






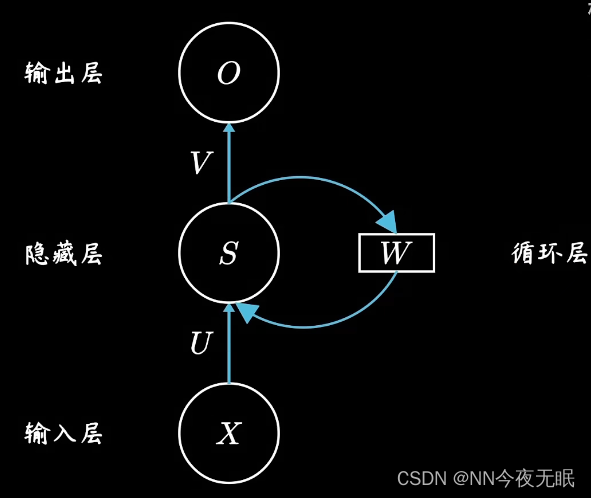
RNN
DNN深度神经网络水平方向延伸,不考虑单个隐层在时间时序上的变化
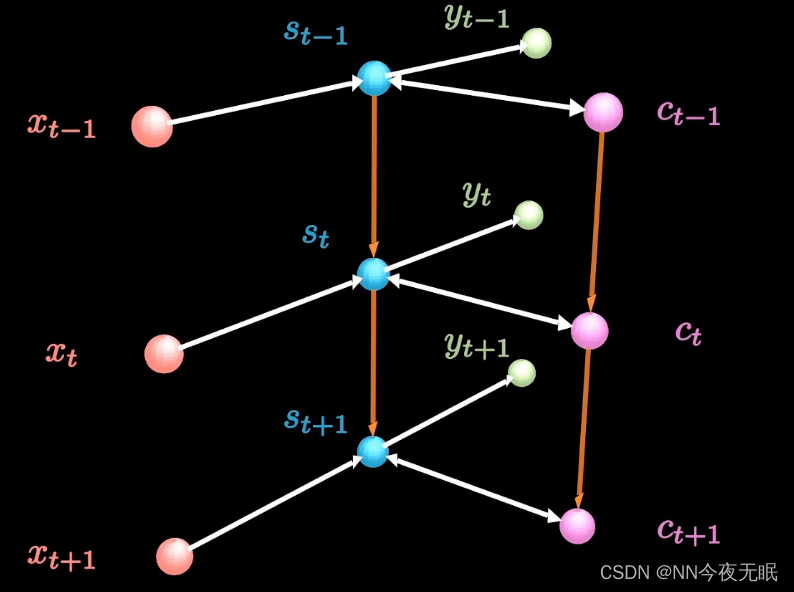
RNN会考虑时序
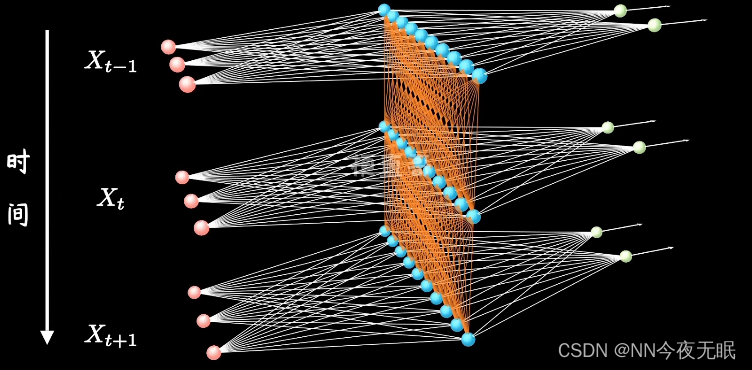
RNN时间对整体的影响:下一次的情况,对于原来的影响,会使整体改变,这一部分的影响来源于Ws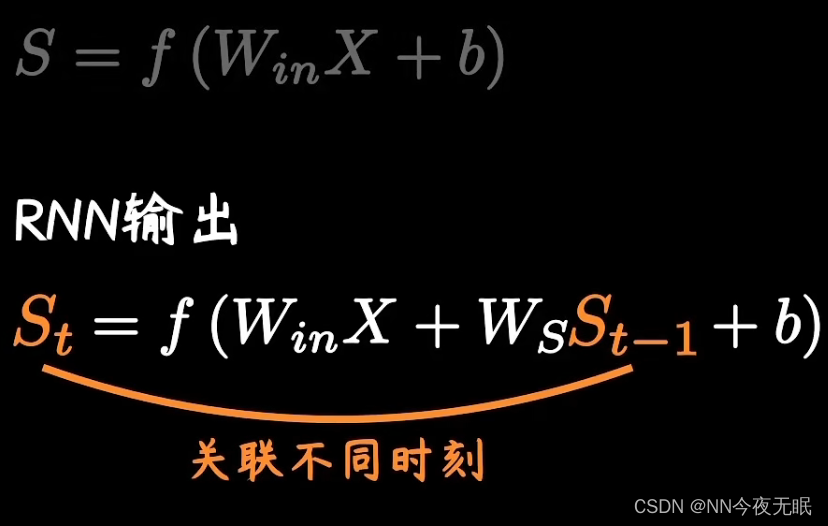
但是!记忆难以持久!超过10步就记不住之前的内容了,也就是说之前内容的影响太小了以至于结果与前几步的内容没关系
