






一.任务
上一篇文章.简单介绍了用异常检测的方法检测异常数据,本篇我们来讲解一个实例,先来看看本次实战的任务。
异常检测实战task:
1、基于 anomaly_data.csv数据,可视化数据分布情况、及其对应高斯分布的概率密度函数
2、建立模型,实现异常数据点预测
3、可视化异常检测处理结果
4、修改概率分布阈值EllipticEnvelope(contamination=0.1)中的contamination,查看阈值改变对结果的影响
下面直接上代码~~
二.实战
#加载数据
import pandas as pd
import numpy as np
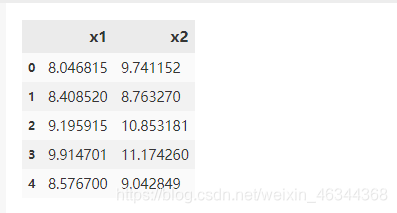
data = pd.read_csv('anomaly_data.csv')
data.head()
#数据可视化
%matplotlib inline
from matplotlib import pyplot as plt
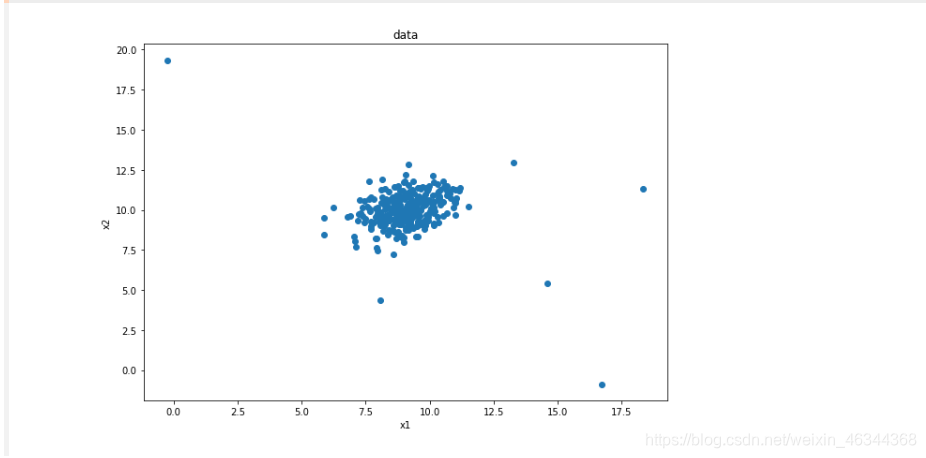
fig1 = plt.figure(figsize=(10,7))
plt.scatter(data.loc[:,'x1'],data.loc[:,'x2'])
plt.title("data")
plt.xlabel('x1')
plt.ylabel('x2')
plt.show()
#define x1 and x2
x1 = data.loc[:,'x1']
x2 = data.loc[:,'x2']
#将数据分布进行一个可视化
import matplotlib as mlp
font2 = {'family' : 'SimHei','weight' : 'normal','size' : '20' }#定义一下字体(根据自己喜好定义即可)
mlp.rcParams['font.family'] = 'SimHei' #设置字体
mlp.rcParams['axes.unicode_minus'] = False #字符显示
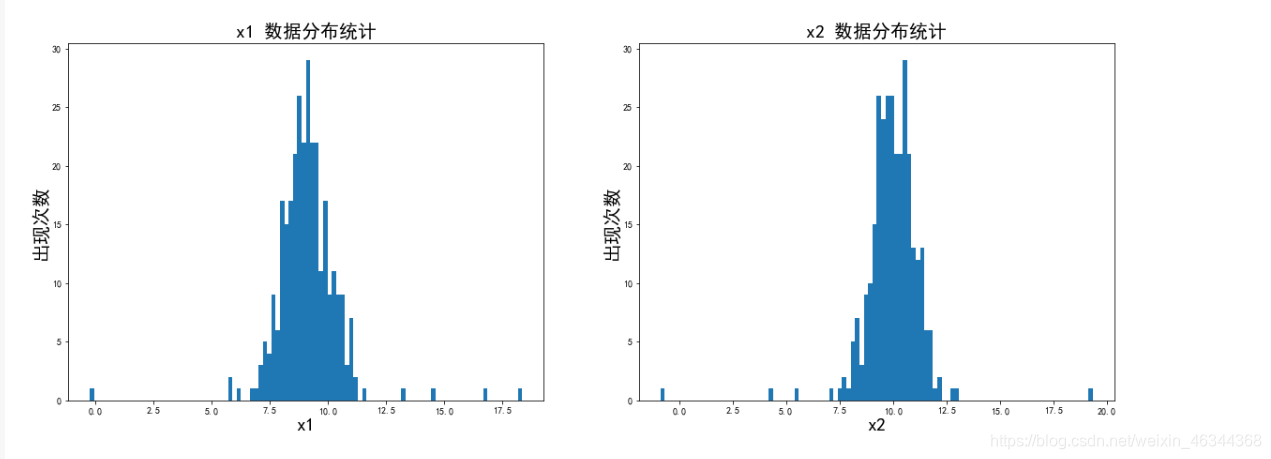
fig2 = plt.figure(figsize=(20,7))
plt.subplot(121)
plt.hist(x1,bins=100) #分成100个数据分隔,即有100条条状图
plt.title('x1 数据分布统计',font2)
plt.xlabel('x1',font2)
plt.ylabel('出现次数',font2)
plt.subplot(122)
plt.hist(x2,bins=100) #分成100个数据分隔
plt.title('x2 数据分布统计',font2)
plt.xlabel('x2',font2)
plt.ylabel('出现次数',font2)
plt.show()
#计算x1、x2的均值(mean)和标准差(sigma)
x1_mean = x1.mean()
x1_sigma = x1.std()
x2_mean = x2.mean()
x2_sigma = x2.std()
print(x1_mean,x1_sigma,x2_mean,x2_sigma)

