







由于信息收集是漏洞挖掘中的最重要的部分,信息收集做好了,相当于成功了一半,因为大部分挖掘思路都是一样的,逻辑都是差不多的,只要掌握的资产多,我们的挖掘广度就越大,成功率就越高。因此我整理了一下信息收集的思路,该思路比较的全面,建议大家收藏慢用
文章目录
建议:通过工具进行信息收集的时候,务必挂国内代理
大致收集范围
子域名,端口,目录
子域名:通过子域名可以扩大资产范围
IP:查找目标网站的真实IP,由于目标网站可能使用了CDN,所以可以借助nslookup等方式来验证是否是真实IP,可以通过censys工具来分析出真实IP,或者通过全球ping来找到真实IP
域名:找到IP之后可以通过fofa或者其他在线网站找到该服务器的端口开放信息,也可以使用IP去一些网站尝试反查域名,找到域名就可 以通过信息备案管理系统来查找域名对应的主办单位名称
同一个单位的其他资产:找到主办方单位名称可以通过QCC等网站来收集该单位的其他资产
子域名收集
为什么要收集子域名?因为我们获取的第一个资产往往是一个主站,范围太小了,几乎很难找到漏洞,我们就需要通过他的子域名去挖掘,因为很多子域名也是属于这个厂商的,而且子域一般安全防范做的相对来说不高,所以需要进行子域名收集,扩大挖掘广度。
工具收集
主要是靠字典,DNS服务商的字典一般是最准确有效的
以下列举3个常用工具,当然也可以使用其他的,主要还是靠字典的强大性,工具顺手即可。
1.oneforall:可以扫描出IP,子域名,标题等信息,还能导出excel
2.subDomainsBrute:可以扫描出子域名,IP地址