怎么办!LSTM长短期记忆与网络Long Short-term Memory

由于时序上的层级结构,输入输出更灵活
many to one:输入声音时序,输出单个对于这个声音的情感判定
one to many:输入一张图片,输出一段描述的话
等长的many to many:ai文章生成器,输入一段话,输出一篇文章
不等长的many to many:encoder-decoer(两个RNN组合) seq2seq:机器翻译,比如输入段中文,他将数据编码成上下文向量,再做输出预测
RNN的反向传播步骤:
步骤 1: 前向传播
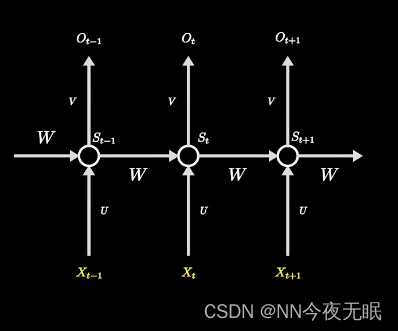
- 时间步的展开:在处理序列时,RNN 会被展开成一系列连接的复制单元,每个单元对应序列中的一个时间步。
- 状态更新:每个时间步,RNN 单元会根据当前输入和上一时间步的隐藏状态计算当前时间步的隐藏状态。
- 输出计算:对于每个时间步,RNN 可能会产生一个输出,这个输出基于当前的隐藏状态。
步骤 2: 计算误差
- 输出误差:在序列的每个时间步,计算预测输出与实际输出之间的误差。
- 总误差:累加所有时间步的误差,得到整个序列的总误差。
步骤 3: 反向传播
- 时间步的反向传播:从最后一个时间步开始,逆向通过每一个时间步来传播误差。
- 梯度计算:对于每个时间步,计算误差关于网络参数的梯度(即权重和偏差)。
- 梯度累加:由于网络在时间步间共享参数,因此每个时间步计算出的参数梯度都需要累加起来。
