









文章目录
- Hive 是什么? 跟数据仓库区别?
- 为什么要使用 Hive? 它的优缺点以及作用是什么?
- Hive 架构
- Hive 运行原理
- 查询建表与 like 建表
- Hive 默认分隔符
- Hive 外部表与内部表的区别
- Hive 删除外部表删除的是什么?如何恢复?
- Hive 中的分区与排序区别
- Hive 分区表的作用是什么,是否越多越好,为什么?
- Hive 中的分桶表
- Hive 数据倾斜以及解决方案
- Hive 的用户自定义函数 UDF 实现步骤与流程
- 简述对于 UDF/UDAF/UDTF 的理解
- 对数据进行分层作用(数仓的作用)的理解
- Hive SQL 转化为 MR 的过程?
- Hive 的存储引擎和计算引擎
- Hive 存储数据吗?
- Hive 的文件存储格式都有哪些
- Hive 中如何调整 Mapper 和 Reducer 的数目
- 介绍下知道的 Hive 窗口函数,举一些例子
- Hive SOL 实现查询用户连续登陆,讲讲思路
- Hive 的 union 和 unionall 的区别
- Hive 的 join 操作原理,leftjoin、right join、inner join、outer join 的异同?
- Hive Shuffle 的具体过程
- Hive 如何优化 join 操作
- Hive 中的 MapJoin
- Hive 的执行顺序
- Hive 使用的时候会将数据同步到 HDFS,小文件问题怎么解决的?
- Hive 有哪些保存元数据的方式,都有什么特点?
- Hive count(distinct) 有几个 reduce,海量数据会有什么问题?
- 了解 Hive SQL 吗?讲讲分析函数?
- 说说 over partition by 与 group by 的区别
- 分析函数中加 Order By 和不加 Order By 的区别?
- Hive 中 Metastore 服务作用
- HiveServer2 是什么?
- Hive 表字段换类型怎么办
- Parquet 文件优势
- HQL:行转列、列转行
Hive 是什么? 跟数据仓库区别?
Hive 是基于 Hadoop 的开源的数据仓库工具,用于处理海量结构化数据。
区别:
-
存储不同。Hive 是存储在 HDFS 上的。
-
语言不同。Hive 使用的是 HQL 语言,而传统的数仓使用的是 SQL。
-
Hive 的灵活性更好。Hive 元数据存储独立于数据存储之外,从而解耦元数据和数据。
-
分析速度更快。Hive 计算依赖于 MapReduce 和集群规模,还可以与 Spark 进行交互。
-
可靠性高。Hive 的数据存储在 HDFS 中,容错性高,因为磁盘是可以进行持久化的。
本题参考文章:1.Hive与传统数据仓库的比较
为什么要使用 Hive? 它的优缺点以及作用是什么?
Hive 能够把 HDFS 中结构化的数据映射成表,可以处理海量的结构化数据。
优点:
-
采用类似 SQL 的语法,上手容易。
-
Hive 对 MapReduce 进行了包装,开发人员不需要写 MapReduce,减少了学习成本。
-
能够处理海量结构化数据。
Hive 的缺点:
-
由于 Hive 主要用于数据分析,因此延时比较高,不适用于实时场景,主要用于做离线大数据分析;
