









一、排序算法
排序(SortAlgorithm):排序算法,将一组数据依照指定的顺序进行排列的过程。
排序的分类:
- 内部排序:将需要处理的所有数据加载到内部存储中进行排序。
- 插入排序:包括直接插入排序,希尔排序等。
- 选择排序:包括简单选择排序,堆排序等。
- 交换排序:包括冒泡排序,快速排序等。
- 归并排序:
- 基数排序:
- 外部排序:数据量过大,无法全部加载到内存中,需要借助外部存储进行排序。
度量一个程序执行时间的两种方法:
- 事后统计:想要对设计的算法的运行性能进行评测,需要实际运行该程序,其所得的时间统计量是基于计算机的硬件,软件环境的等因素。
- 事前估算:通过分析某个算法的时间复杂度来判断哪个算法更优。
1. 算法的时间复杂度
时间频度:一个算法花费的时间与算法中语句的执行次数成正比,哪个算法在语句执行次数多,其所花费的时间就多。一个算法的语句执行次数称为语句频度或者时间频度。可以忽略
时间复杂度:一般情况下,算法的基本操作语句的重复执行次数是问题规模 n 的某个函数,用 T(n) 表示,若有某个辅助函数 f(n) ,使得当 n 趋近于无穷大时,T(n) / f(n) 的极限值为不为 0 的常数值,则称 f(n) 是 T(n) 的同数量级函数,记作 T(n) = O( f(n) ),称 O( f(n) ) 为算法的渐进时间复杂度,简称时间复杂度。
计算时间复杂度的方法:
- 使用常数 1 代替运行时间中所有加法常数。
- 修改后的运行次数函数中,只保留最高阶项。
- 取出最高阶项的系数。
常见的时间复杂度:
- 常数阶:O(1)
- 对数阶:O(log2 n)
- 线性阶:O(n)
- 线性对数阶:O(n log2 n)
- 平方阶:O(n^2)
- 立方阶:O(n^3)
- 次方阶:O(n^k)
- 指数阶:O(2^n)
2. 冒泡排序
冒泡排序( Bubble Sorting ):通过对待排序序列从前到后,从下标较小的元素开始,一次比较相邻元素的值。如果发现逆序就交换位置,就像水底的气泡一样向上冒。因为在排序过程中,各个元素不断接近自己的位置,如果一次比较下来没有进行过交换,就说明序列有序。因此在排序过程中需要设置一个标志来判断是否发生交换,从而减少不必要的比较。
简单示例:
//冒泡排序
public static void bubble(int[] arr){
boolean flag = false;
for (int i = 0; i <arr.length-1; i++) {
for (int j = 0; j < arr.length -1 - i; j++) {
if (arr[j]>arr[j+1]){
//交换
flag=true;
arr[j] = arr[j]+arr[j+1];
arr[j+1] = arr[j]-arr[j+1];
arr[j] = arr[j]-arr[j+1];
}
}
if (!flag){
break; //在一次排序中未发生交换,说明排序完成。
}else {
flag=false; //重置,进行下一次交换。
}
}
//System.out.println(Arrays.toString(arr));
}
3. 选择排序
选择排序:是从预排序的数据中,按照指定的规则选出某一元素,再依照规定交换位置后达到排序的目的。
选择排序思想:先从所有的数据中找出最小值,与下标为 0 的元素交换,再从剩下的元素找出最小的,与下标为 1 的元素交换,以此类推。
简单示例:
//选择排序
public static void select(int[] arr){
for (int i = 0; i < arr.length - 1; i++) {
int temp=arr[i];
for (int j = i; j < arr.length; j++) {
if (arr[j]<temp){
temp=temp^arr[j];
arr[j]=temp^arr[j];
temp=temp^arr[j];
}
}
arr[i] = temp;
}
}
4. 插入排序
插入排序思想:把 n 个待排序的元素看成为一个有序表和一个无需表,开始时有序表只包含一个元素,剩下的都在无序表中,排序过程中每次从无序表中取出一个元素,把它插入到有序标中的对应位置,使之成为新的有序表,直到无序表中元素为空。
简单示例:
//插入排序
public static void insertSort(int[] arr){
for (int i = 1; i < arr.length; i++) {
//定义一个待插入的数
int insertVal = arr[i];
int insertIndex = i-1; //即arr[i]这个数前面的数
//给 insertVal 找到插入的位置。
while (insertIndex >=0 && insertVal < arr[insertIndex]){
//需要将 arr[insertIndex] 后移,为插入的元素腾出位置
arr[insertIndex+1] = arr[insertIndex];
insertIndex--;
}
//当推出while循环时,说明找到了插入的位置。
arr[insertIndex+1] = insertVal;
}
}
存在的问题:当需要插入的数是较小的数时,后移的次数明显增多,对效率有影响。
5. 希尔排序
希尔排序:也叫做缩小增量排序。希尔排序也是一种插入排序,他是简单插入排序经过改进后的一个更高效的版本。
希尔排序法的基本思想:把记录下标的一定增量分组,对每组使用直接插入排序算法排序,随着增量逐渐减少,每组包含的关键词越来越多,当增量减至 1 时,整个文件恰好被分成一组,算法结束。
希尔排序交换法:速度并不快
//希尔排序,插入时使用交换法
public static void shellSort(int[] arr) {