步骤 4: 参数更新
- 梯度下降:使用梯度以及一个学习率来更新网络的参数。
- 剪切或正则化:在实际应用中,通常会对梯度进行剪切或应用正则化,以防止梯度爆炸或消失的问题。
挑战:梯度消失和梯度爆炸
- 梯度消失:在长序列中,梯度可能会随着传播逐渐变小,导致网络难以学习长期依赖。
- 梯度爆炸:相反的,梯度可能会变得非常大,导致网络参数更新过猛,使得学习过程不稳定。
LSTM
记录long-term memory
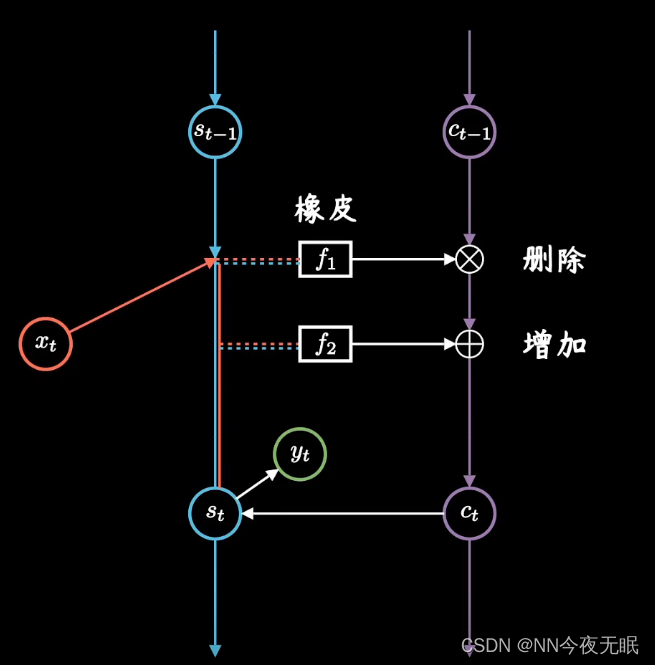
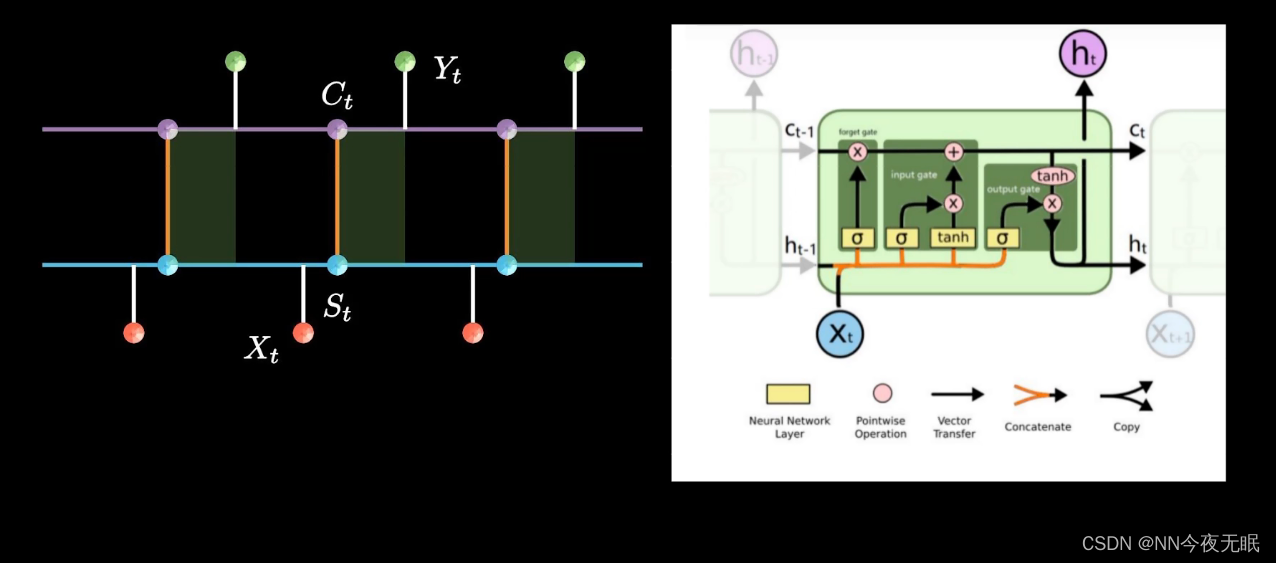
左侧的短期记忆链和右侧的长期记忆连相互更新,关注重要信息,忽略不重要的

Attention