3.layer子域名挖掘机:速度慢,比较老,图形化
在线收集
以下是我推荐的常用的在线收集子域名网站
https://phpinfo.me/domain
https://site.ip138.com/
https://www.dnsgrep.cn/
通过证书收集
1.通过https网址旁边的url的锁,查看证书,可以发现相关的子域
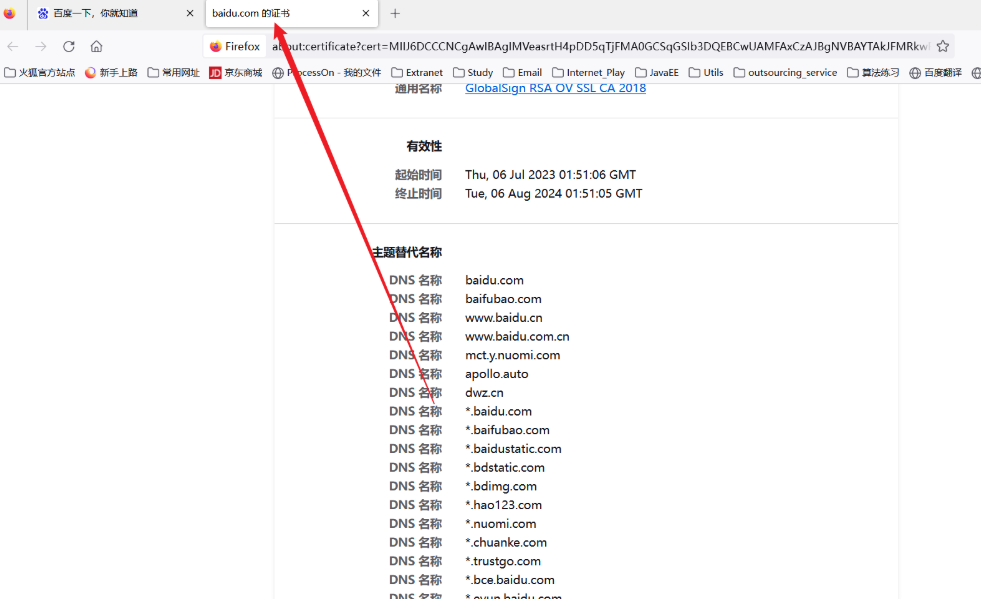
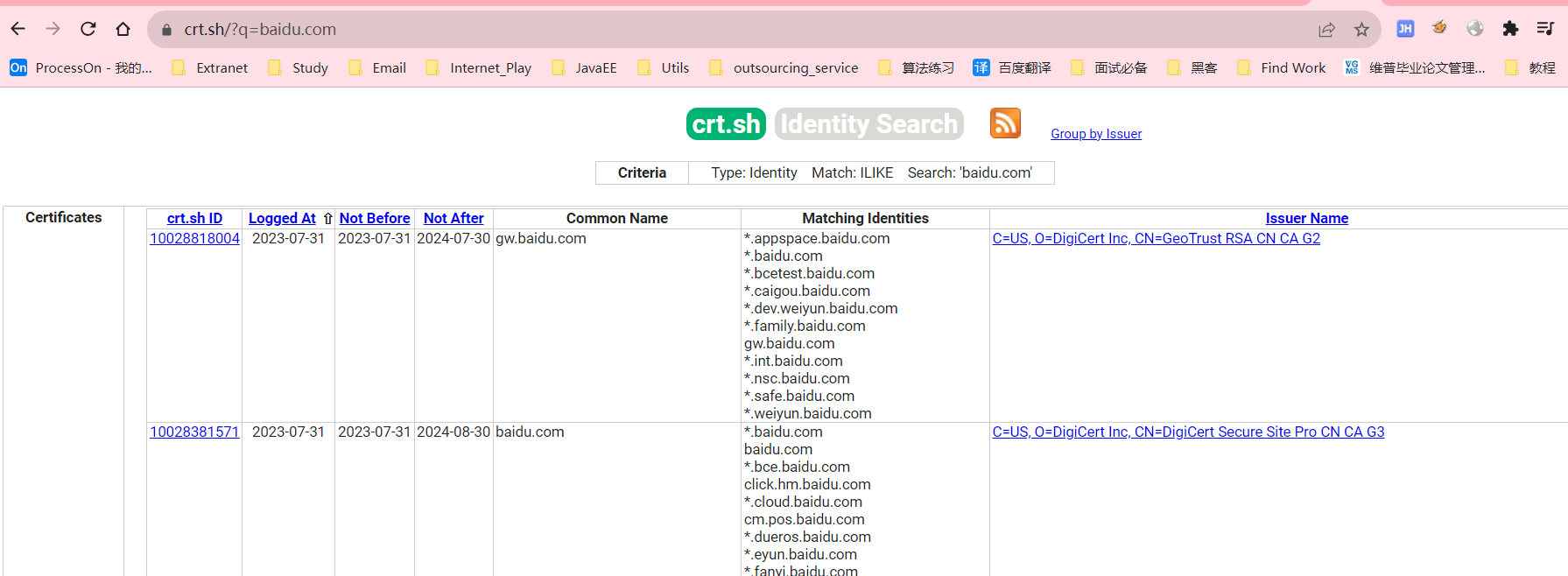
2.https://crt.sh/
3.https://search.censys.io/

细节收集
各种细节
(1)网站的crossdomain.xml文件和返回包中的Access-Control-Allow-Origin
(2)返回包中的CSP(Content-Security-Policy)头
(3)网站robots.txt文件
(4)网站sitemap文件(BurpSuit抓包中的sitemap)
(5)微步:https://x.threatbook.cn/
google语法
可以在google,bing搜索引擎中使用以下语法:
site:找到与指定网站有联系的URL。例如:site:baidu.com
intitle:返回所有网页标题中包含关键词的网页。
inurl:只搜索网页链接含有关键词的页面。
intext:只搜索网页正文部分含有关键词的页面。
IP信息收集