-
Hive 的 HQL 表达能力有限;
-
数据挖掘方面不擅长;
-
Hive 的效率比较低;
-
Hive 自动生成的 MapReduce 作业,通常情况下不够智能化;
-
Hive调优比较困难,粒度较粗。
本题参考文章:Hive的概念,作用,优缺点
Hive 架构

本题参考文章:一篇文章搞懂 Hive 的系统架构
Hive 运行原理
-
用户将查询语句发送给 Driver;
-
Driver 调用解析器(Antlr),将查询语句解析成抽象语法树,发送给编译器;
-
编译器拿到抽象语法树,向元数据库请求并获取对应的元数据信息;
-
元数据库接收请求并返回元数据信息;
-
编译器根据元数据生成逻辑执行计划,返回给 Driver;
-
Driver 调用优化器对逻辑执行计划进行优化,减少 shuffle 数据量,发送给执行器;
-
执行器拿到优化好的逻辑执行计划,将其转化成可运行的 Job,并发送给 Hadoop;
-
执行计划,返回结果。
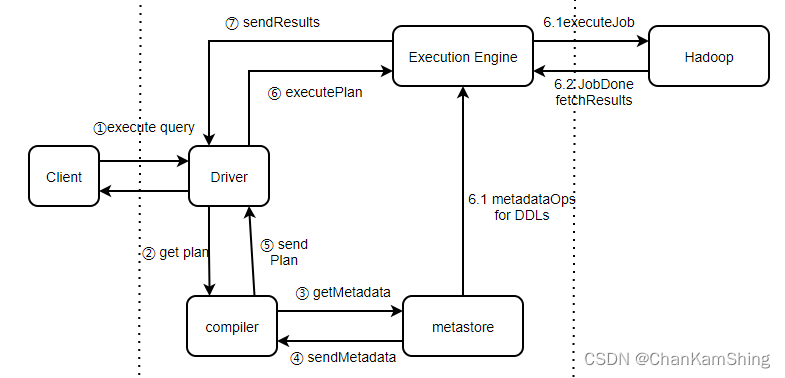
本题参考文章:Hive执行流程原理
查询建表与 like 建表
查询建表缺点:所有的数据类型默认是最大范围
CREATE [TEMPORARY,EXTERNAL] TABLE [if not exist]
[db_ name. ]name [ROW FORMAT row_ format] [STORED AS
file_ format] AS select_ statement
like 建表:
CREATE TABLE table2 like table1;
Hive 默认分隔符
默认行分隔符为 /n,默认字段分隔符为 \001。
Hive 外部表与内部表的区别
内部表的数据由 Hive 管理,且存储在 hive.metastore.warehouse.dir 配置的路径中。
external 外部表的数据由 HDFS 存储,路径可以自己指定。
删除表时,内部表会把元数据及真实数据删除,而外部表不会删除真实数据。
Hive 删除外部表删除的是什么?如何恢复?
我们可以通过 drop table tb_name 的命令将外部表删除。但是外部表只会将元数据删除,HDFS 上依旧存在外部表的所有数据。
如果想要恢复,我们可以先创建原来的外部表,然后直接通过表的修复命令 MSCK REPAIR TABLE table_name; 进行数据恢复。
Hive 中的分区与排序区别
-
order by: 对数据进行全局排序,在 reduce 中进行排序,只有一个 reduce 工作。
-
sort by: 对数据进行局部排序,进入 reduce 前完成排序,一般和
distribute by使用。当设置set mapred.reduce.tasks=1时,效果和order by一样。 -
distribute by: 对 key 进行分区,结合
sort by实现分区排序 -
partition by: 同样也是对 key 进行分区,但它只能用在窗口函数中,结合
order by实现分区排序。 -
cluster by: 当
distribute by和sort by的字段相同时,可以使用cluster by代替,但cluster by只能进行升序排列,不能指定排序规则。
Hive 分区表的作用是什么,是否越多越好,为什么?
