






hive中现有的数据(分区字段是时间event_time)
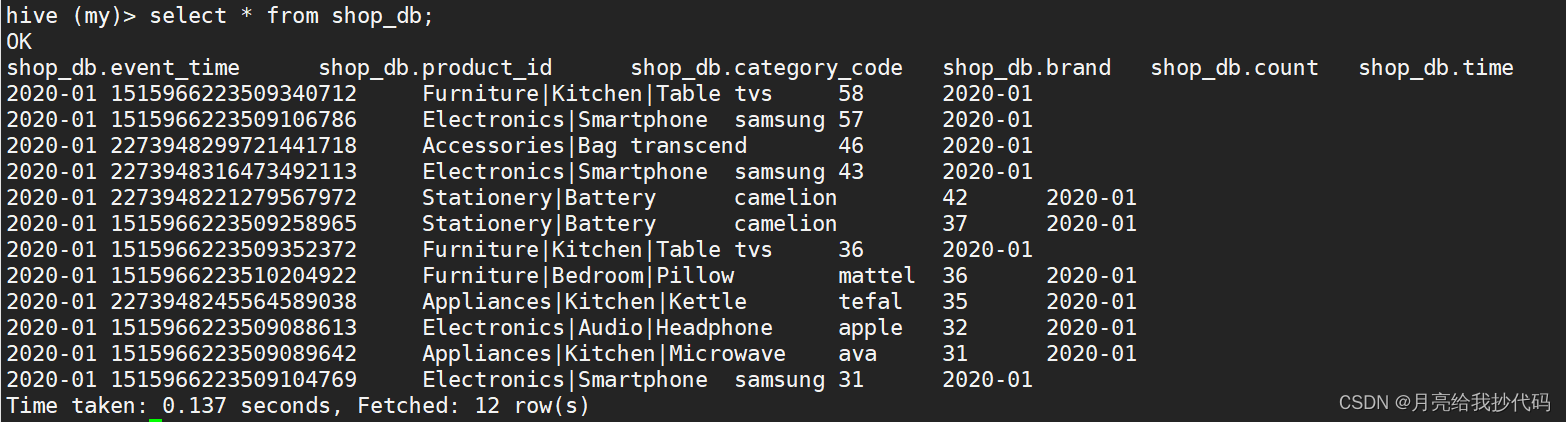
MySQL库中增量抽取的数据 (部分展示)
创建Sparksession对象
val spark: SparkSession = SparkSession
.builder()
.appName("H_work_fullTostatic")
.master("local[*]")
.config("hive.metastore.uris", "thrift://hadoop106:9083")
.config(
"spark.sql.metastore.warehouse",
"hdfs://hadoop106:8020/user/hive2/warehouse"
)
.enableHiveSupport()
.getOrCreate()读取MySQL中的所有数据,创建临时表
spark.read
.format("jdbc")
.option("url", "jdbc:mysql://hadoop106:3306/spark_db")
.option("driver", "com.mysql.jdbc.Driver")
.option("user", "root")
.option("password", "000000")
.option("dbtable", "top10_shop_month")
.load()
.createOrReplaceTempView("data")设置动态分区
spark.sql("""
