







ES 作为一个分布式搜索引擎,从扩展能力和搜索特性上而言无出其右,然而它有自身的弱势存在,其作为近实时存储系统,由于其分片和复制的设计原理,也使其在数据延迟和一致性方面都是无法和 OLTP(Online Transaction Processing)系统相媲美的。
也正因如此,通常它的数据都来源于其他存储系统同步而来,做二次过滤和分析的。这就引入了一个关键节点,即 ES 数据的同步写入方式,本文介绍的则是 MySQL 同步 ES 方式。
将 MySQL 数据写入 ES,首先想到的一定是消费 Binlog 直连 ES 写入,这种方式简单明了,然而如果稍微考量维度多一点,就会发现该方式的一些弊端。因此还有另外一个方式,即【RocketMQ + Flink Consumer + ES Bulk】集成生态,我们将从同步延迟、消费特性,ES 写入性能、系统容灾能力四个方面评估这两种接入方式,希望给到大家灵感并选择适合业务的同步方式。
ES 基础写入原理
ES 写入属于追加式写入,先形成特定大小的 Segment,然后定时 Merge 小数据段为大数据段以减少内存碎片,提升查询效率的过程。一个 Index 由 N 个 Shard 及其副本构成,存储了同一种 Type 类型的 Documents,由 Mapping 定义了其索引方式,每一个 Shard 由 N 个 Segment 组成,每个 Shard 都是一个全功能且完整的 Lucene 索引,它是 ES 的最小处理单元;Segment 是 ES 最小的数据处理单位,每个 Segment 都是一个独立的倒排索引。
ES 写入其实是不断将数据写入到同一个 Segment(内存),然后触发 Refresh 刷新,将 Segment 刷新到 OS Cache(默认 1s),此时数据就可以查询到了,OS Cache 会由操作系统触发 Flush 操作持久化到磁盘。
引发思考:ES 是如何保证数据不丢失的呢?追加式写入的优劣点是什么?追加式写入是如何处理数据更新问题的?MySQL 是属于哪种写入方式呢?本文重点不在此处,大家可以另行查阅文章。

ES 基本概念
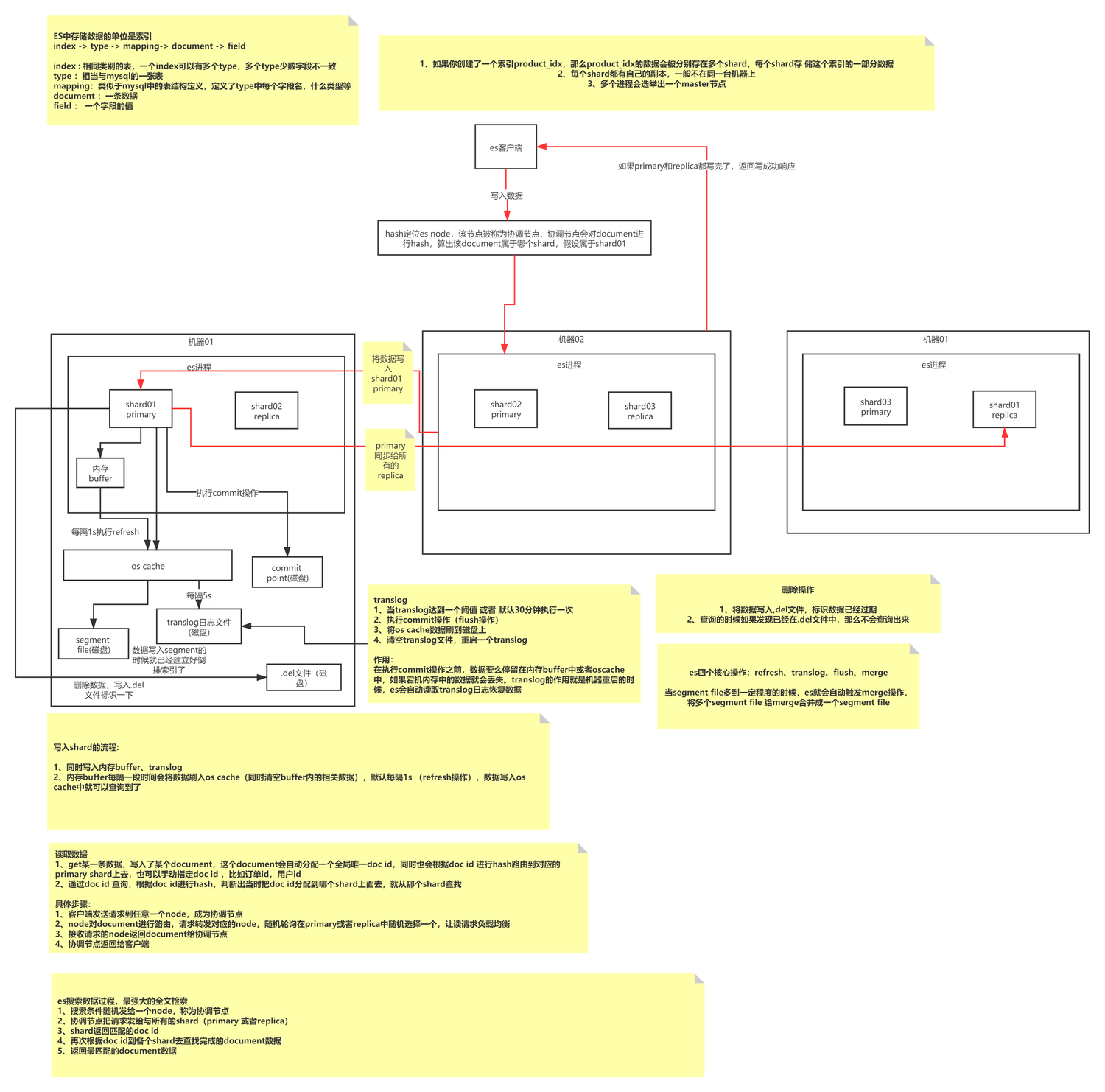
ES 写入过程
ES 直连写入

采用 ES 直连写入的优点是因为路径短,依赖组件少,加上 Dsyncer(异构存储转换系统)通常已经提供了完善的限流重试机制,所以消费延迟和消费的数据完整性都是可以保证的。
缺点:
-
不易于接入多机房容灾部署,目前 ES 容灾机房都属于独立部署,独立读写模式,所以如果采用该方式,则难以同时对多机房写入分别做管控,达不到容灾效果。Binlog-->Dsyncer 通常一个 MySQL Table 对应一个转换任务,如果为了写多机房起多个重复的转换任务,则显得有些愚笨。
-
如果自身业务场景有对同一条记录并发写场景,但写不一定全部来源于 Binlog 的情况下,那全局考虑直写 ES 则更容易遇到写入冲突问题,因为缺乏有序队列的保障。
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章



















 6569
6569

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