作用: 分区表本质上对应的就是 HDFS 中的一个文件夹,其中存储的就是分区表的数据。分区表就是将数据通过指定的分区字段存储到各自的文件夹中,在海量数据中可以加快查询效率。
分区表的数量不宜过多。 因为 Hive 的底层数据就是存储在 HDFS 上,如果分区表中的文件数据量很小,会造成小文件过多,给 NameNode 带来很大压力,会导致内存溢出,严重还会导致 HDFS 直接崩溃。
Hive 中的分桶表
Hive 中的分桶表主要是通过获取 clustered by(col) 指定的字段哈希值与分桶的数量进行取模分组,最后根据指定字段对每个桶进行排序sort by(col) ,完成分桶。
--按照员工编号散列到四个 bucket 中
CREATE EXTERNAL TABLE emp_bucket(
empno INT,
ename STRING,
job STRING,
mgr INT,
hiredate TIMESTAMP,
sal DECIMAL(7,2),
comm DECIMAL(7,2),
deptno INT)
CLUSTERED BY(empno) SORTED BY(empno ASC) INTO 4 BUCKETS
ROW FORMAT DELIMITED FIELDS TERMINATED BY "\t"
LOCATION '/hive/emp_bucket';
在物理层面上,分桶其实就是根据规则,创建文件的过程,而分区则是创建文件夹的过程。
Hive 数据倾斜以及解决方案
数据计算时发生了 shuffle 操作,导致对数据进行了重新分区。
| 关键词 | 情形 | 后果 |
|---|---|---|
| join | 某个或某几个key比较集中,或者存在大量null key | 分发到某一个或者某几个Reduce上的数据远高于平均值 |
| group by | 维度过小,某值的数量过多 | 某个维度或者某几个维度且这些维度的数据量特别大,集中在一个reduce |
join 操作导致的倾斜:
- 同字段数据但不同类型关联产生数据倾斜。
转换成统一类型。
- null key关联。
让 null key 不参与关联,使用 union all 与关联后的数据进行合并。或者为 null key 加盐,赋予固定字符串+随机值的形式。
-
提高 reduce 并行度
-
过滤倾斜 join,单独进行 join 然后再合并。
group by 操作导致的倾斜:
-
开启负载均衡
-
group by 双重聚合
本题参考文章:Hive数据倾斜原因及解决方案
Hive 的用户自定义函数 UDF 实现步骤与流程
- 新建项目
- 导入 jar 包
- 开发函数(继承UDF,重写evaluate。用hadoop的数据类型。)
- 打成 jar 包
- 上传到 linux
- 上传到 hdfs
- 进入 hive 客户端
- 创建 UDF 函数
- 使用函数
本题参考文章:Hive的用户自定义函数UDF开发步骤详解
简述对于 UDF/UDAF/UDTF 的理解
他们的区别是什么,分别解决了什么问题?
-
UDF: 自定义函数,一进一出。类似于
year,month,day... -
UDAF: 自定义聚合函数,多进一出。类似于
avg,sum,max... -
UDTF: 自定义表生成函数,一进多出。类似于
lateral view + explode
能够让开发者针对现有场景设计不同种类的自定义函数解决问题,极大的丰富了可定制化的业务需求。
对数据进行分层作用(数仓的作用)的理解
数仓: 数据仓库是一个面向主题的、集成的、随时间变化的、但信息本身相对稳定的数据集合,用于对管理决策过程的支持。
数仓分层:
-
ODS 源数据层,顾名思义,存放源数据。
-
DW 数据仓库层,存放清洗过滤后的数据。在 DW 层中可以分为三层:
-
DWD 明细层,存放明细数据。数据来源于:ODS
-
DWM 中间层,存储中间数据,为数据统计创建中间表数据。数据来源于:DWD
-
DWS 业务层,存储宽表数据,根据实际业务对数据进行聚合。数据来源于:DWD 与 DWM
-
-
DA 数据应用层,直接调用的数据源。
作用:
-
清晰数据结构
-
数据血缘追踪
-
减少重复开发
-
屏蔽原始数据的异常
-
屏蔽业务之间的影响
Hive SQL 转化为 MR 的过程?
先说一点,Hive 并不是所有的查询都需要走 MR,如:全局查找、字段查找、过滤查询、limit 查询,都不会走 MR,直接 fetch 抓取,提高查询效率(其余的还是走 MR)。
简单叙述一个将 join 操作转为 MR 的过程:
- map 阶段生产 k,v 键值对,将 join 的连接字段作为 value,打上 tag;
- shuffle 阶段根据 key 进行排序、分组,将 k,v 一致的发送给reduce;
- reduce 阶段将相同 key 进行连接操作,识别 tag 进行 value 配对。
Hive 的存储引擎和计算引擎
存储引擎:textfile、orcfile、parquet 、rcfile、sequencefile
计算引擎:mr、spark 、tez
Hive 存储数据吗?
