







摘要:本文整理自字节跳动基础架构工程师魏中佳在本次 CommunityOverCode Asia 2023 中的《字节跳动 MapReduce - Spark 平滑迁移实践》主题演讲。
随着字节业务的发展,公司内部每天线上约运行 100万+ Spark 作业,与之相对比的是,线上每天依然约有两万到三万个 MapReduce 任务,从大数据研发和用户角度来看,MapReduce 引擎的运维和使用也都存在着一系列问题。在此背景下,字节跳动 Batch 团队设计并实现了一套 MapReduce 任务平滑迁移 Spark 的方案,该方案使用户仅需对存量作业增加少量的参数或环境变量即可完成从 MapReduce 到 Spark 的平缓迁移,大大降低了迁移成本,并且取得了不错的成本收益。
背景介绍
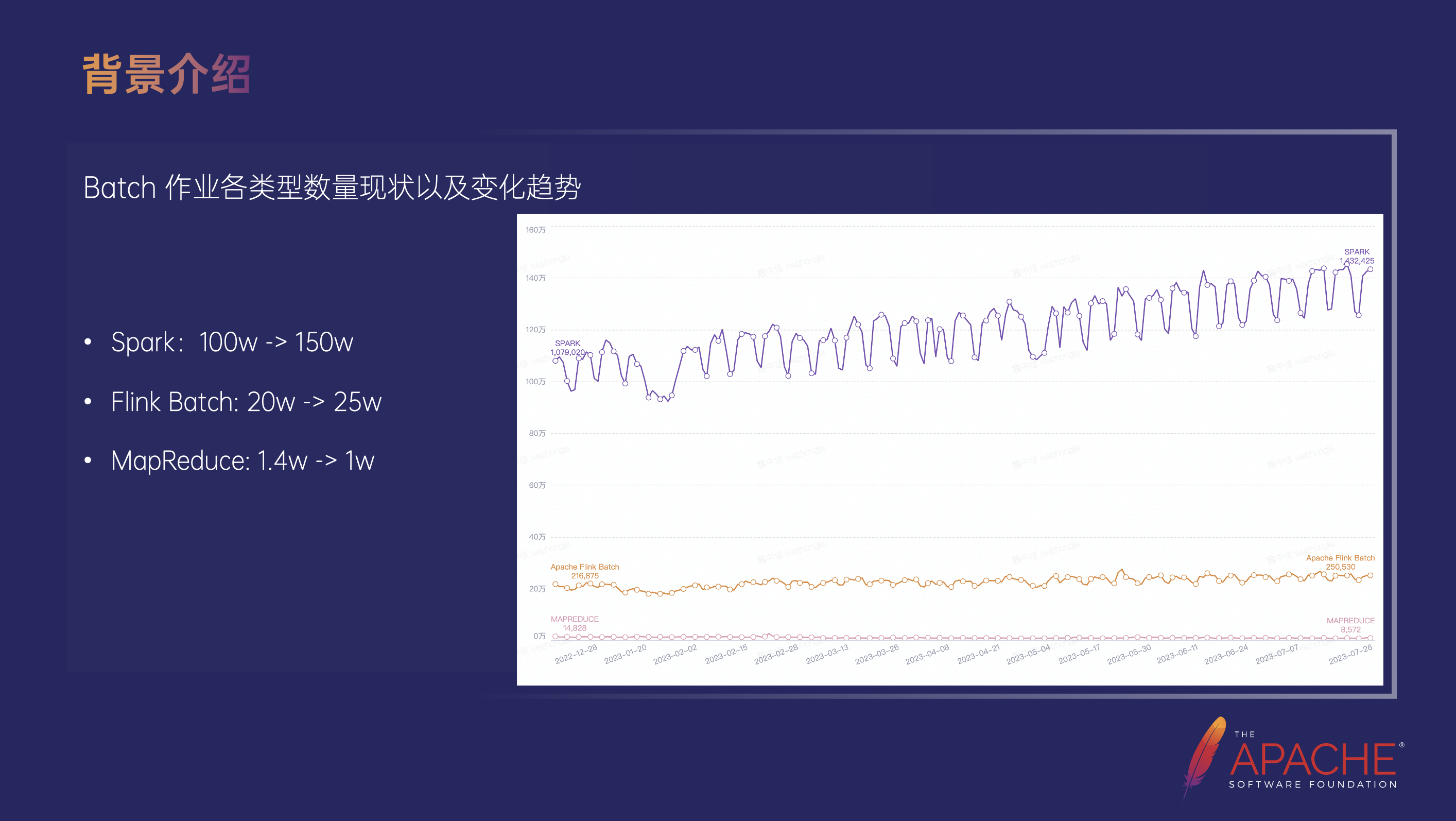
近一年内字节跳动 Spark 作业数量经历了从 100 万到 150 万的暴涨,天级数据 Flink Batch 从 20 万涨到了 25 万,而 MapReduce 的用量则处于缓慢下降的状态,一年的时间差不多从 1.4 万降到了 1 万左右,基于以上的用量情况,MapReduce 作为我们使用的历史悠久的批处理框架也完成了它的历史使命即将下线。
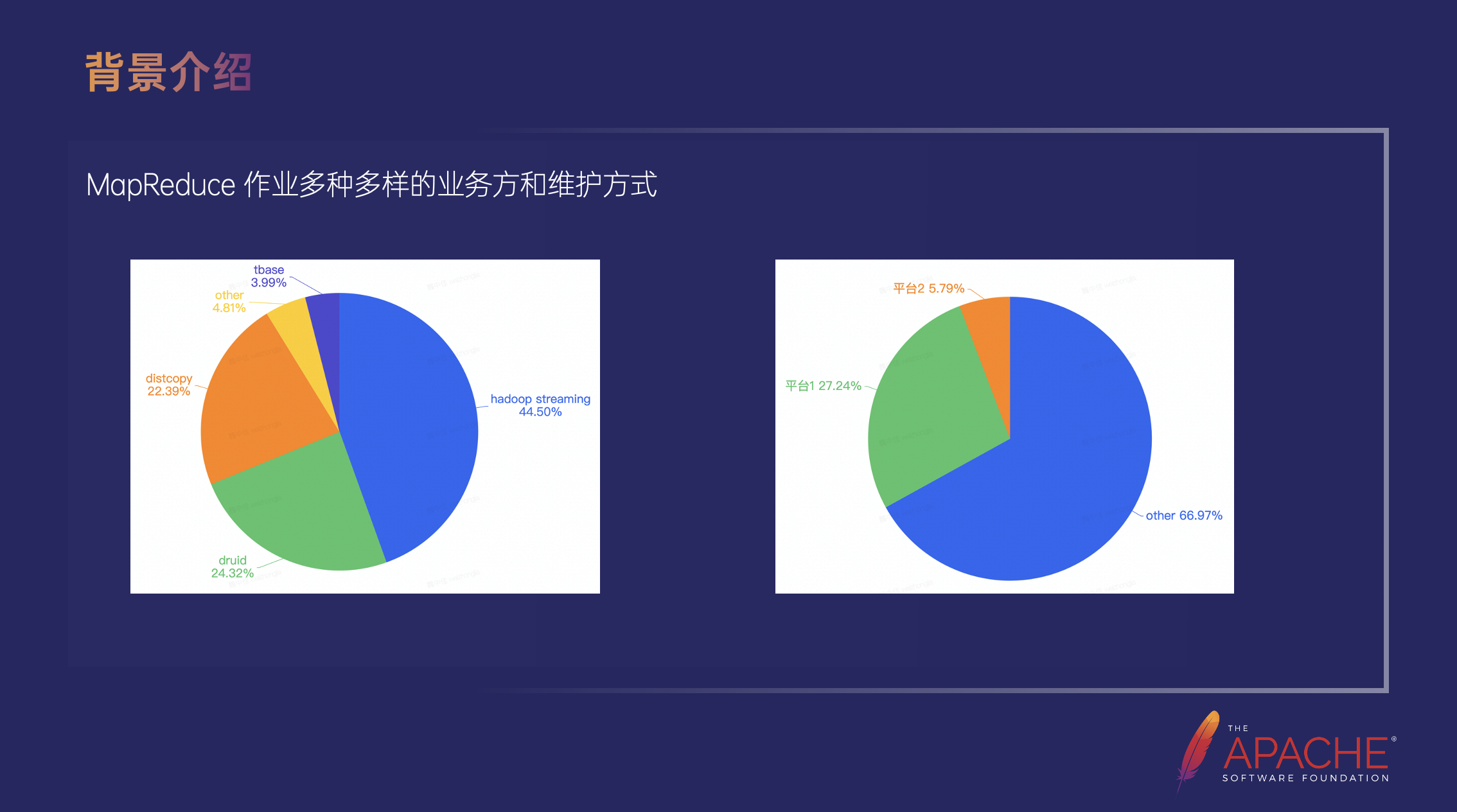
在正式推动下线之前,我们首先统计了 MapReduce 类型作业的业务方和任务维护方式。
左边的饼图是业务方的占比统计,占比最大的是 Hadoop Streaming 作业,差不多占到了所有作业的 45%,占比第二名的是 Druid 作业 24%,第三是 Distcopy 22%。这里的 Distcopy 和 Hadoop Streaming 没有按照业务线来分的原因是因为这两种类型的作业使用的是完全相同的代码,在我们推动升级的过程中可以视为相同的作业。
右边的饼图是维护方式的占比统计,占比最大的是 Others,占比高达 60%,Others 的意思是不被字节跳动内部任何一个平台管理的作业,这也非常符合 MapReduce 的特定,它是一个历史悠久的框架,很多的 MapReduce 作业在第一次上线的时候,甚至这些平台还没有出现,大部分都是从用户自己管理的容器或者可以连接到 YARN 集群的物理机上直接提交的。