for (int gap = arr.length / 2; gap > 0; gap /= 2) {
//把10个数据分为 gap 组
for (int i = gap; i < arr.length; i++) {
//遍历各组中的所有元素,步长为gap
for (int j = i - gap; j >= 0; j -= gap) {
//若果当前元素大于加上步长后的元素,则交换之
if (arr[j] > arr[j + gap]) {
//交换之
arr[j] = arr[j] ^ arr[j + gap];
arr[j + gap] = arr[j] ^ arr[j + gap];
arr[j] = arr[j] ^ arr[j + gap];
}
}
}
}
}
希尔排序插入法:速度有显著提升
//希尔排序,移位法
public static void shellSort2(int[] arr){
for (int gap = arr.length / 2; gap > 0; gap /= 2) {
//从第 gap 个元素,逐个对其所在的组进行简单插入排序
for (int i = gap; i < arr.length; i++) {
int j = i;
int temp = arr[j];
if (arr[j] < arr[j-gap]){
while (j - gap >= 0 && temp < arr[j-gap] ){
//移动
arr[j] = arr[j-gap];
j -= gap;
}
//退出循环,找到插入位置
arr[j] = temp;
}
}
}
}
6. 快速排序
快速排序(QuickSort):是对冒泡排序的一种改进。
基本思想:通过一趟排序将要排序的数据分割成独立的两部分,其中一部分的所有数据要比另一部分的所有数据要小,然后再按照此方法多这两部分数据分别进行快速排序,整个排序过程可以递归进行,以此达到将整个数据变为有序。
简单示例:
//快速排序
public static void quickSort(int[] arr, int left, int right) {
int l = left;
int r = right;
//pivot 中轴
int pivot = arr[(l + r) / 2];
//将比pivot小的值放在左边,大的放在右边。即从下到大排序
while (l < r){
//在pivot左边找到一个不小于pivot的值,才退出
while (arr[l] < pivot){
l += 1;
}
//在pivot左边找到一个不大于pivot的值,才退出
while (arr[r] > pivot){
r -= 1;
}
//到此说明左边的值全部小于pivot,右边的值全部大于pivot
if (l >= r){
break;
}
//交换
arr[r]=arr[r]^arr[l];
arr[l]=arr[r]^arr[l];
arr[r]=arr[r]^arr[l];
//当左右两边
//如果交换完成,发现arr[r]==pivot,l++ ,后移
if (arr[r] == pivot){
r -= 1;
}
//如果交换完成,发现arr[l]==pivot,r++ ,前移
if (arr[l] == pivot){
r += 1;
}
}
//如果 l==r ,必须l++,r--,否则会出现栈溢出,因为循环无法退出
if ( l == r){
l += 1;
r -= 1;
}
//向左递归
if(left < r){
quickSort(arr,left,r);
}
//向右递归
if(right > l){
quickSort(arr,l,right);
}
}
7. 归并排序
归并排序(MergeSort):利用归并思想实现的排序方法,该算法采用了经典的分治( divide and conquer )策略。
分治:将问题分为一些小的问题,然后递归求解,而治的阶段是将分的阶段得到的个答案修补在一起,即分而治之。
简单示例:使用归并算法必须提供一个容量不小于原始数组的 temp 数组用以存放排好序的数据。
//归并排序的分解
public static void mergeSort(int[] arr,int left,int right,int[] temp){
//分解
if (left < right){
int mid = (left + right) / 2; //中间索引
//向左递归进行分解
mergeSort(arr,left,mid,temp);
//向右递归进行分解
mergeSort(arr,mid+1,right,temp);
//合并
merge(arr,left,mid,right,temp);
}
}
//归并排序的合并
public static void merge(int[] arr,int left,int mid,int right,int[] temp){
int i = left; //初始化 i,左边有序序列的初始索引
int j = mid+1; //初始化 j,右边有序序列的初始索引
int t = 0; //指向temp数组的当前索引
//先让左右两边有序的数据按照规则填充到temp数组。直到其中一个数组处理完毕
while (i <= mid && j <= right){
if (arr[i] <= arr[j]){
//左边数组当前元素小于或者等于右边数组当前元素。
temp[t] = arr[i]; //将左边数组当前元素放入 temp 数组
t += 1; //后移
i += 1; //后移
}else {
//反之,左边边数组当前元素大于右边数组当前元素。
temp[t] = arr[j]; //将右边数组当前元素放入 temp 数组
t += 1; //后移
j += 1; //后移
}