Hive 本身并不存储数据,只是处理数据的工具,数据都依靠 HDFS 或其它介质进行存储。
Hive 的文件存储格式都有哪些
Hive 支持多种文件存储格式,其中一些常见的包括:
文本文件格式
- TextFile:默认的文本文件格式,以行为单位进行存储。
列式存储格式
-
ORC (Optimized Row Columnar):ORC 文件是一种高效的列式存储格式,可以提供更好的压缩比和读取性能。
-
Parquet:Parquet 是另一种列式存储格式,通常与Hadoop生态系统中的其他工具(如Apache Spark)一起使用,具有很好的性能和压缩特性。
序列文件格式
- SequenceFile:序列文件是 Hadoop 的一种二进制文件格式,它可以按顺序存储键-值对。
Avro 格式
- Avro 是一种数据序列化系统,可以将数据按照其定义的架构进行序列化,并支持动态架构演化。
Hive 中如何调整 Mapper 和 Reducer 的数目
首先明白一点,map 或 reduce 数量并不是越多越好。如果有过多的小文件(大小远不够 128M),则每个小文件也会当做一个块,甚至计算时间没有 map 或 reduce 任务的启动和初始化时间,则会造成资源的浪费,reduce 过多也会导致输出的小文件过多,同样会出现效率问题。
解决方案:合并小文件,减少 map 数
可通过设置如下参数解决:
#执行 Map 前进行小文件合并
set hive.input.format=org.apache.hadoop.hive.ql.io.CombineHiveInputFormat;
#每个 Map 最大输入大小,单位为 KB
set mapred.max.split.size=128000000;
#一个节点上 split 的至少的大小,单位为 KB
set mapred.min.split.size.per.node=100000000;
#一个交换机下 split 的至少的大小,单位为 KB
set mapred.min.split.size.per.rack=100000000;

reduce 设置:
- 调整每个 reduce 可以处理的大小,hive 会进行自动推算 reduce 个数,单个任务最大
999个,可以通过hive.exec.reducers.max参数进行调整;
set hive.exec.reducers.bytes.per.reducer=500000000; (500M)
- 直接调整
reduce个数,固定。
set mapred.reduce.tasks = 15;
介绍下知道的 Hive 窗口函数,举一些例子
Hive 中的窗口函数允许在查询中执行基于窗口的计算,例如在分区内进行排序、计算累积和、计算排名等。窗口函数通常与 OVER 子句一起使用,该子句定义了窗口的大小和偏移量。
下面是一些常见的 Hive 窗口函数及其用法:
-
ROW_NUMBER():为结果集中的每一行分配一个唯一的序号。
SELECT name, score, ROW_NUMBER() OVER (ORDER BY score DESC) AS rank FROM students; -
RANK():为结果集中的每一行分配一个排名,如果有相同值,则排名相同,但跳过后面的排名。
SELECT name, score, RANK() OVER (ORDER BY score DESC) AS rank FROM students; -
DENSE_RANK():为结果集中的每一行分配一个排名,如果有相同值,则排名相同,但不会跳过后面的排名。
SELECT name, score, DENSE_RANK() OVER (ORDER BY score DESC) AS rank FROM students; -
NTILE(n):将结果集划分为 n 个等份,每个等份包含相同数量的行,并为每一行分配一个标识符,标识其所在的等份。
SELECT name, score, NTILE(4) OVER (ORDER BY score DESC) AS quartile FROM students; -
LEAD() / LAG():用于访问结果集中当前行之后或之前的行的数据。
SELECT name, score, LEAD(score, 1) OVER (ORDER BY name) AS next_score FROM students; -