为什么要进行IP收集?因为仅仅通过子域名挖掘漏洞是不够的,这些域名,子域名是大家都能访问到的资产,我们必须找到真实IP,有了IP,我们才能做更多事,比如后面的端口信息收集,通过端口找到其他的服务,这是大多数人不能访问到的
找到服务器的IP地址之后,就可以通过fofa进行资产收集,比如使用 ip="IP"语法就可以收集到相关资产信息
在有了目标的域名之后,并不一定能直接找到真实IP,还要考虑CDN
CDN
CDN 是构建在数据网络上的一种分布式的内容分发网,是企业利用分布在不同区域的节点服务器群组成流量分配管理平台,为用户提供内容分散存储和高速缓存服务。
如何判断CDN
1.多地ping
如果多地ping的ip不一样,说明具有CDN
站长工具:https://ping.chinaz.com/
https://www.itdog.cn/ping/
2.查询域名解析地址:nslookup
如果地址有多个,说明该域名具有CDN
如何绕过CDN
1.通过域名解析记录
通过多年前的域名解析记录,多年前的IP可能就是真实IP
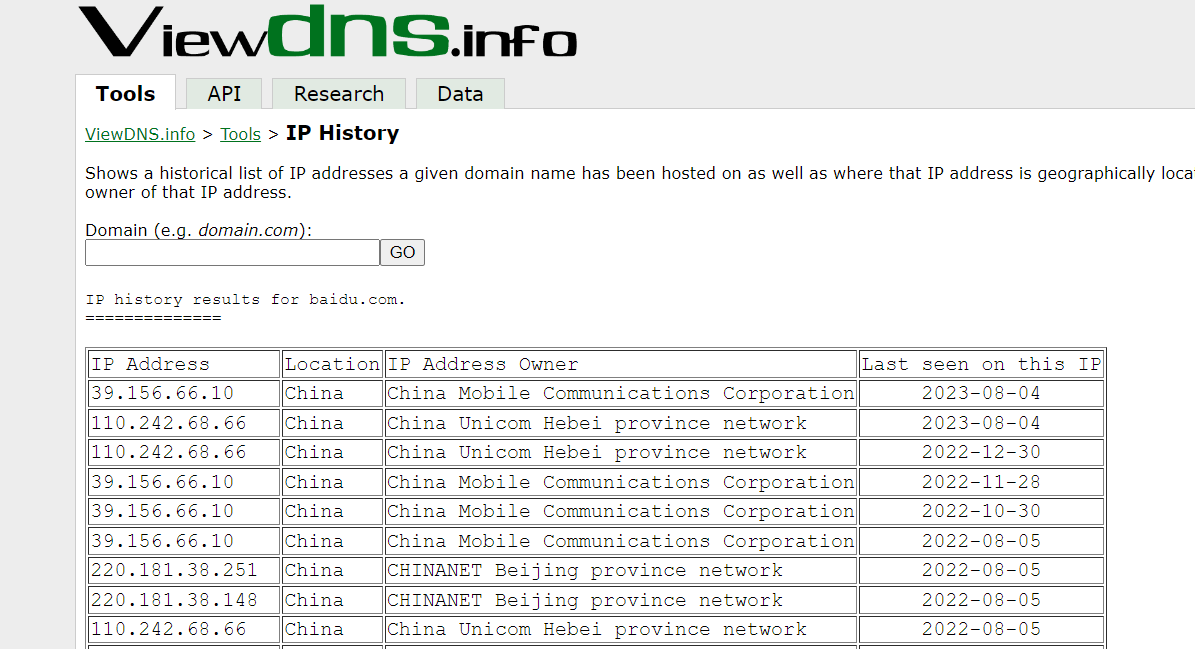
https://viewdns.info/iphistory/
https://site.ip138.com/
https://x.threatbook.cn/
其中https://viewdns.info/iphistory/比较全面,这个网站几乎可以查所有的域名,然而站长工具却不能查baidu.com
2.网络空间搜索引擎
通过logo,证书的查询可以找到他的真实IP
什么是网络空间搜索引擎?