为什么要推动 MapReduce 迁移 Spark
推动 MapReduce 下线有以下三个原因:
第一个原因是 MapReduce 的运行模式对计算调度引擎吞吐的要求过高。MapReduce 的运行模式中每一个 Task 对应一个 Container ,当 Task 运行结束后,就会释放 Container ,这种运行模式对于 YARN 来说是没有问题的,因为 YARN 的吞吐非常高。但是随着我们内部业务从 YARN 迁移到 K8s 集群的时候发现,MapReduce 作业经常会触发 API Server 报警,影响 K8s 集群的稳定性,一个 MapReduce 任务跑完经常需要申请 10w 个以上的 POD;而同样规模的 Spark 作业可能仅需要几千个 POD,因为 Spark 作业内部还有一层调度,Spark 申请到的 Container 作为 Executor 不会在跑完一个 Task 后推出,而是由 Spark 框架调度新的 Task 上来继续使用。
第二个原因是 MapReduce 的 Shuffle 性能非常差。内部使用的 MapReduce 是基于社区的2.6版本,它的 Shuffle 实现依赖的 Netty 框架大概是十年前的版本,与当前的 Netty 相比差了一个大版本,在实际使用中也会发现它的性能比较差,而且也会在物理机创建过多的连接,影响物理机的稳定性。
第三个原因是从开发工程师的角度考虑,我们内部有很多横向改造的项目,比如刚刚提到的 K8s 的改造,还有 IPV6 适配,改造成本跟 Spark 其实是一样的,但是 MapReduce 的
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章



















 1279
1279

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