SUM(), AVG(), MAX(), MIN():这些聚合函数可以与窗口函数一起使用,用于计算结果集中特定窗口的总和、平均值、最大值或最小值。
SELECT date, amount, SUM(amount) OVER (ORDER BY date) AS running_total FROM transactions;
窗口函数提供了灵活的方式来执行各种分析任务,例如排名、排序、分组等。
Hive SOL 实现查询用户连续登陆,讲讲思路
-
过滤出每个用户每天登录时间的
max值; -
通过开窗函数,以每个用户为窗口进行分区,按登录时间升序排列;
-
计算窗口内每条记录相较于前后两条记录的差值;
-
前后差值联合判断,如果差值都为
1,则说明这三天是连续登录的,反之则不连续。
Hive 的 union 和 unionall 的区别
在 Hive 中,UNION 和 UNION ALL 都是用于将两个或多个查询结果集合并在一起的操作,但它们之间有一些关键区别:
UNION
-
UNION用于将两个查询的结果集合并,并去除重复的行,确保结果中不包含重复的行。 -
UNION会执行排序和去重操作,因此可能会对性能产生一定的影响。
UNION ALL
-
UNION ALL用于将两个查询的结果集合并在一起,不进行去重操作,保留所有的行。 -
UNION ALL不执行排序和去重操作,因此通常比UNION更高效。
两者区别在于是否去除重复行。如果需要去除重复行并保留唯一值,可以使用 UNION;如果不需要去重,或者想要保留所有行,包括重复的行,则可以使用 UNION ALL。
Hive 的 join 操作原理,leftjoin、right join、inner join、outer join 的异同?
Join 操作原理
-
Map 阶段:
-
对于每个表,Map 阶段首先将其划分为若干个数据块,每个数据块由一个 Map 任务处理。
-
Map 任务会读取相应数据块,并根据连接键将数据进行哈希分区或排序,以便后续的连接操作。
-
-
Shuffle 阶段:
- 在 Map 阶段完成后,Hive 会根据连接键对两个表的数据进行分区,并将相同连接键的数据发送到同一个 Reduce 任务。
-
Reduce 阶段:
- 在 Reduce 阶段,Hive 将连接键相同的数据进行合并,并执行实际的 Join 操作。
- 对于 Inner Join,Reduce 阶段会将两个表中连接键相同的行合并在一起,生成 Join 结果。
- 对于 Left Join、Right Join 或 Full Outer Join,Reduce 阶段会处理左表和右表中连接键相同的行,并合并它们,生成 Join 结果。
-
输出阶段:
- 最后,Reduce 阶段生成的 Join 结果会被输出到 HDFS 或其他指定的存储位置,以供后续查询使用。
下面是四种连接的区别:
Left Join(左连接)
-
Left Join 返回左表(左侧表)中的所有行,以及右表(右侧表)中与左表连接键匹配的行。
-
如果右表中没有匹配的行,则结果集中右表对应的列会用 NULL 填充。
Right Join(右连接)
-
Right Join 返回右表中的所有行,以及左表中与右表连接键匹配的行。
-
如果左表中没有匹配的行,则结果集中左表对应的列会用 NULL 填充。
Inner Join(内连接)
-
Inner Join 返回两个表中共同满足连接条件的行,即两个表中连接键相匹配的行。
-
内连接只保留连接键在两个表中都存在的行。
-
如果某行在其中一个表中存在,而在另一个表中不存在,则不会包含在结果中。
Full Outer Join(全外连接)
-
Full Outer Join 返回左表和右表中所有的行,如果没有匹配的行,则用 NULL 填充对应的列。
-
结果集中包含左表和右表的所有行,即使在另一个表中找不到匹配的行。
Hive Shuffle 的具体过程
Hive 中的 Shuffle 其本质就是 MapReduce 的 Shuffle。
Map 端的 Shuffle(排序、分区)
在 Map 端,每个 MapTask 会对其输出的数据进行本地排序。排序的结果是一个有序的键值对列表,其中键为分组的条件,值为需要进行聚合的数据。