交换机、路由器、网络摄像头、私人网盘、打印机、ATM、物联网家电等等,这些所有的系统和设备,就是网络里面的一个个节点,共同组成了网络空间,我们想直接通过引擎去搜索网络上的这些硬件设备,就有了网络空间搜索引擎
**fofa:**https://fofa.info/
非会员fofa一次只能查60条
语法:
ip:ip=“”
域名:domain=“baidu.com”
title:title=“后台管理系统”
body:body=“后台管理系统”
cert:这个证书可以在浏览器中找到,不过是16进制的,需要转为10进制,例如cert=“26585094245224241434632730821”
icp:icp=“京ICP证030173号”,备案信息可以通过天眼查来查
logo:这个要会员,icon_hash=“xxxx”,fofa会自动将图标转为hash
js/css/html等静态特征值
**shodan:**https://www.shodan.io
示例:
查询摄像头:port:“8080” product:“webcamXP httpd”
3.子域名
由于CDN加速需要计费,所以一般都是对主站进行使用CDN,子域名不需要,所以可以通过子域名来找到真实的IP
4.异地ping
https://ping.chinaz.com/
https://www.itdog.cn/ping/
由于很多厂商只是在国内使用了CDN,然而国外没有做,所以使用国外的IP进行ping,就可以得到真实IP
5.通过censys分析
https://search.censys.io/
目前Censys工具就能实现对整个互联网的扫描,Censys是一款用以搜索联网设备信息的新型搜索引擎,安全专家可
以使用它来评估他们实现方案的安全性,而黑客则可以使用它作为前期侦查攻击目标、收集目标信息的强大利器。
Censys搜索引擎能够扫描整个互联网,Censys每天都会扫描IPv4地址空间,以搜索所有联网设备并收集相关的信
息,并返回一份有关资源(如设备、网站和证书)配置和部署信息的总体报告。
而攻击者唯一需要做的就是把上面用文字描述的搜索词翻译成实际的搜索查询参数。
6.信息泄露
信息泄露不仅仅是泄露文件目录,可能有的开发会把部分代码上传到github,里面可能存在一些敏感信息也是可以利用的
服务器日志文件
探针文件,例如phpinfo
网站备份压缩文件
.DS Store
.hg
.git
SVN
Web.xml
7.其他方式
1.邮件测试(一般的邮件系统都在内部,没有经过CDN的解析,通过目标网站用户注册或者RSS订阅功能,查看邮件,寻找邮件头中的邮件服务器域名IP,ping这个邮件服务器的域名,就可以获得目标的真实IP(必须是目标自己的邮件服务器,第三方或者公共邮件服务器是没有用的)。) ,总的来说就是通过获取邮件服务器的Ip,就相当于目标服务器的IP
邮件常见交互功能点:
RSS订阅
邮箱注册、激活处
邮箱找回密码处
产品更新的邮件推送
某业务执行后发送的邮件通知
员工邮箱、邮件管理平台等入口处的忘记密码
2.APP抓包:有时候资产项目就有一个app产品,在抓包的时候获取可以发现IP
3.网站存在的漏洞:比如XSS,就可以利用这个漏洞与dnslog让对方服务器来ping我们的dnslog,从而获取IP
4.异常信息,调试信息:有的网站的异常信息可能会泄露真实IP
5.host碰撞
可以观看此视频学习host碰撞:https://www.bilibili.com/video/BV1Pe4y1J7Ps/?spm_id_from=333.788&vd_source=8dbc5a062f565ab2da401cd9c255724b
本人的理解(或许有些模糊,后面有更深的理解再回来补充):
一个网站下可能有多个服务,但是一般服务都是在内网通过nginx来映射到外网的,当我们访问一个域名,就会被解析为一个IP,找到IP之后,然后发送到nginx,nginx会根据我们的请求找到对应的服务。
但是如果nginx有一个错误的配置,就是输入某个域名会找到不该让外部访问的服务。所以在我们信息收集的时候,这个错误配置中的域名我们一般是不知道的,所以无法访问到私密的服务,为了访问这个服务,我们就可以进行host碰撞,本质就是猜测域名,然后让nginx帮我们找到对应的服务
端口信息收集
为什么要进行端口信息收集?因为我们访问的网站一般都是web服务,为了从更多地方去找漏洞,不得不探测目标还有哪些开放的服务,这个时候就需要进行端口信息收集,因为一个端口都是对应某一个服务的,我们可以通过端口找到对应的服务,然后去网上搜索该服务是否存在公开漏洞,然后从中挖掘漏洞
