









 本文介绍了Linux内核中的vmalloc内存分配过程,通过kmalloc和slab机制对比,详细剖析了vmalloc如何在vmalloc区中通过__vmalloc_node_range查找并分配连续或非连续的内存,以及__vmalloc_area_node如何申请物理内存并建立分页映射。
本文介绍了Linux内核中的vmalloc内存分配过程,通过kmalloc和slab机制对比,详细剖析了vmalloc如何在vmalloc区中通过__vmalloc_node_range查找并分配连续或非连续的内存,以及__vmalloc_area_node如何申请物理内存并建立分页映射。
介绍vmalloc之前,有必要说一下kmalloc。kmalloc内部是使用slab机制申请内存的,也就是kmalloc申请的内存在物理内存中是连续的。想了解slab机制的可以看下上一篇文章《slab内存分配机制》。
vmalloc内部申请的内存,与进程地址空间中申请内存是相同的逻辑,都是通过分页机制来实现的,不需要所用的内存在物理内存中是连续的。下面看下vmalloc是怎样实现的。
先看下内核中使用vmalloc的一个例子:
static ssize_t
ncp_file_write_iter(struct kiocb *iocb, struct iov_iter *from)
{
... ...
// 申请bufsize大小的内存
bouncebuffer = vmalloc(bufsize);
if (!bouncebuffer) {
errno = -EIO; /* -ENOMEM */
goto outrel;
}
pos = iocb->ki_pos;
while (iov_iter_count(from)) {
... ...
// 将数据从from拷贝到bouncebuffer
if (!copy_from_iter_full(bouncebuffer, to_write, from)) {
errno = -EFAULT;
break;
}
if (ncp_write_kernel(NCP_SERVER(inode),
NCP_FINFO(inode)->file_handle,
pos, to_write, bouncebuffer, &written_this_time) != 0) {
errno = -EIO;
break;
}
... ...
}
// 释放申请的内存
vfree(bouncebuffer);
... ...
}一 内核空间划分
介绍vmalloc之前,先看下内核的空间都是怎么划分的
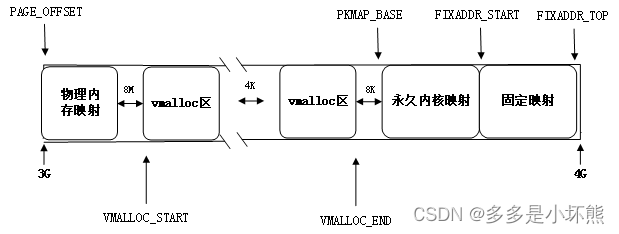
vmalloc申请的线性地址位于VMALLOC_START与VMALLOC_END之间。__vmalloc_node_range在指定的线性区内,查找size大小空闲的空间,指定的线性地址空间就是这块空间。以下称VMALLOC_START和VMALLOC_END之间的区域为vmalloc区。
下面看下vmalloc的实现
vmalloc(unsigned long size)
__vmalloc_node_flags(size, NUMA_NO_NODE,GFP_KERNEL)
__vmalloc_node(size, 1, flags, PAGE_KERNEL, node, __builtin_return_address(0))
__vmalloc_node_range(size, align, VMALLOC_START, VMALLOC_END, gfp_mask, prot, 0, node, caller)
从vmalloc开始,经过层层调用,最终调用到__vmalloc_node_range
二 __vmalloc_node_range
void *__vmalloc_node_range(unsigned long size, unsigned long align,
unsigned long start, unsigned long end, gfp_t gfp_mask,
pgprot_t prot, unsigned long vm_flags, int node,
const void *caller)
{
struct vm_struct *area;
void *addr;
unsigned long real_size = size;
size = PAGE_ALIGN(size);
if (!size || (size >> PAGE_SHIFT) > totalram_pages)
goto fail;
// 在vmalloc区查找size大小的空闲区域
area = __get_vm_area_node(size, align, VM_ALLOC | VM_UNINITIALIZED |
vm_flags, start, end, node, gfp_mask, caller);
if (!area)
goto fail;
addr = __vmalloc_area_node(area, gfp_mask, prot, node);
if (!addr)
return NULL;
/*
* In this function, newly allocated vm_struct has VM_UNINITIALIZED
* flag. It means that vm_struct is not fully initialized.
* Now, it is fully initialized, so remove this flag here.
*/
clear_vm_uninitialized_flag(area);
kmemleak_vmalloc(area, size, gfp_mask);
return addr;
fail:
warn_alloc(gfp_mask, NULL,
"vmalloc: allocation failure: %lu bytes", real_size);
return NULL;
}三 __get_vm_area_node
__vmalloc_node_range中调用__get_vm_area_node,从vmalloc区查找size大小的空闲区域,查找的区域信息保存在vm_struct类型的area变量中,vm_struct定义如下:
struct vm_struct {
struct vm_struct *next;
void *addr; 内存区内第一个内存单元的线性地址
unsigned long size; 内存区的大小+4096
unsigned long flags; 非连续内存区映射的内存的类型
struct page **pages;
unsigned int nr_pages;
phys_addr_t phys_addr;
const void *caller;
};
给vm_struct各成员赋值的代码如下,也就是vmap_area结构保存了搜索到的目的线性地址范围信息。
static void setup_vmalloc_vm(struct vm_struct *vm, struct vmap_area *va,
unsigned long flags, const void *caller)
{
spin_lock(&vmap_area_lock);
vm->flags = flags;
vm->addr = (void *)va->va_start;
vm->size = va->va_end - va->va_start;
vm->caller = caller;
va->vm = vm;
va->flags |= VM_VM_AREA;
spin_unlock(&vmap_area_lock);
}四 查找线性地址范围
vmap_area的定义如下:
struct vmap_area {
unsigned long va_start; // 线性地址开始位置
unsigned long va_end; // 线性地址结束位置
unsigned long flags;
struct rb_node rb_node; // 红黑树节点
struct list_head list; /* address sorted list */
struct llist_node purge_list; /* "lazy purge" list */
struct vm_struct *vm; // 关联的vm_struct
struct rcu_head rcu_head;
};
首先看下下面的图:

