent
*/
#include "stdafx.h"
using namespace std;
#include <stdlib.h>
#include <stdio.h>
#include "bitio.h"
BITFILE *OpenBitFileInput( char *filename){
BITFILE *bf;
bf = (BITFILE *)malloc( sizeof(BITFILE));
if( NULL == bf) return NULL;
if( NULL == filename) bf->fp = stdin;
else bf->fp = fopen( filename, "rb");
if( NULL == bf->fp) return NULL;
bf->mask = 0x80;
bf->rack = 0;
return bf;
}
BITFILE *OpenBitFileOutput( char *filename){
BITFILE *bf;
bf = (BITFILE *)malloc( sizeof(BITFILE));
if( NULL == bf) return NULL;
if( NULL == filename) bf->fp = stdout;
else bf->fp = fopen( filename, "wb");
if( NULL == bf->fp) return NULL;
bf->mask = 0x80;
bf->rack = 0;
return bf;
}
void CloseBitFileInput( BITFILE *bf){
fclose( bf->fp);
free( bf);
}
void CloseBitFileOutput( BITFILE *bf){
// Output the remaining bits
if( 0x80 != bf->mask) fputc( bf->rack, bf->fp);
fclose( bf->fp);
free( bf);
}
int BitInput( BITFILE *bf){
int value;
if( 0x80 == bf->mask){
bf->rack = fgetc( bf->fp);
if( EOF == bf->rack){
fprintf(stderr, "Read after the end of file reached\n");
exit( -1);
}
}
value = bf->mask & bf->rack;
bf->mask >>= 1;
if( 0==bf->mask) bf->mask = 0x80;
return( (0==value)?0:1);
}
unsigned long BitsInput( BITFILE *bf, int count){
unsigned long mask;
unsigned long value;
mask = 1L << (count-1);
value = 0L;
while( 0!=mask){
if( 1 == BitInput( bf))
value |= mask;
mask >>= 1;
}
return value;
}
void BitOutput( BITFILE *bf, int bit){
if( 0 != bit) bf->rack |= bf->mask;
bf->mask >>= 1;
if( 0 == bf->mask){ // eight bits in rack
fputc( bf->rack, bf->fp);
bf->rack = 0;
bf->mask = 0x80;
}
}
void BitsOutput( BITFILE *bf, unsigned long code, int count){
unsigned long mask;
mask = 1L << (count-1);
while( 0 != mask){
BitOutput( bf, (int)(0==(code&mask)?0:1));
mask >>= 1;
}
}
#if 0
int main( int argc, char **argv){
BITFILE *bfi, *bfo;
int bit;
int count = 0;
if( 1<argc){
if( NULL==OpenBitFileInput( bfi, argv[1])){
fprintf( stderr, "fail open the file\n");
return -1;
}
}else{
if( NULL==OpenBitFileInput( bfi, NULL)){
fprintf( stderr, "fail open stdin\n");
return -2;
}
}
if( 2<argc){
if( NULL==OpenBitFileOutput( bfo, argv[2])){
fprintf( stderr, "fail open file for output\n");
return -3;
}
}else{
if( NULL==OpenBitFileOutput( bfo, NULL)){
fprintf( stderr, "fail open stdout\n");
return -4;
}
}
while( 1){
bit = BitInput( bfi);
fprintf( stderr, "%d", bit);
count ++;
if( 0==(count&7))fprintf( stderr, " ");
BitOutput( bfo, bit);
}
return 0;
}
#endif
lzw_E.cpp
// Lzw_E.cpp : 定义控制台应用程序的入口点。
//
#include "stdafx.h"
using namespace std;
/*
* Definition for LZW coding
*
* vim: ts=4 sw=4 cindent nowrap
*/
#include <stdlib.h>
#include <stdio.h>
#include "bitio.h"
#define MAX_CODE 65535
struct {
int suffix;
int parent, firstchild, nextsibling;
} dictionary[MAX_CODE+1];
int next_code;
int d_stack[MAX_CODE]; // stack for decoding a phrase
#define input(f) ((int)BitsInput( f, 16))
#define output(f, x) BitsOutput( f, (unsigned long)(x), 16)
int DecodeString( int start, int code);
void InitDictionary( void);
void PrintDictionary( void){
int n;
int count;
for( n=256; n<next_code; n++){
count = DecodeString( 0, n);
printf( "%4d->", n);
while( 0<count--) printf("%c", (char)(d_stack[count]));
printf( "\n");
}
}
int DecodeString( int start, int code){
int count;
count = start;
while( 0<=code){
d_stack[ count] = dictionary[code].suffix;
code = dictionary[code].parent;
count ++;
}
return count;
}
void InitDictionary( void){
int i;
for( i=0; i<256; i++){
dictionary[i].suffix = i;
dictionary[i].parent = -1;
dictionary[i].firstchild = -1;
dictionary[i].nextsibling = i+1;
}
dictionary[255].nextsibling = -1;
next_code = 256;
}
/*
* Input: string represented by string_code in dictionary,
* Output: the index of character+string in the dictionary
* index = -1 if not found
*/