端口扫描工具
提示:在真实漏洞挖掘中,不建议使用端口扫描工具,建议通过fofa等空间搜索引擎进行被动收集
nmap
nmap是kali自带的工具
端口状态描述:
open(开放的),意味着目标主机的应用程序在监听(listen)。
closed(关闭的),意味着端口没有监听,但随时可能打开。
filtered(被过滤的),意味着firewall,阻碍了端口访问,无法确定端口开启与否
unfiltered(未被过滤的)。无法确定开放与否。
参数:
-sS:半开放扫描SYN,这是默认的,不需要完整的三次握手即可获取端口信息,不会产生任何会话,不会在目标主机留下日志,隐蔽性好
-sT:全开放扫描,完整三次握手,会建立连接,相对是S比较慢,而且会留下痕迹
-sV:版本检测、使用版本检测扫描之前需要先扫描开放了哪些端口
-PN:可以绕过PING命令,用于远程主机是存活在网络上的,目标主机禁pig的情况下
-A:使用所有高级扫描选项;全端口扫描
-0:操作系统探测:
-T:设置扫描速度,1-6
-sP:主机存活性扫描,arp直连方式,就是使用ping确定端口是否开放。
-sU:发送UDP数据包
-sF:任何扫描工具都具有流量特征,nmap使用半开放扫描会留下SYN特征,容易被大多数防火墙捕获,所以使用-SF参数,就会把数据包格式变为Fin,从而躲避防火墙
msscan
msscan是kali自带的扫描工具,这个工具相对于nmap速度更快
MASSCAN是TCP端口扫描程序,它异步传输SYN数据包,产生的结果与最著名的端口扫描程序nmap相似。在内部,它更像scanrand、unicornscan和ZMap,使用异步传输。它是一个灵活的实用程序,允许任意地址和端口范围。
Masscan 针对 TCP 端口进行扫描,使用 SYN 扫描的方式,不建立一个完全的 TCP 连接,而是首先发送一个 SYN 数据包到目标端口,然后等待接收。如果接收到 SYN-ACK 包,则说明该端口是开放的,此时发送一个 RST 结束建立过程即可;否则,若目标返回 RST,则端口不开放。
示例用法:
masscan -P80,8000-8100 10.0.0.0/8 --rate=10000
解释:以10kpps的速度扫描10.0.0.0上的某些web端口
目录信息收集
为什么要进行目录信息收集?因为往往通过目录的收集,我们能获取到该网站本来不应该让我们看到的信息,这些信息可能是敏感信息,可能是一些服务配置信息等,有了这些信息,我们就能从更多的角度去挖掘,那么我们如果进行目录收集呢?
我们可以通过枚举后台路径,尝试找到隐藏的一些目录,文件等信息,从中找到一些线索,从而扩大挖掘面积,因此可以借用一些工具,比如dirsearch等目录扫描工具,其实目录扫描工具挺多的,重点还是在于字典的强大。
1.扫描后台路径
2.扫描敏感文件
1、robots.txt
2、网站备份文件
3、后台登录目录
4、安装包
5、上传目录
6、mysql管理接口
7、phpinfo(探针文件)
8、网站文本编辑器
9、/etc/passwd、/etc/shadow、/etc/sudoers
10、Mac下的.DS Store
11、vim编辑器备份文件(.Swp)
12、WEB-INF泄露
服务器信息收集
为什么需要进行服务器信息收集?因为获取服务器本身就存在漏洞,我们不仅仅需要在网站功能上找漏洞,还要在服务器本身找漏洞。
服务器信息收集主要查看该服务器使用什么waf,cms,如果知道了这些信息,就可以尝试去搜索相关漏洞,然后利用这些漏洞进行绕过
1.waf识别
waf信息可以帮助我们绕过一些安全检测
手工探查WAF:
云盾:响应头包含yundun关键字;页面源代码有errors…aliyun.com
安全狗:响应头包含waf2.0、Safedog等字样
腾讯云:阻止响应页面,包含waf.tencent-clound.com
阻止响应代码405 method not allow
安全宝:恶意请求时返回405恶意代码响应头包含X-Powered-by:Anquanbao
百度云加速:响应头包含Yunjiasu-ngnix
创宇盾:恶意请求时页面URL:365cyd.com、365cyd.net
自动探测工具
kali 自带:wafw00f
命令:wafw00f 域名
2.cms识别
cms信息可以利用一些通杀漏洞
1、潮汐指纹:http:/finger.tidesec.net/
2、whatweb工具:kali自带
3、插件wappalyzer
4、网页源代码meta name=“generator”
企业信息收集
为什么我们要进行企业信息收集呢?