|set hive.exec.dynamic.partition = true
|""".stripMargin)
spark.sql("""
|set hive.exec.dynamic.partition.mode = nonstrict
|""".stripMargin)
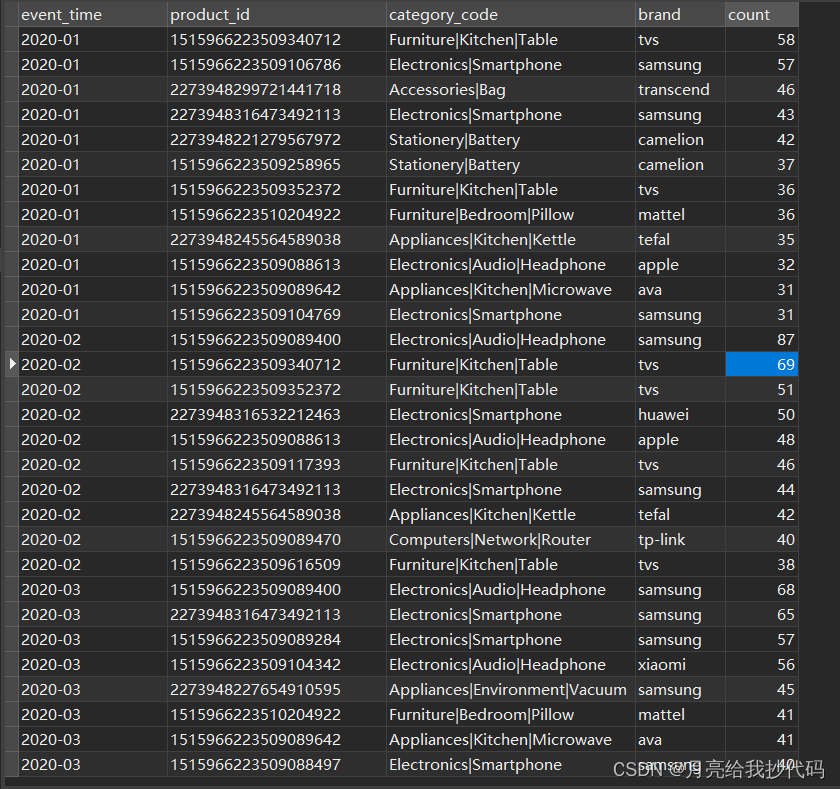
增量数据的获取和插入
spark.sql("""
|select * from
|(select event_time,product_id,category_code,brand,count
|from
| my.shop_db
|union
|select *
| from data)t1
|order by event_time
|""".stripMargin).createOrReplaceTempView("increment_data")
重写数据到hive分区表中
spark.sql("""
| insert overwrite table my.shop_db partition(time)
| select *,event_time from increment_data
|""".stripMargin)
spark.stop() //spark停止
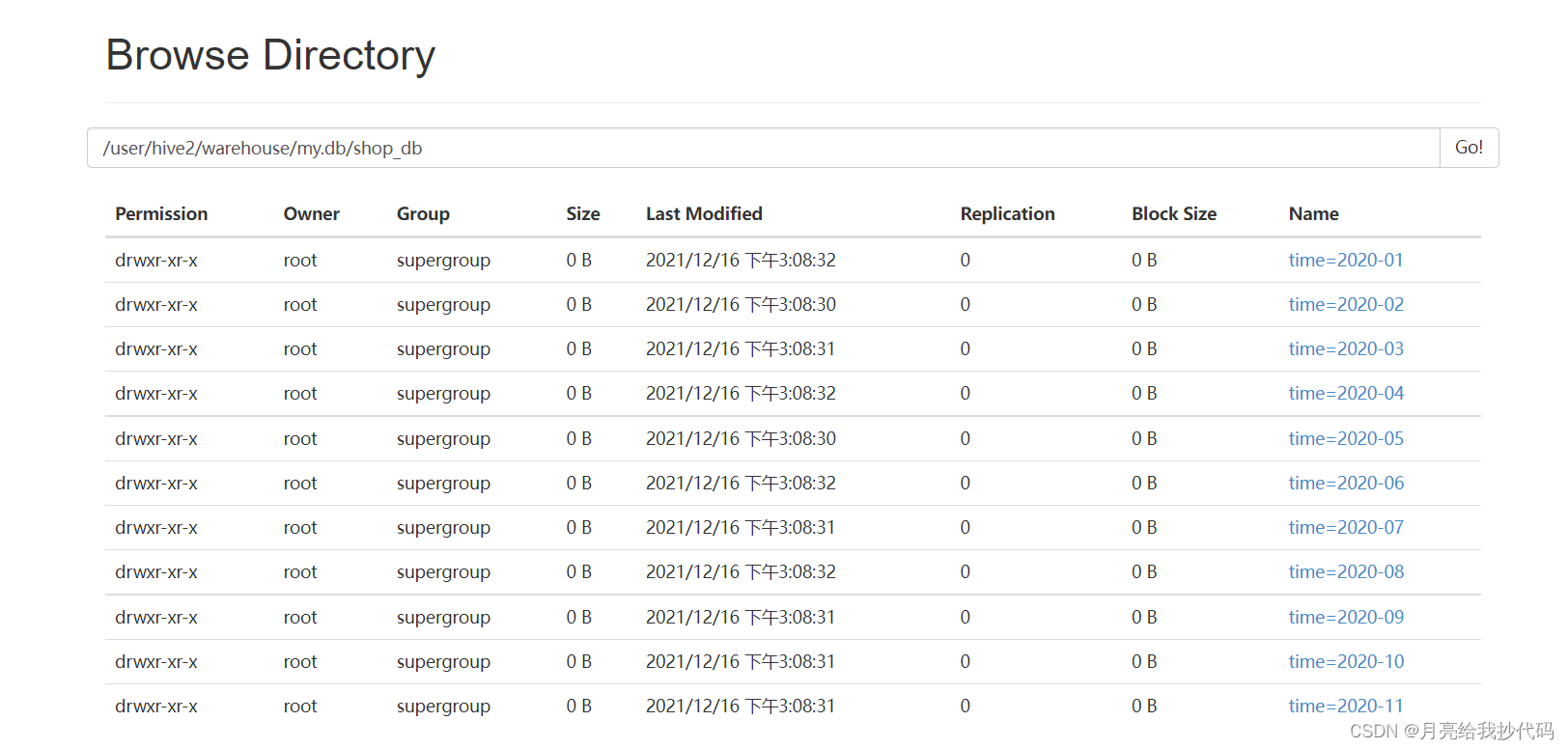
增量插入成功
















 1690
1690











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