}
//把另一个数组依次填充到temp数组。
while (i <= mid){
temp[t] = arr[i]; //将左边数组当前元素放入 temp 数组
t += 1; //后移
i += 1; //后移
}
while (j <= right){
temp[t] = arr[j]; //将右边数组当前元素放入 temp 数组
t += 1; //后移
j += 1; //后移
}
//将temp数组拷贝到arr,并不是每次都拷贝所有数据
t = 0;
int tempLeft = left;
while (tempLeft <= right){
arr[tempLeft] = temp[t];
t += 1;
tempLeft += 1;
}
}
8. 基数排序
基数排序( Radix Sort):属于分配式排序( distribution sort ),又称**桶子法( bucket sort)**或者 bin sort 。它是通过建值的各个位的值,将要排序的元素分配至某些桶中,达到排序的作用。
- 基数排序法是属于稳定性的排序,是效率高的稳定性排序法。
- 基数排序法是桶排序的拓展。
- 它是这样实现的:将整数按位数切分成不同的数字,然后按照每个位数分别比较。
基数排序的基本思想:将所有待比较数值统一位同样的数位长度,数位较短的在前面补 0 ,让后从最低位开始,依次进行比较,这样从最低位到最高位排序完成后,数列就成了一个有序序列。
注意事项:基数排序会消耗大量的内存,但其速度很快,是典型的使用空间换时间的算法。因为需要创建很多桶,且每个桶的大小和数据量的大小基本一致。当海量数据进行排序时,有可能出现 OutOfMemoryError 错误。
简单示例:此方法不能正确的排序负数。
//基数排序
public static void radixSort(int[] arr){
//找出最大数的位数
int max = arr[0];
for (int i = 0; i < arr.length; i++) {
if (arr[i] > max){
max = arr[i];
}
}
int maxLength = (max+"").length();
//定义一个二维数组,表示 “桶”
//为了防止放入数时溢出,每个桶的大小必须能够承载所有数据。
int[][] bucket = new int[10][arr.length];
//需要记录每个桶中实际存放了多少数据。即数据的下标
int[] bucketCount = new int[10];
for (int k = 0,n = 1; k < maxLength; k++,n *= 10) {
for (int i = 0; i < arr.length; i++) {
//取出元素的n位数
int digitOfElement = arr[i] / n % 10;
//放入对应的桶中的对应位置
//bucketCount[digitOfElement] : 对应桶的对应下标。
bucket[digitOfElement][bucketCount[digitOfElement]] = arr[i];
bucketCount[digitOfElement]++;
}
//按顺序取出所有的数据,并放入原数组
int index = 0; //原数组的辅助下标
//遍历每一个桶,并将桶中的数据放入原数组
for (int i = 0; i < bucketCount.length; i++) {
//如果桶中有数据,才放入数组
if (bucketCount[i] != 0){
//循环该桶
for (int j = 0; j < bucketCount[i]; j++) {
//取出元素,放入数组
arr[index++] = bucket[i][j];
//index++;
}
}
//每一轮处理完成,需要将每个桶的指针置 0。即下一轮的数据从0开始存放。
bucketCount[i] = 0;
}
//System.out.println(Arrays.toString(arr));
}
}
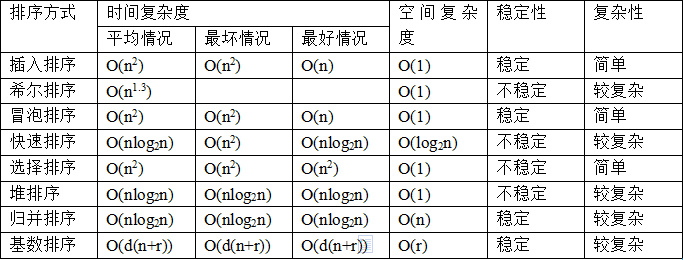
9 基本算法的时间复杂度
二、查找算法
1. 顺序查找
顺序查找:也叫线性查找,类似遍历。
简单示例:查找某元素的下标,只找第一个。
//顺序查找
public static int seqSearch(int[] arr,int value){
//线性查找即逐一比对
for (int i = 0; i < arr.length; i++) {
if (arr[i] == value){
return i;
}
}
return -1;
}
2. 二分查找
二分查找:只能查找有序数列。通过和中间的值对比确定要查找的数在那个区间,通过递归不断分解数列,最终找到或者结束查找。
二分查找基本思路:
- 先确定中间值所在的位置,将要查找的值与之对比。
- 查找值大于中间值,向大的区间查找,反之亦然。
- 直到查找值等于中间值,说明找到,区间为负,说明未找到。
简单示例:设查找的数列按照从小到大排序。可以找到重复值。
//二分查找法
public static ArrayList<Integer> binarySearch(int[] arr, int value, int left, int right){
if (left > right){
return new ArrayList<Integer>();
}
int mid = (left + right) / 2;
int midVal = arr[mid];
if (value > midVal){ //向右递归
return binarySearch(arr,value,mid + 1,right);
}else if (value < midVal){ //向左递归