attention就是权重!!

不管输入多长,都压缩成相同长度的编码,就是c
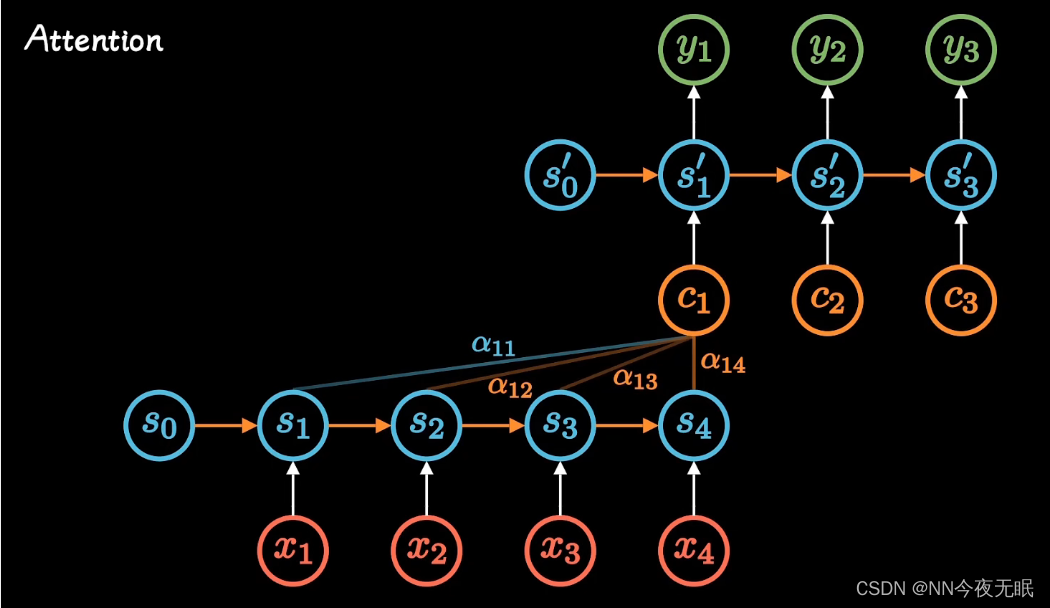
attention在每个时间输入不同的c ,然后每个c,都和之前的每个s有权重关系a,最后调整这个权重矩阵a,即可。这里的c是长期记忆
这样每一时刻都被考虑进去,此前每个时刻的重要程度被不同的考虑,每个输出更加准确
RNN必须按照时序一个个运算,这样难以并行运算,效率太低,不如直接把顺序取消了,反正可以得到每一个字对于结果的weight
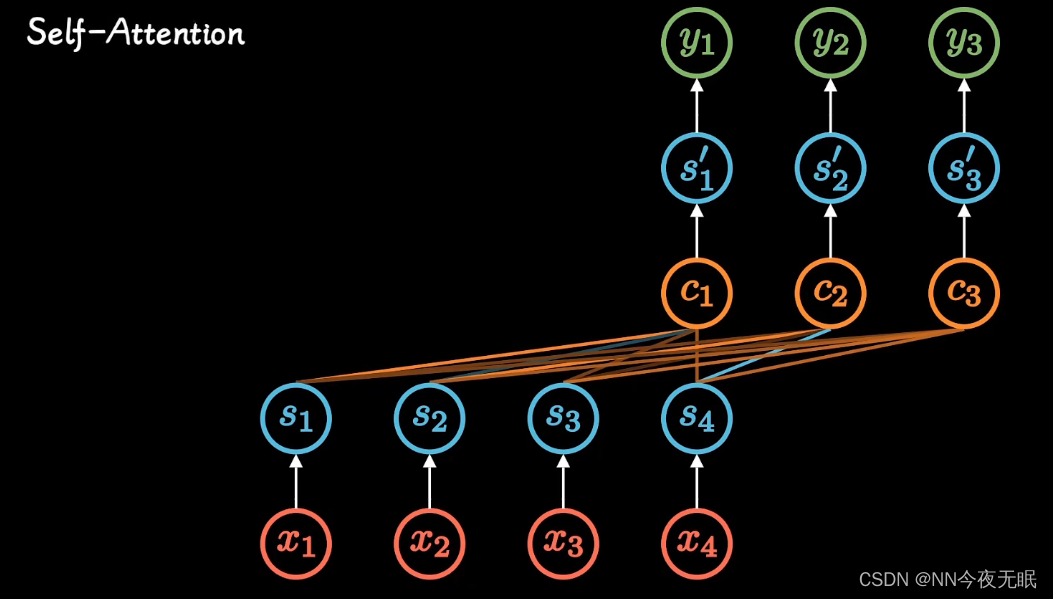

看encoder得到的输出和decoder中别的节点的输出
