







 本文深入探讨BERT,一种基于Transformer的双向语言模型,通过Masked Language Model和Next Sentence Prediction任务进行预训练。BERT在多个NLP任务中表现出色,尤其是在句子级别的理解上,其创新之处在于融合了上下文信息。预训练阶段,15%的WordPiece tokens被随机处理,80%替换为[MASK],10%为随机词,10%保持不变,以平衡预训练与微调的效果。实验结果显示,BERT在GLUE任务集上全面超越其他模型,大模型在小任务上也能取得显著提升。
本文深入探讨BERT,一种基于Transformer的双向语言模型,通过Masked Language Model和Next Sentence Prediction任务进行预训练。BERT在多个NLP任务中表现出色,尤其是在句子级别的理解上,其创新之处在于融合了上下文信息。预训练阶段,15%的WordPiece tokens被随机处理,80%替换为[MASK],10%为随机词,10%保持不变,以平衡预训练与微调的效果。实验结果显示,BERT在GLUE任务集上全面超越其他模型,大模型在小任务上也能取得显著提升。
这篇介绍以下最近大热的BERT,它在11个NLP任务中刷新了成绩,效果确实惊人。不过在介绍论文之前我还是想说这项工作不是很好复现,如果没有足够的资源就不要想了 。我觉得很可能未来的利用价值在于直接使用作者公布的预训练好的模型。
回顾
现在有很多利用预训练的语言表征来完成下游NLP任务的研究,作者把它们概括为两类feature-based和fine-tuning:
| 分类 | 代表 | task-specific模型 | 使用方案 |
|---|---|---|---|
| feature-based | ELMo | 需要 | 把表征作为feature提供给下游任务 |
| fine-tuning | OpenAI GPT,(前文介绍过的) ULMFiT | 不需要 | fine tune预训练的参数 |
这两类方法的共性在于它们在预训练中都使用了一样的目标函数,也都使用了单向的语言模型。
作者对这些方法的批评在于它们没有很好的利用上下文的信息。尽管如ELMo这样的算法利用了正向和反向的语言模型,可本质上仍然是两个unidirectional模型的叠加。对于SQuAD这种阅读理解式的任务,能够同时从两个方向提取context信息至关重要,然而现存的方法有巨大的局限性。
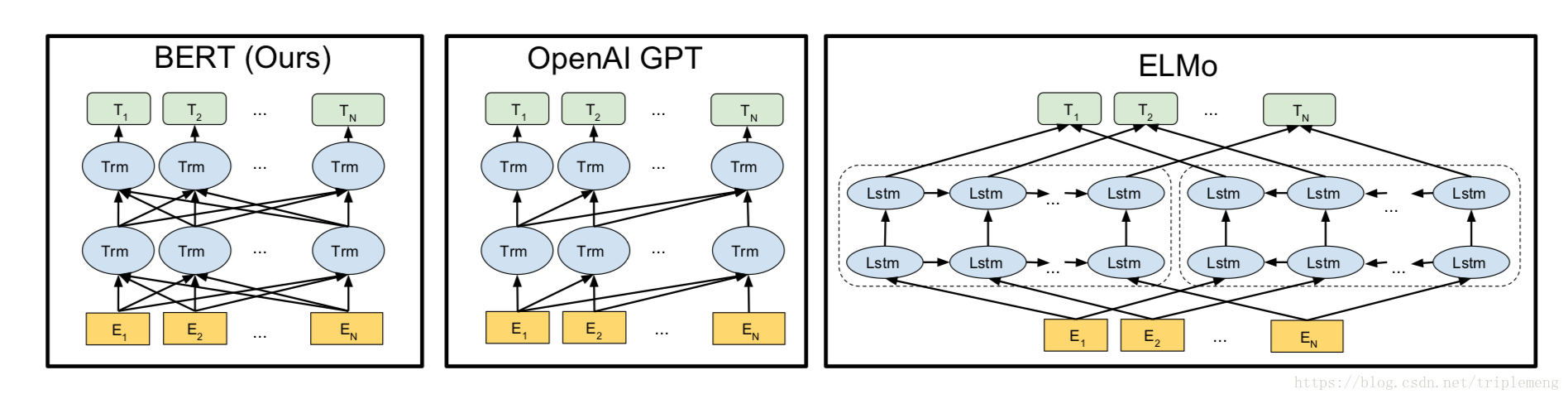
BERT, OpenAI GPT, 和ELMo之间的区别如图示:
创新
作为fine-tuning这一类的方法,作者提出了改进的方案:BERT(Bidirectional Encoder Representations from Transformers)
具体做法是,
- 采取新的预训练的目标函数:the “masked language model” (MLM) 随机mask输入中的一些tokens,然后在预训练中对它们进行预测。这样做的好处是学习到的表征能够融合两个方向上的context。这个做法我觉得非常像skip-gram。过去的同类算法在这里有所欠缺,比如上文提到的ELMo,它用的是两个单向的LSTM然后把结果拼接起来;还有OpenAI GPT,虽然它一样使用了transformer,但是只利用了一个方向的注意力机制,本质上也一样是单项的语言模型。
- 增加句子级别的任务:“next sentence prediction”
作者认为很多NLP任务比如QA和NLI都需要对两个句子之间关系的理解,而语言模型不能很好的直接产生这种理解。为了理解句子关系,作者同时pre-train了一个“next sentence prediction”任务。具体做法是随机替换一些句子,然后利用上一句进行IsNext/NotNext的预测。
在实际的预训练中,这两个任务是jointly training
BERT模型
模型架构
论文使用了两种模型:
B E R T B A S E BERT_{BASE} BERT
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章


















 2801
2801

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