return binarySearch(arr,value,left,mid - 1);
}else {
ArrayList<Integer> indexList = new ArrayList<>();
//先将找打的下标放进数组
indexList.add(mid);
//向找到的值的左边扫描
int temp = mid - 1;
while (true){
if (temp < 0 || arr[temp] != value) {
break;
}
indexList.add(temp);
temp -= 1; //左移
}
//向找到的值的右边扫描
temp = mid + 1;
while (true){
if (temp > arr.length -1 || arr[temp] != value) {
break;
}
indexList.add(temp);
temp += 1; //右移
}
return indexList;
}
}
3. 插值查找
差值查找:插值查找的算法类似于二分查找,不同的是插值查找每次是从自适应的 mid 出查找。
其中 mid 的值为:left + (right - left) * (value - arr[left]) / (arr[right] - arr[left])
注意事项:
- 对于数据量较大,关键字分布比较均匀的查找表来说,采用插值查找,速度较快。
- 关键字分布不均,插值查找不一定比折半查找法要快。
//插值查找法
public static int insertValueSearch(int[] arr, int value, int left, int right){
//查找完成
//value < arr[0] || value > arr[arr.length - 1] 还可以防止 mid 越界。
if (left > right || value < arr[0] || value > arr[arr.length - 1]){
return -1;
}
int mid = left + (right - left) * (value - arr[left]) / (arr[right] - arr[left]);
int midVal = arr[mid];
if (value > midVal){ //向右递归
return insertValueSearch(arr,value,mid + 1,right);
}else if (value < midVal){ //向左递归
return insertValueSearch(arr,value,left,mid - 1);
}else{
return mid;
}
}
4. 斐波那契查找
斐波那契(黄金分割)查找:
黄金分割:把一个线段分成两部分呢,是其中一部分与整体的比等于另一部分与此部分的比,近似值为 0.618 。
斐波那契数列:{ 1, 1, 2, 3, 5, 8, 13, 21, 34, 55...},该数列相邻两个数之比无限接近黄金分割值,且第 i 个数的值为 第 i - 1 个和第 i - 2 个数之和。
斐波那契查找基本思想:其查找原理和二分及差值类似,只是改变了 mid 的值位于黄金分割点附近。
其中 mid 的值为:mid = left + F(k - 1) - 1,F 代表斐波那契数列。F[k] = F[k-1] + F[k-2]。
注意事项:由于原始的顺序表不一定满足黄金分割的条件,所以需要将其扩容称可以分割的顺序表即可。
简单示例:
//public static int maxSize = 20;
//获取一个斐波那契数列
public static int[] fibonacci(int maxSize){
int fib[] = new int[maxSize];
fib[0] = 1;
fib[1] = 1;
for (int i = 2; i < fib.length -1; i++) {
fib[i] = fib[i-1] + fib[i-2];
}
return fib;
}
//斐波那契查找算法
public static int fibonacciSearch(int[] arr,int value){
int left = 0;
int right = arr.length - 1;
int k = 0; //斐波那契分割数值的下标,即黄金分割点
int mid = 0; //存放 mid 值
int[] f = fibonacci(20);
//获取斐波那契分割值的下标
while (right > f[k] - 1){
k++;
}
//扩充数组,不足的部分使用 0 补齐。因为发 f[k] 可能大于 arr 的长度。
int[] temp = Arrays.copyOf(arr,f[k]);
//对新的数组0,的部分使用最大值补全,使其有序。
for (int i = right + 1; i < temp.length; i++) {
temp[i] = arr[right];
}
//查找
while (left <= right){
mid = left + f[k-1] - 1;
if (value < temp[mid]){ //向左查找
right = mid - 1;
k--;
}else if (value > temp[mid]){
left = mid + 1;
k -= 2;
}else {
//确定返回的是哪个小标
if (mid <= right){
return mid;
}else {
return right;
}
}
}
return -1;
}
















 4659
4659











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