Hive 根据连接键的哈希值或排序结果,将输出数据分配到不同的分区中。每个分区对应一个 Reduce 任务。
Reduce 端的 Shuffle(传输、排序、分组聚合、输出)
MapTask 将分好组的数据传输给 ReduceTask,ReduceTask 对接收到的数据进行排序,排序的依据是 Map 端已经排好序的键值对中的 key。
ReduceTask 根据排序后的结果,将相同 key 的数据分为一组,每组数据就是一个可以进行聚合操作的数据集。
Hive 如何优化 join 操作
Hive 中的 JOIN 操作是常见的操作之一,但在大数据处理中,JOIN 操作可能会导致性能问题。为了提高 Hive 中 JOIN 操作的效率,我们可以采取以下优化措施:
-
使用更高效的JOIN类型:Hive支持多种JOIN类型,包括INNER JOIN、LEFT OUTER JOIN、RIGHT OUTER JOIN和FULL OUTER JOIN等。根据具体情况选择合适的JOIN类型可以提高效率。例如,当只需要匹配的行时,使用INNER JOIN;当需要匹配的行和左表中的所有行时,使用LEFT OUTER JOIN。
-
优化数据大小:在JOIN操作中,如果参与JOIN的表很大,会导致性能问题。为了减少数据大小,可以使用过滤条件减少参与JOIN的行数。此外,可以使用分区、过滤器和索引等Hive特性来进一步优化数据大小。
-
使用更快的文件格式:Hive支持多种文件格式,包括TextFile、SequenceFile、ORC和Parquet等。为了提高JOIN操作的效率,可以使用Parquet或ORC等列式存储格式。这些格式将数据按列存储,使得JOIN操作更加高效。
-
使用压缩:数据压缩可以减少磁盘I/O和网络带宽的使用,从而提高JOIN操作的效率。Hive支持多种压缩算法,包括Snappy和Zlib等。为了提高性能,可以在写入文件时使用压缩,并在需要读取文件时解压缩。
-
优化缓冲区大小:Hive使用Java堆来存储数据,因此可以通过调整堆大小来优化性能。增加堆大小可以使得更多的数据可以存储在内存中,从而提高JOIN操作的效率。但是,需要注意的是,增加堆大小也会增加垃圾回收的开销。
-
使用Bucketed Join:如果参与JOIN的表已经按照相同的列进行了分桶,那么可以使用Bucketed Join来提高效率。Bucketed Join将小表加载到内存中,然后与大表进行匹配,从而减少磁盘I/O操作。
-
优化查询计划:查询计划是Hive执行查询的蓝图。通过查看查询计划,可以了解查询的执行方式并找到优化的机会。可以使用EXPLAIN命令来查看查询计划。
-
避免使用全表扫描:全表扫描会扫描整个表并产生大量的磁盘I/O操作,从而降低性能。为了减少全表扫描的使用,可以使用过滤条件来减少参与操作的行数。
-
使用更快的算法:Hive提供了多种算法来执行JOIN操作,包括Map Join和Sort Merge Join等。根据具体情况选择合适的算法可以提高效率。例如,当小表足够小可以加载到内存中时,使用Map Join;当小表太大无法加载到内存中时,使用Sort Merge Join。
-
调整Hive配置参数:Hive配置参数可以影响性能。通过调整参数,可以优化JOIN操作的效率。例如,增加缓存的大小可以提高缓存中数据的访问速度;增加线程数可以并行处理更多的任务等。
参考文章 —— Hive中的JOIN操作优化
Hive 中的 MapJoin
Join 操作在 Map 阶段完成,如果需要的数据在 Map 的过程中可以访问到则不再需要 Reduce。
小表关联一个超大表时,容易发生数据倾斜,可以用 MapJoin 把小表全部加载到内存在 map 端进行 join,避免 reducer 处理。
通过如下参数进行设置:
--是否开自动 MapJoin
set hive.auto.convert.join = true;
--MapJoin 的表size大小,默认25m。
set hive.mapjoin.smalltable.filesize;
Hive 的执行顺序
from … on … join … where … group by … having … select … distinct … order by … limit
Hive 使用的时候会将数据同步到 HDFS,小文件问题怎么解决的?