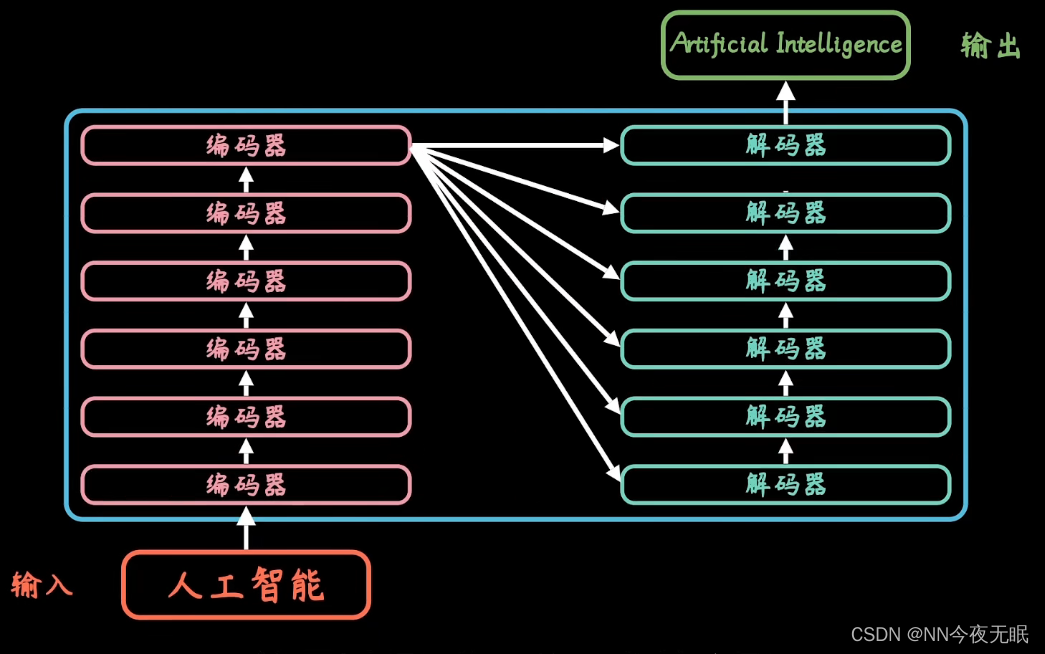
Transformer

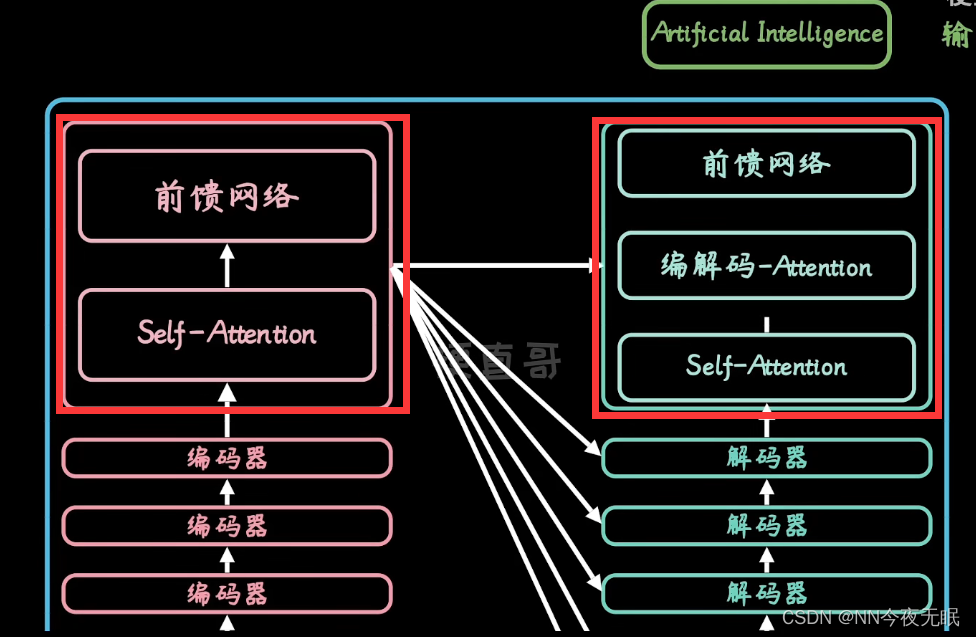
要考虑encoder上下文细节
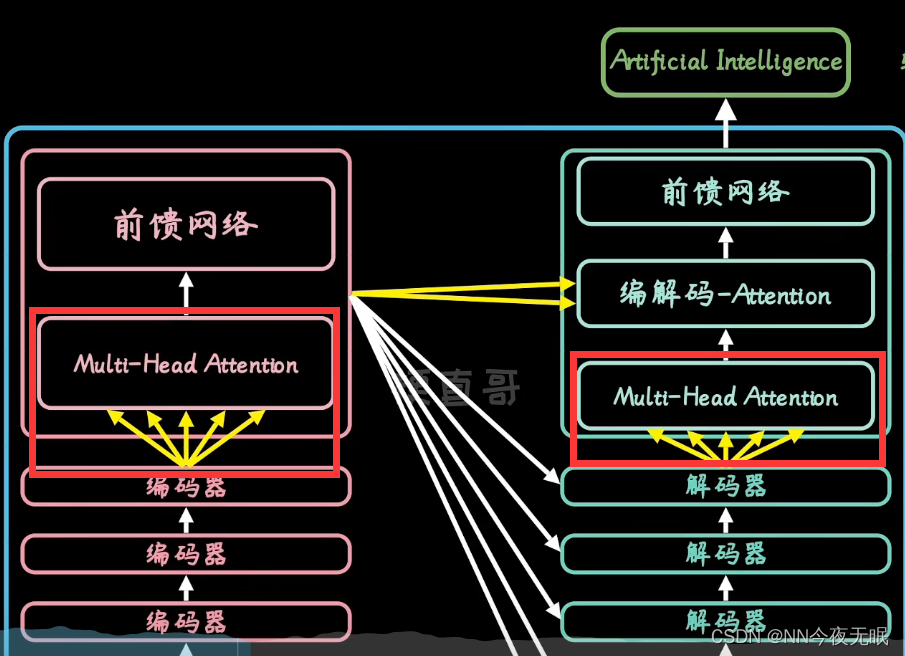
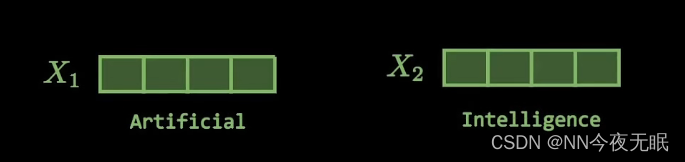
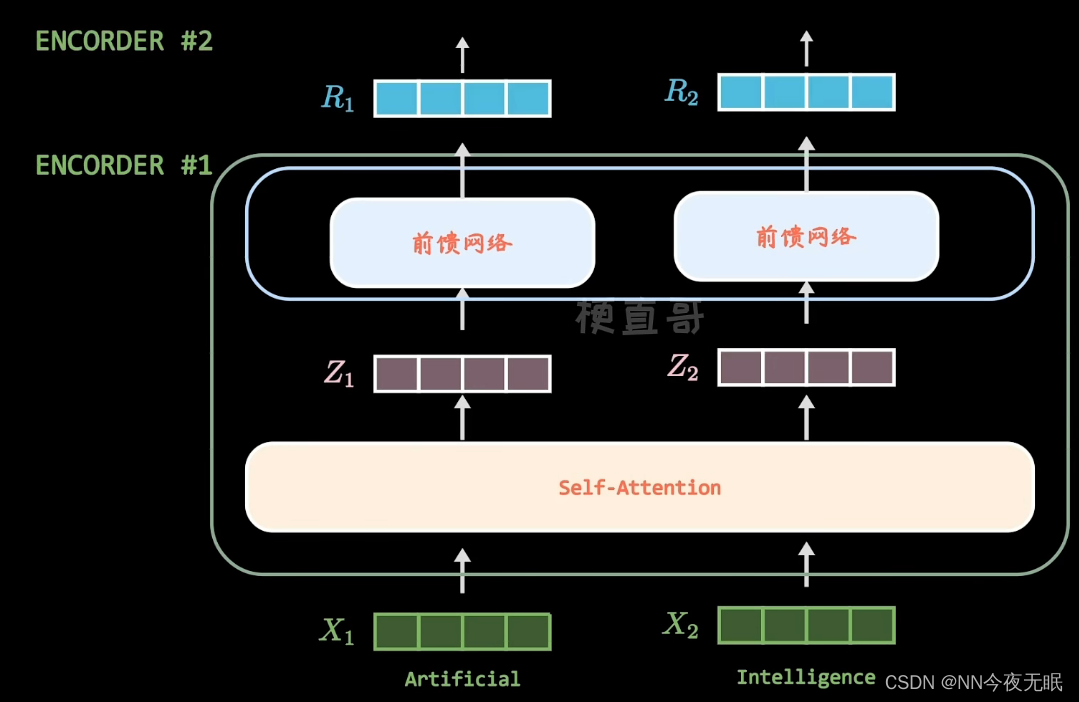
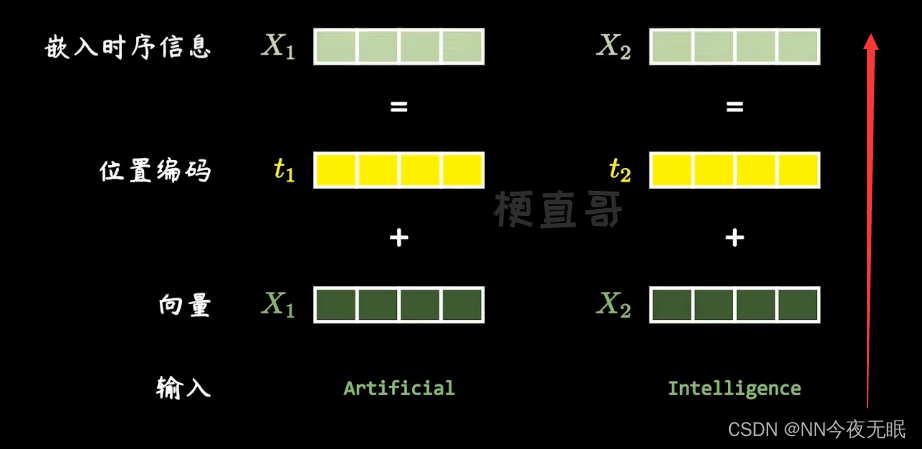
单词向量化,嵌入位置信息,变成统一长度,比如512位
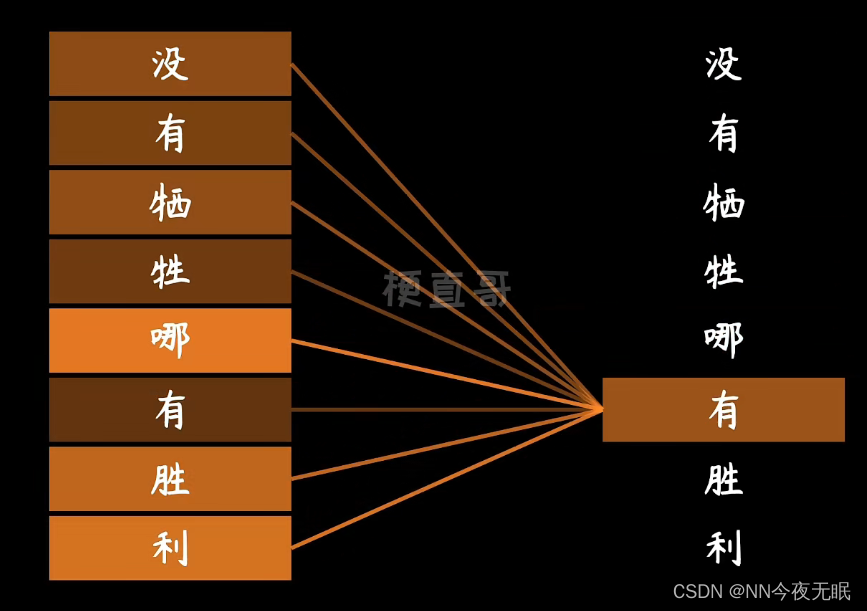