因为有时候我们找到一个漏洞,不知道是哪个公司的,提交漏洞的时候就无法指定公司,这个漏洞就不会收。
而且通过企业信息收集,比如企业邮箱,法定代表人,或许可以利用社工手段达到一些目的。
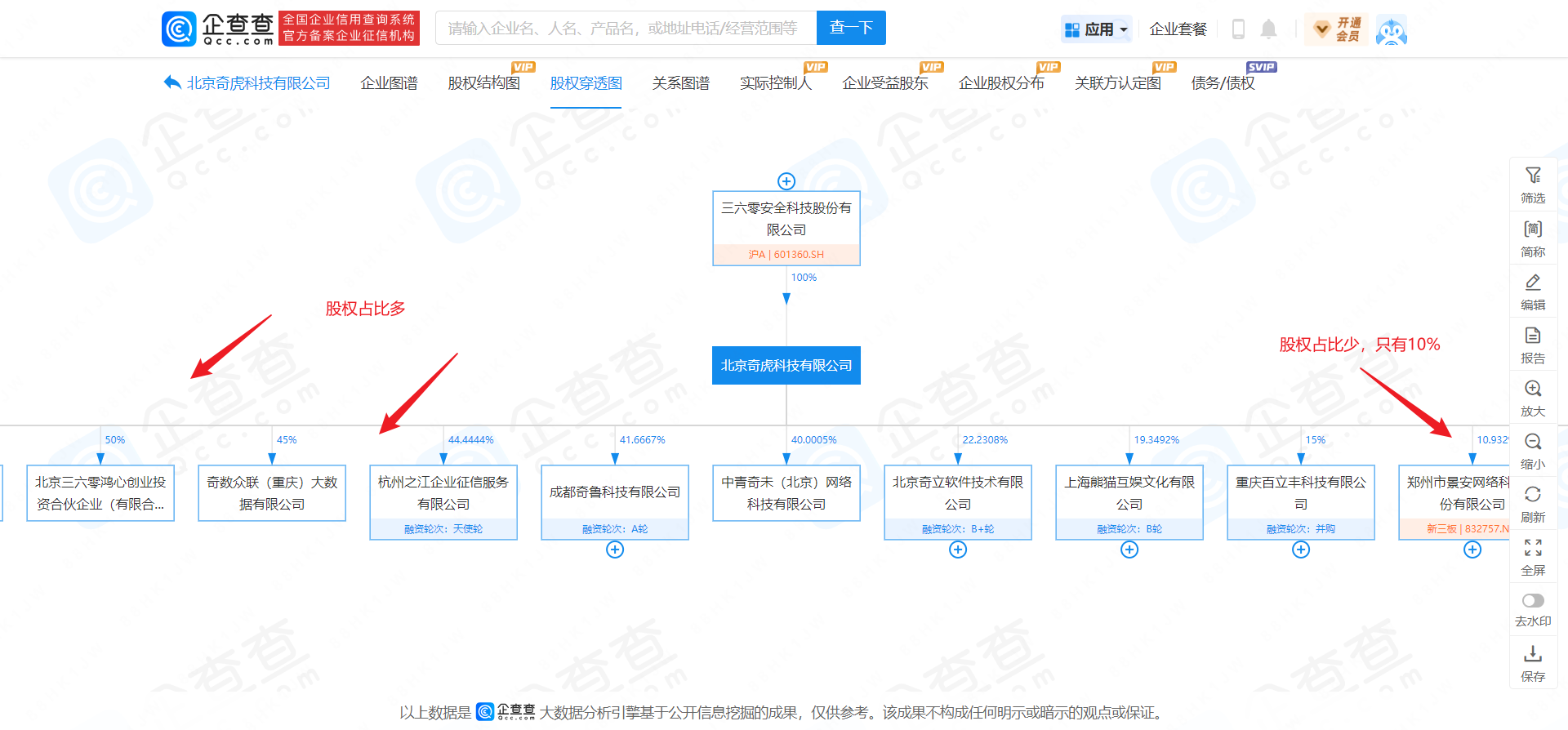
还能通过目标企业找到他的股权穿透图,看看和其他公司的关联,如果股权占比大,也是可以从其他公司入手的。
还能找到对应企业的其他知识产权,里面可以找到对应的公众号,小程序与其他网站,也是可以从这些方面入手。
那我们可以通过哪些途径找到一些企业信息呢?
可以通过企查查,天眼查,小蓝本,爱企查,钉钉企典等网站可以查找以下信息:
- 股权架构
- 知识产权,经营状况(微信小程序,公众号,app等)
- 邮箱,法定代表人
比如我们可以通过QCC重点看一下股权穿透图,其中有些公司的股权占比很多,就可以从这些公司入手
自动化信息收集
为什么要进行自动化信息收集呢?因为信息收集不仅仅要讲究全面,还需要讲究效率,如果单单靠前面的思路手动一个一个收集,效率实在是太慢了,现在网上有很多开源的工具,集成了上面的一些信息收集思路,利用这些工具,可以提高我们的效率。