Hive 在进行增量导入或者动态分区的时候往往都有可能会产生大量的小文件。
我们可以采用如下这种策略:
insert overwrite tb_name select * from tb_name distribute by floor(rand()*5)
将 reduce 的个数控制在 5 个以内,根据实际业务场景来,这样就可以有效的减少小文件的数量。
Hive 有哪些保存元数据的方式,都有什么特点?
-
内嵌模式:将元数据保存在本地内嵌的 derby 数据库中,内嵌的 derby 数据库每次只能访问一个数据文件,也就意味着它不支持多会话连接。
-
本地模式:将元数据保存在本地独立的数据库中(一般是 mysql),这可以支持多会话连接。
-
远程模式:把元数据保存在远程独立的 mysql 数据库中,避免每个客户端都去安装mysql数据库。
特点:
-
内存数据库 derby,安装小,但是数据存在内存,并且数据存储目录不固定,不适合多用户操作。
-
mysql 数据库,数据存储模式可以自己设置,持久化好,查看方便。
本题参考文章:Hive元数据存储的三种模式,hive有哪些保存元数据的方式,各有什么特点。
Hive count(distinct) 有几个 reduce,海量数据会有什么问题?
count(distinct) 只会产生一个 reduce,即使你设置的 reduce 数量比它大。
后果:
在海量数据时会产生严重的数据倾斜。
解决方法:
在海量数据面前一般使用 count + group by 来进行统计,如果数据量不是很大,则可以直接使用 count(distinct) 的方式来进行统计。
了解 Hive SQL 吗?讲讲分析函数?
-
聚合函数。比如:sum(…)、 max(…)、min(…)、avg(…)等
-
数据排序函数。比如 :rank(…)、row_number(…)等
-
统计和比较函数。比如:lead(…)、lag(…)、 first_value(…)等
说说 over partition by 与 group by 的区别
group by 会改变数据的行数,返回分组之后的数据结果,而partition by是数据原本多少行,分区之后仍有多少行。
分析函数中加 Order By 和不加 Order By 的区别?
当为排序函数,如:row_number(),rank() 等时,over 中的 order by 只起到窗口内排序作用。
当为聚合函数,如:max(),min(),count() 等时,over 中的 order by 不仅起到窗口内排序,还起到窗口内累加的功能。
示例:
-- 不加 order by
select spu_id,sum(price) over(partition by spu_id) from sku_info;
-- 加 order by
select spu_id,sum(price) over(partition by spu_id order by id) from sku_info;
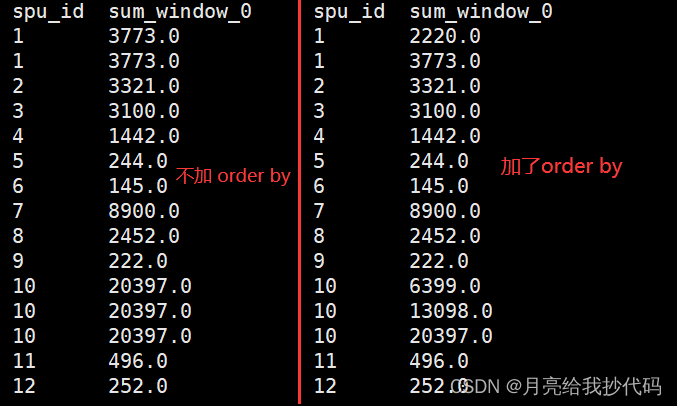
从结果中可以看出,在窗口中如果进行聚合函数的操作,加了 order by 会添加一个限定范围,当前分区内的第一行到当前行。
Hive 中 Metastore 服务作用
客户端连接 metastore 服务,metastore 再去连接 MySQL 数据库来存取元数据。有了 metastore 服务,就可以有多个客户端同时连接,而且这些客户端不需要知道 MySQL 数据库的用户名和密码,只需要连接 metastore 服务即可。
本题参考文章:Hive Metastore服务
HiveServer2 是什么?