相互关系也通过权重表明,左侧每个字的热力,就是右侧这个字与相应的词的关系权重
具体是这样计算的: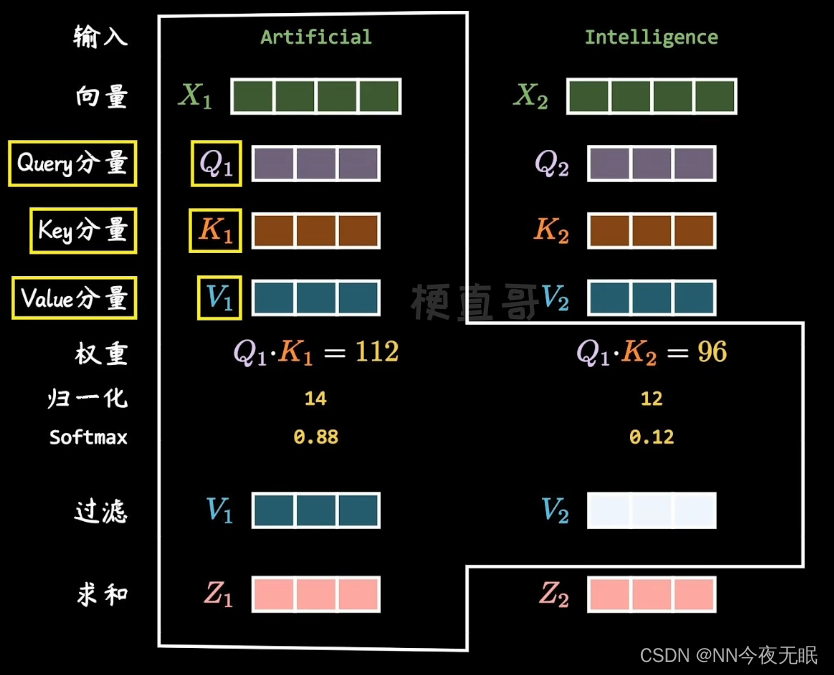
简单来说: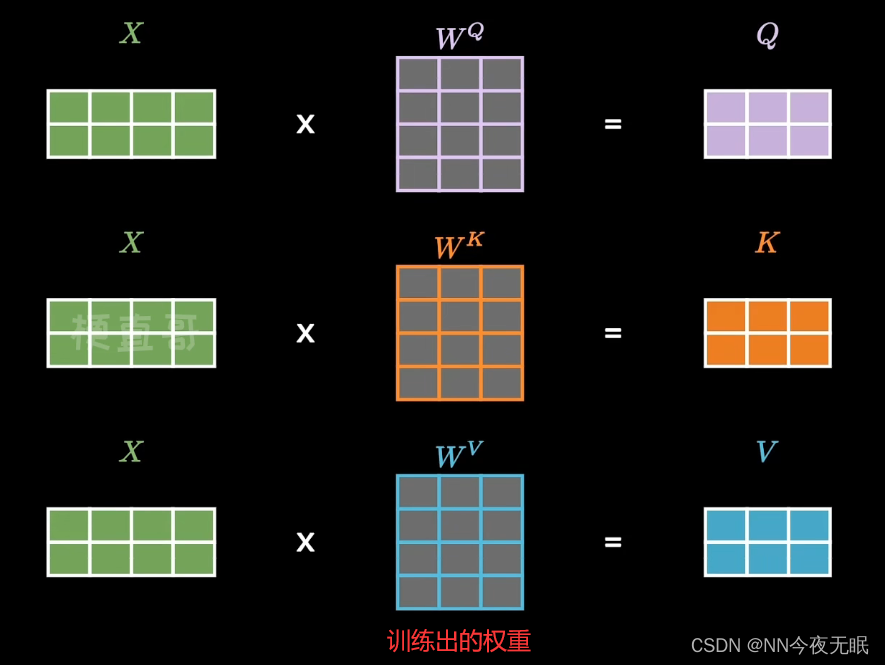
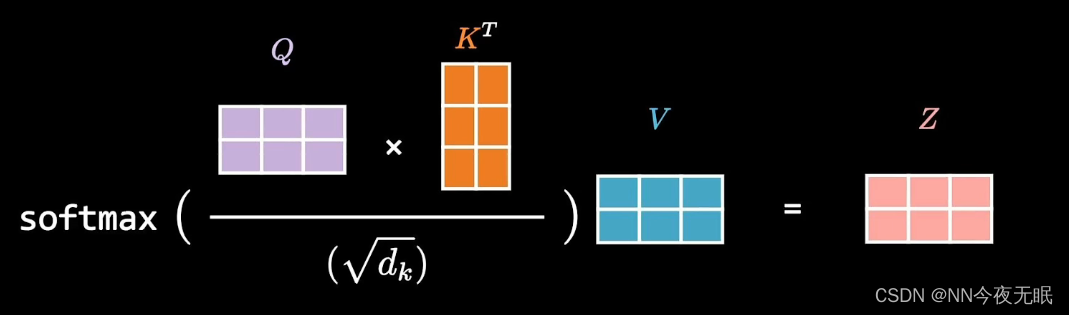
BERT
embedding沟通两个不同的领域
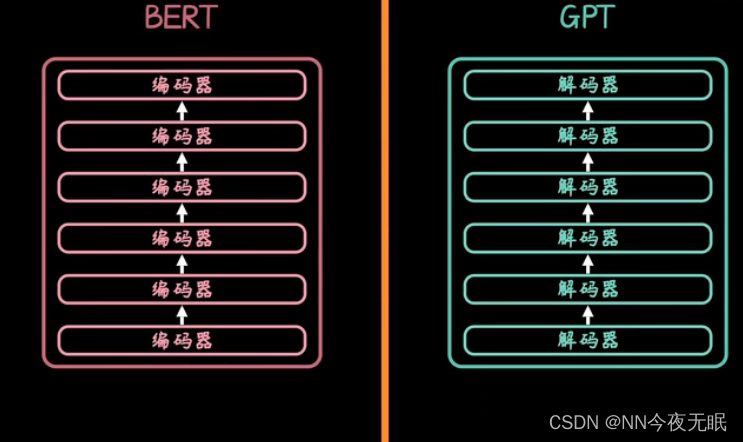
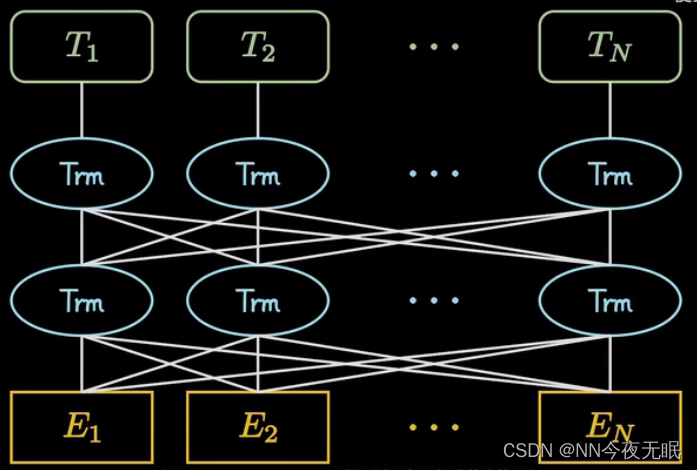
双向连接的多个encoder