,常用的自动化信息收集工具有水泽,灯塔,goby,这里就重点介绍水泽。
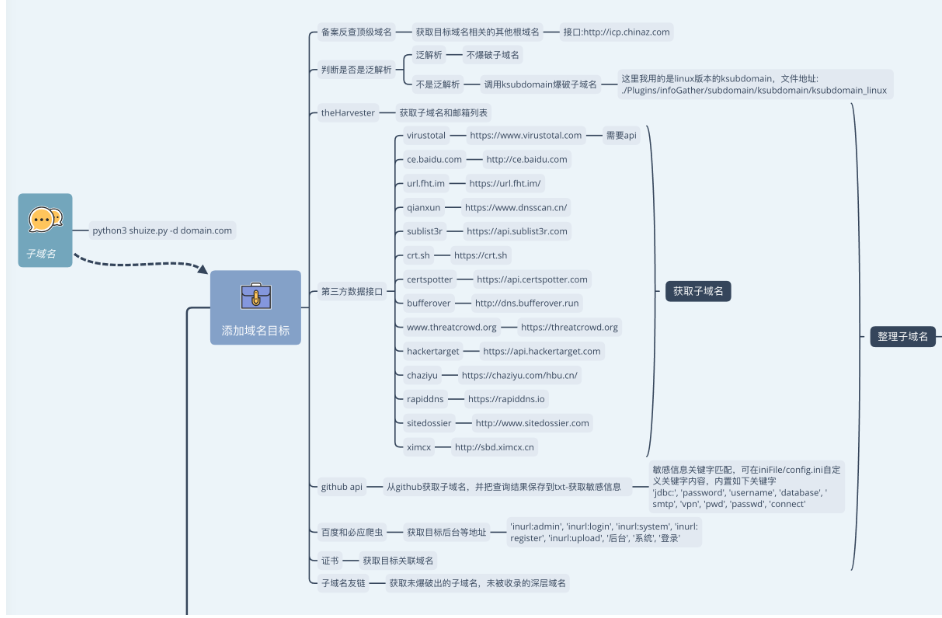
水泽
原理:
- 备案反查顶级域名
- 不是泛解析,调用ksubdomain爆破子域名
- theHarvest获取邮箱
- 第三方数据接口 -> 获取子域名
- github -> 从github获取子域名,并把查询结果保存到txt,并匹配关键字获取敏感信息
- 百度和必应爬虫
- 证书
- 子域名友链
- 解析子域名A记录,检测是否CDN和整理C段的IP
- 网络空间搜索引擎:Fofa和Shodan
- IP反查域名
- 存活探测
- 扫描结果保存在excel文件里
原理流程图:
C段收集
仅信息收集,不检测漏洞:python ShuiZe.py -c 123.9.12.0 --justInfoGather 1
解释:-c表示C段收集,–justInfoGather 设置为1表示不检测漏洞,只做信息收集
禁止子域名收集
不调用ksubdomain爆破子域名:python ShuiZe.py -c 123.9.12.0 --ksubdomain 0