HiveServer2 是一个服务接口,能够允许远程的客户端去执行 SQL 请求且得到检索结果。
Hive 表字段换类型怎么办
- 没有数据,直接修改
alter table 表名 change column 原字段名 新字段名 字段类型;
- 有数据
先使用 like 创建一个与原表结构一样的新表,然后修改新表的字段类型,导入原表数据到新表,删除原表。
Parquet 文件优势
Parquet 文件以二进制方式存储,不可以直接读取和修改,Parquet 文件是自解析的,文件中包括该文件的数据和元数据。
Parquet 可以使用较少的存储空间表示复杂的嵌套格式,可以通过 RLE 算法对其进行压缩,进一步降低存储空间;
HQL:行转列、列转行
列转行
在 Hive 中列转行有两个函数:
collect_list:collect_list(col)
collect_set:collect_set(col),会对聚合的结果进行去重。
示例:
在 Hive 中创建了如下数据表:
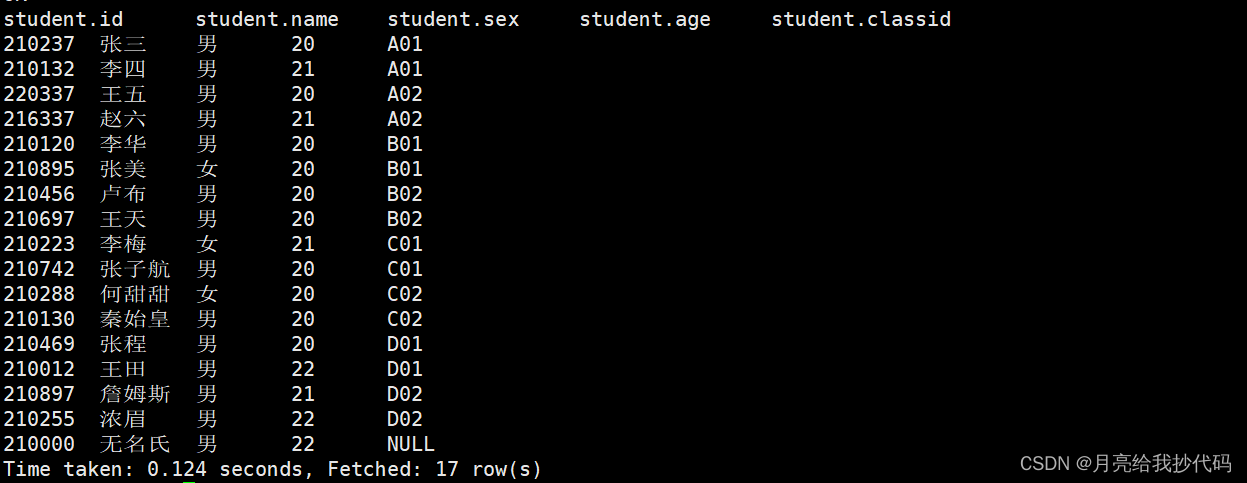
需求:将各班的学生姓名在一行中显示输出。
select classid,collect_list(name) names from student group by classid;
输出结果:

行转列
在 Hive 中行转列分为几个步骤,先用 explode(array | map) 对行数据转换为列数据,然后再通过 lateral view ... 创建临时视图表(侧视图)进行输出。
示例:
在 Hive 中创建了一张电影表,如下所示:

通过该表,我们先来看一下 explode 的用法:
select explode(split(category,",")) from movies;
输出结果:
爱情
动作
虚幻
情感
在实际应用中行转列一般会配合 lateral view 一起使用。
需求:根据电影表中的类型,通过逗号进行分割转换为行,最终输出如下。
怦然心动 爱情
怦然心动 动作
楚门的世界 虚幻
楚门的世界 情感
select m.name,tmp.category from movies m lateral view explode(split(category,",")) tmp as category;
解析:
select
m.name,
tmp.category
from
movies m
lateral view
explode(split(category,",")) tmp as category;
# tmp 表示侧视图的名称
# category 表示侧视图的字段名称
最终输出结果如下:


















 1751
1751











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