int InDictionary( int character, int string_code){
int sibling;
if( 0>string_code) return character;
sibling = dictionary[string_code].firstchild;
while( -1<sibling){
if( character == dictionary[sibling].suffix) return sibling;
sibling = dictionary[sibling].nextsibling;
}
return -1;
}
void AddToDictionary( int character, int string_code){
int firstsibling, nextsibling;
if( 0>string_code) return;
dictionary[next_code].suffix = character;
dictionary[next_code].parent = string_code;
dictionary[next_code].nextsibling = -1;
dictionary[next_code].firstchild = -1;
firstsibling = dictionary[string_code].firstchild;
if( -1<firstsibling){ // the parent has child
nextsibling = firstsibling;
while( -1<dictionary[nextsibling].nextsibling )
nextsibling = dictionary[nextsibling].nextsibling;
dictionary[nextsibling].nextsibling = next_code;
}else{// no child before, modify it to be the first
dictionary[string_code].firstchild = next_code;
}
next_code ++;
}
//编码
void LZWEncode( FILE *fp, BITFILE *bf){
int character;
int string_code;
int index;
unsigned long file_length;
fseek( fp, 0, SEEK_END);
file_length = ftell( fp);
fseek( fp, 0, SEEK_SET);
BitsOutput( bf, file_length, 4*8);
InitDictionary();//初始化词典
string_code = -1;//当前前缀string_code初始化为空
while( EOF!=(character=fgetc( fp))){
index = InDictionary( character, string_code);//当前字符character=字符流中的下一个字符,P+C
//判断P+C是否在词典中,如果“是”,则用C扩展P,即让P=P+C
if( 0<=index){ // string+character in dictionary
string_code = index;
}
else{ // string+character not in dictionary
output( bf, string_code);//如果“否”,则输出与当前前缀P相对应的码字W;
if( MAX_CODE > next_code){ // free space in dictionary
// add string+character to dictionary
AddToDictionary( character, string_code);//将P+C添加到词典中;
}
string_code = character;//令P=C,并返回到步骤2
}
}
output( bf, string_code);
}
//解码
void LZWDecode( BITFILE *bf, FILE *fp){
int character;
int new_code, last_code;
int phrase_length;
unsigned long file_length;
file_length = BitsInput( bf, 4*8);
if( -1 == file_length) file_length = 0;
InitDictionary();//初始化词典,在开始译码时词典包含所有可能的前缀根
last_code = -1;
while( 0<file_length){//判断当前缀-符串string.CW 是否在词典中
new_code = input( bf);//当前码字CW:=码字流的下一个码字
if( new_code >= next_code){ // this is the case CSCSC( not in dict)
d_stack[0] = character;//当前缀-符串不在词典中,当前字符C:=当前缀-符串string.CW的第一个字符
phrase_length = DecodeString( 1, last_code);//输出缀-符串P+C到字符流,然后把它添加到词典中
}else{
phrase_length = DecodeString( 0, new_code);//当前缀-符串在词典中,把当前缀-符串string.CW输出到字符流
}
character = d_stack[phrase_length-1];
while( 0<phrase_length){
phrase_length --;
fputc( d_stack[ phrase_length], fp);
file_length--;
}
if( MAX_CODE>next_code){ // add the new phrase to dictionary
AddToDictionary( character, last_code);
}
last_code = new_code;
}
}
int main( int argc, char **argv){
FILE *fp;
BITFILE *bf;
//argv[]=D/E 源文件 目标文件
//如果命令行参数<3个,不会执行编解码程序
if( 4>argc){
fprintf( stdout, "usage: \n%s <o> <ifile> <ofile>\n", argv[0]);
fprintf( stdout, "\t<o>: E or D reffers encode or decode\n");
fprintf( stdout, "\t<ifile>: input file name\n");
fprintf( stdout, "\t<ofile>: output file name\n");
return -1;
}
//如果第一个参数是E,执行编码操作
if( 'E' == argv[1][0]){ // do encoding
//fp = fopen( argv[2], "rb");
fp = fopen( argv[2], "rb");
bf = OpenBitFileOutput( argv[3]);
if( NULL!=fp && NULL!=bf){
LZWEncode( fp, bf);//编码关键代码
fclose( fp);
CloseBitFileOutput( bf);
fprintf( stdout, "encoding done\n");
}
}//如果第一个参数是D,执行解码操作
else if( 'D' == argv[1][0]){ // do decoding
bf = OpenBitFileInput( argv[2]);
fp = fopen( argv[3], "wb");
if( NULL!=fp && NULL!=bf){
LZWDecode( bf, fp);//解码关键代码
fclose( fp);
CloseBitFileInput( bf);
fprintf( stdout, "decoding done\n");
}
}else{ // otherwise
fprintf( stderr, "not supported operation\n");
}
return 0;
}














 1230
1230











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