vmalloc区中每一个被使用的地址范围,都用一个vmap_area的对象表示,所有的vmap_area通过一个红黑树串联起来,红黑树的根节点保存在vmap_area_root全局变量中。
左边的红色区域,表示需要查找的size大小的区域,蓝底的区域,表示已被使用的区域。第一个蓝底区域之前有足够的区域可以分配,因此在vmalloc开始的位置进行分配,将分配的的区域添加到红黑树链表中,如上图右侧所示。
下面看另一种情况:

vmalloc开始位置到第一个蓝底区域之前,没有足够的空间,则依次遍历已分配的区域,查看两个区域之间是否有足够的空间。找到的话,则使用此区域,如上图右侧所示。
查找空闲区域的方法是alloc_vmap_area,这里就不贴了。
四__vmalloc_area_node
在上面提到的__vmalloc_node_range方法中,调用__get_vm_area_node获取空闲的线性地址区域后,此时的线性地址是没有对应的物理内存的,然后调用__vmalloc_area_node为其申请物理内存。
__vmalloc_area_node的主要逻辑是计算为申请的线性地址空间映射内存所需要的页框数量nr_pages;计算保存nr_pages个页框所需空间array_size;循环申请页框,总共申请nr_pages个,这些指针的地址保存在area->pages中。
static void *__vmalloc_area_node(struct vm_struct *area, gfp_t gfp_mask,
pgprot_t prot, int node)
{
struct page **pages;
unsigned int nr_pages, array_size, i;
const gfp_t nested_gfp = (gfp_mask & GFP_RECLAIM_MASK) | __GFP_ZERO;
const gfp_t alloc_mask = gfp_mask | __GFP_NOWARN;
const gfp_t highmem_mask = (gfp_mask & (GFP_DMA | GFP_DMA32)) ?
0 :
__GFP_HIGHMEM;
// 计算这块线性地址区域需要的页框数量(每个页框4k)
nr_pages = get_vm_area_size(area) >> PAGE_SHIFT;
// 计算保存nr_pages个指针需要的空间大小
array_size = (nr_pages * sizeof(struct page *));
area->nr_pages = nr_pages;
/* Please note that the recursion is strictly bounded. */
// 申请内存,保存nr_pages个指针
if (array_size > PAGE_SIZE) {
pages = __vmalloc_node(array_size, 1, nested_gfp|highmem_mask,
PAGE_KERNEL, node, area->caller);
} else {
pages = kmalloc_node(array_size, nested_gfp, node);
}
area->pages = pages;
if (!area->pages) {
remove_vm_area(area->addr);
kfree(area);
return NULL;
}
// 申请nr_pages个页框
for (i = 0; i < area->nr_pages; i++) {
struct page *page;
if (node == NUMA_NO_NODE)
page = alloc_page(alloc_mask|highmem_mask);
else
page = alloc_pages_node(node, alloc_mask|highmem_mask, 0);
if (unlikely(!page)) {
/* Successfully allocated i pages, free them in __vunmap() */
area->nr_pages = i;
goto fail;
}
// 将申请页框的地址保存到前面申请的内存中
area->pages[i] = page;
if (gfpflags_allow_blocking(gfp_mask|highmem_mask))
cond_resched();
}
if (map_vm_area(area, prot, pages))
goto fail;
return area->addr;
fail:
warn_alloc(gfp_mask, NULL,
"vmalloc: allocation failure, allocated %ld of %ld bytes",
(area->nr_pages*PAGE_SIZE), area->size);
vfree(area->addr);
return NULL;
}最后调用map_vm_area建立分页各层之间的映射关系。对于x86系统,页表分为3级,从上到下依次为:页目录,页表,页框。__vmalloc_area_node中循环申请的是页框。
一个页框4k,一个地址4字节,因此一个页框可以保存1024个地址。一个页表中保存的是1024个页框的地址。
与页表类型,一个页目录中,保存了1024个页表的地址。
关于分页机制,这里就不详细展开了。
文章开头提到过,vmalloc中申请的内存,线性地址相邻的内存,在物理内存中不一定是相邻的。因为在__vmalloc_area_node的循环中,每次申请一个页框。















 2958
2958

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