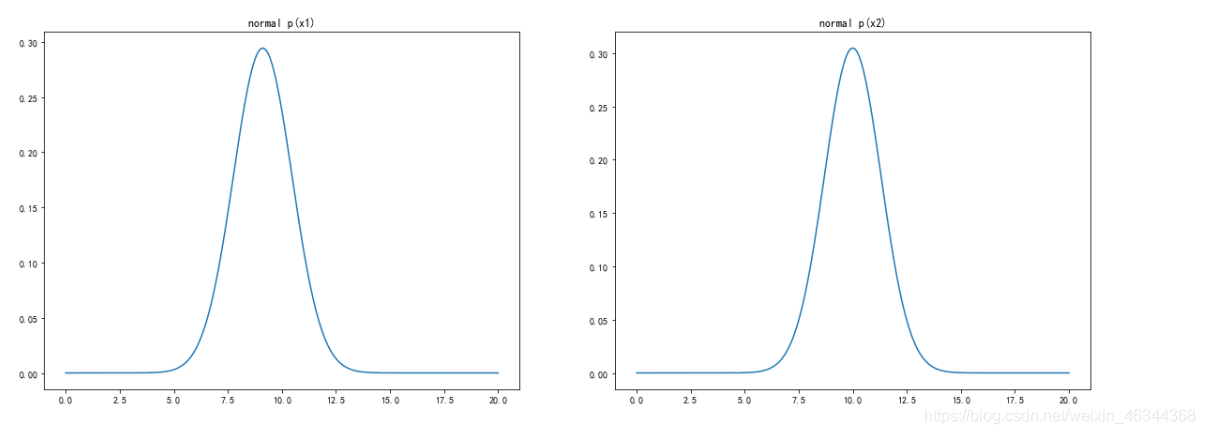
#计算高斯分布概率密度函数
from scipy.stats import norm
x1_range = np.linspace(0,20,300) #范围是0到20,300个点均分
x1_normal = norm.pdf(x1_range,x1_mean,x1_sigma) #计算高斯分布概率密度函数
x2_range = np.linspace(0,20,300)
x2_normal = norm.pdf(x2_range,x2_mean,x2_sigma)
#可视化高斯分布概率密度函数
fig3 = plt.figure(figsize=(20,7))
plt.subplot(121)
plt.plot(x1_range,x1_normal)
plt.title('normal p(x1)')
plt.subplot(122)
plt.plot(x2_range,x2_normal)
plt.title('normal p(x2)')
plt.show()
至此,我们任务的第一部分就完成了,下面开始建立模型
#建立模型
from sklearn.covariance import EllipticEnvelope
ad_model = EllipticEnvelope()
ad_model.fit(data)