BERT=bidirectional encoder representation from transformers
结构
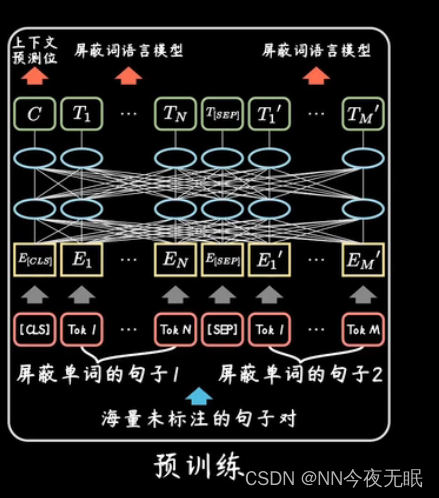
预训练:海量无监督语料,预测屏蔽的单词,输入的每个token时一个单词片段,把词根和词缀切开,经过转换后得到embeding

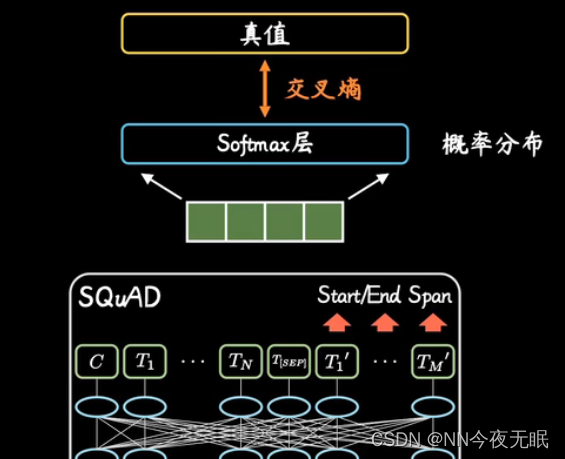
fine-tuning:加训,输入改为问题和包含答案的段落,输出改为具体的答案















 864
864











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