结果展示:
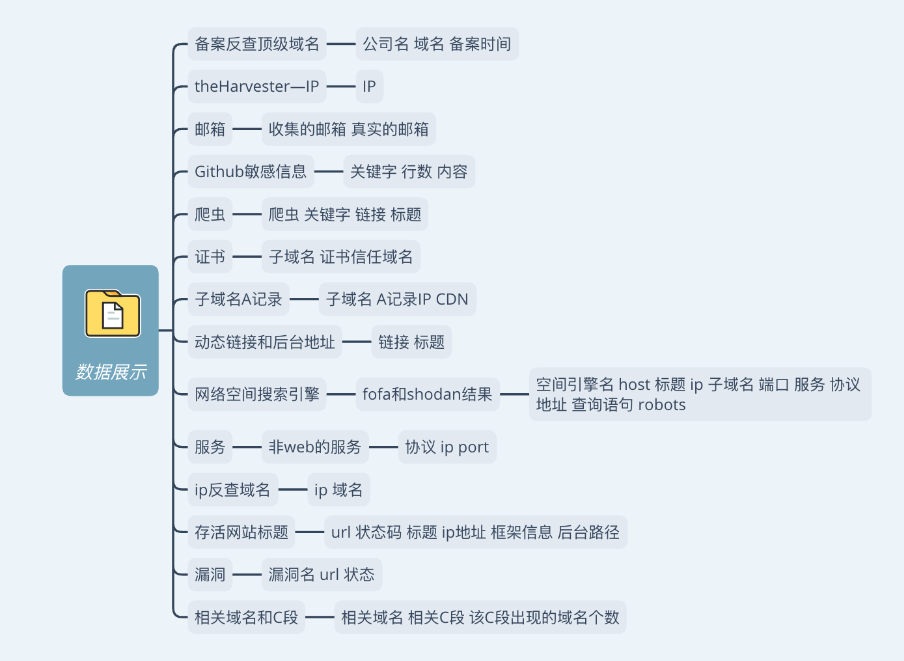
灯塔ARL
这是一个可视化工具,可以可视化新建任务来进行自动信息收集,也有设置监控的功能,因为有些资产是会更新的,所以可以通过监控功能设置定时自动化收集。
信息收集总结
针对不同的SRC要求,厂商可能会给定我们一个资产范围,比如子域名:*yuanboss.com,
刚开始我们可以通过给定的域名收集子域名,然后收集目录/端口,为了更进一步,我们就需要找到真实IP,因为子域名都是一些常见的资产,可能找不到漏洞了,这个时候就需要通过IP来查找其他开放服务,进而挖掘漏洞
在护网中我们获得信息就是目标名称,比如:xx学校,xx公司,这个时候我们就可以通过这些名字去QCC,天眼查等网站去找对应的公司,然后找到他的官网,接着就是找子域名,信息收集的逻辑就和上面的一样了。















 506
506











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