注意此时 contamination=0.1(可理解为异常点占比为10%),一会儿我们修改一下它的值,看看有什么变化
#预测
y_predict = ad_model.predict(data)
print(pd.value_counts(y_predict))
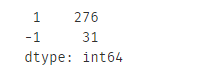
可以看到异常点占比10%左右
任务第二步也完成了,然后下一步可视化结果
#可视化结果
fig4 = plt.figure(figsize=(10,6))
orginal_data=plt.scatter(data.loc[:,'x1'],data.loc[:,'x2'],marker='x') #将各点用'x'表示
anomaly_data=plt.scatter(data.loc[:,'x1'][y_predict==-1],data.loc[:,'x2'][y_predict==-1],marker='o',facecolor='none',edgecolor='red',s=150)
#y_predict==-1即是异常点; marker='o'将异常点用圆圈圈起来; facecolor='none' 不填充,即空心圆; edgecolor='red' 颜色为红色; s=150 圆圈的大小.
plt.title('自动寻找异常数据',font2)
plt.xlabel('x1',font2)
plt.ylabel('x2',font2)
plt.legend((orginal_data,anomaly_data),('原数据','检测异常点'))
plt.show()
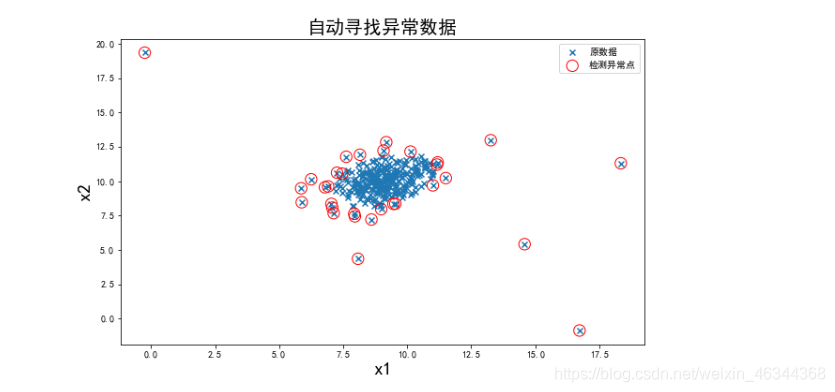
可以看到有些我们感觉是正常数据的点也被标记为异常点了,这时我们可以执行任务的最后一步,修改一下阈值EllipticEnvelope(contamination=0.1)中的contamination,查看阈值改变对结果的影响
#将contamination的值改为0.03
ad_model = EllipticEnvelope(contamination=0.03)
ad_model.fit(data)
y_predict = ad_model.predict(data)
fig5 = plt.figure(figsize=(20,7))
orginal_data=plt.scatter(data.loc[:,'x1'],data.loc[:,'x2'],marker='x')
anomaly_data=plt.scatter(data.loc[:,'x1'][y_predict==-1],data.loc[:,'x2'][y_predict==-1],marker='o',facecolor='none',edgecolor='red',s=150)
plt.title('anomaly detection result')
plt.xlabel('x1')
plt.ylabel('x2')
plt.legend((orginal_data,anomaly_data),('original_data','anomaly_data'))
plt.show()
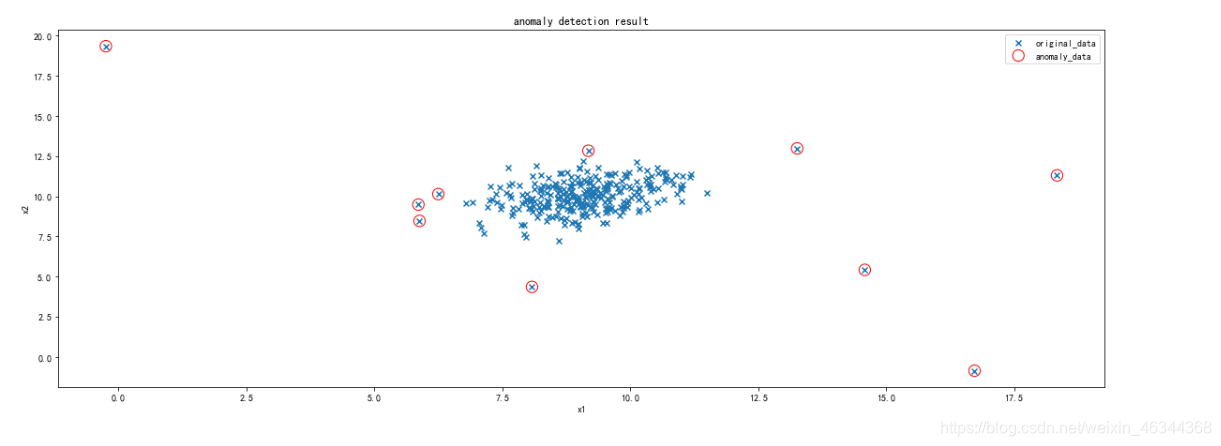
和之前对比可以看出,修改后的结果明显更好。当然,也可以试着改变其他参数的值来达到更好的效果
三.总结
异常检测实战summary:
1、通过计算数据各维度对应的高斯分布概率密度函数,可用于寻找到数据中的异常点;
2、通过修改概率密度阈值contamination,可调整异常点检测的灵敏度;
3、核心算法参考链接:https://scikit-learn.org/stable/modules/generated/sklearn.covariance.EllipticEnvelope.html?highlight=ellipticenvelope
本次分享就到这里啦! thanks~~
数据集.
提取码:fbcx















 3769
3769











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









