






文章目录
一、MapReduce与Hbase的集成
- 将hbase-site.xml文件复制到$HADOOP_HOME/etc/hadoop下
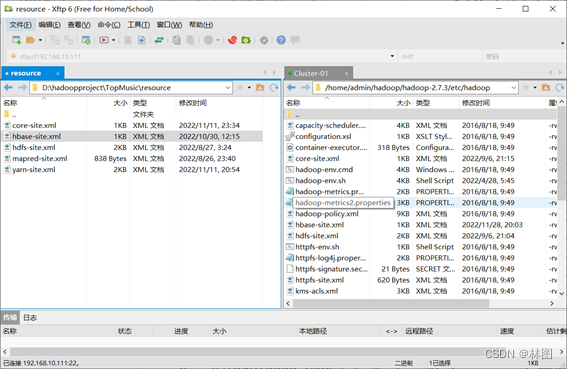
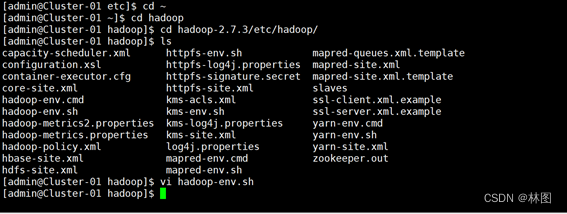
- .编辑$HADOOP_HOME/etc/hadoop/Hadoop-enc.sh文件,增加一下内容
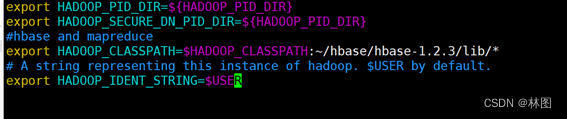
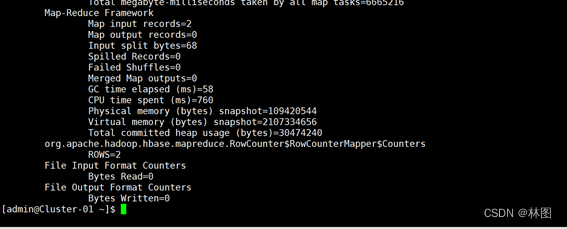
- Hbase与MapReduce集成环境测试
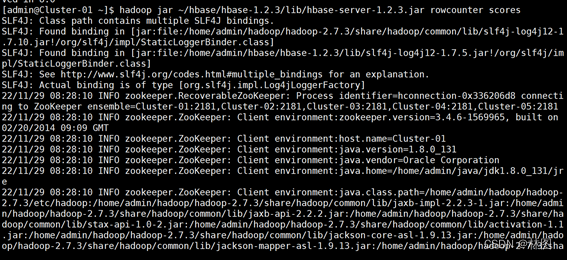
- .测试结果

二、批量数据导入
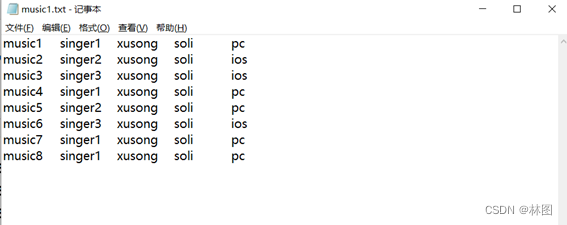
1 准备数据创建music1.txt, music2.txt, music3,txt文件
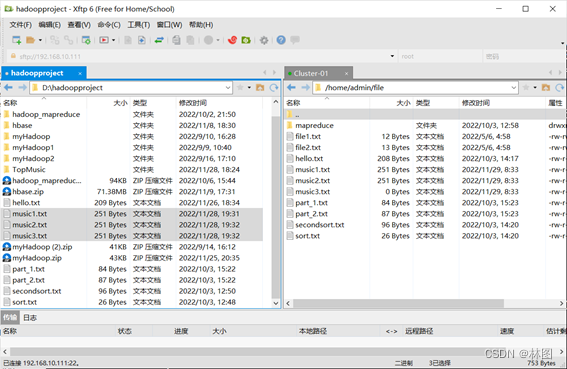
2. 导入虚拟机,然后上传到hadoop

3. 推入到hadoop
4.查看是否推入成功
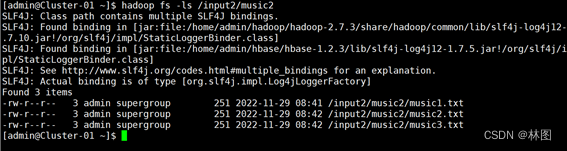
5.使用Hbase自带工具类批量导入方式导入
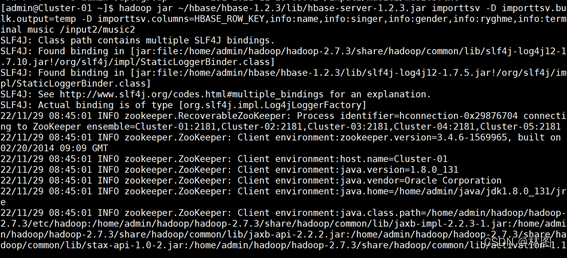
6.查看运行结果
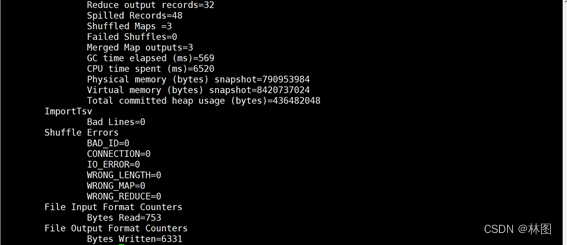
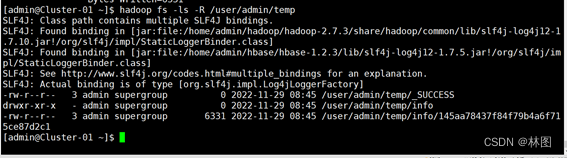
7.使用Hbase中的completebulkload将tmp目录移动到Hregion中完成数据加载
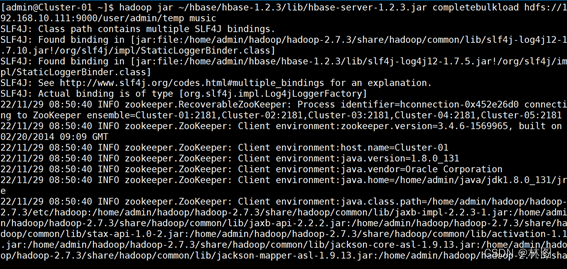
8.进入Hbase查看是否导入
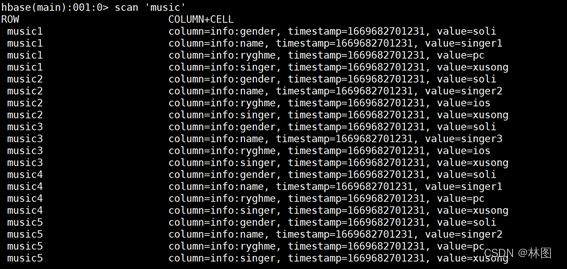
三、 Hbase MapReduce API-运行TableMapperDemo
TableMapper使用从Hbase中读取数据代码
//
// Source code recreated from a .class file by IntelliJ IDEA
// (powered by FernFlower decompiler)
//
package com.music;
import java.io.IOException;
import java.util.ArrayList;
import java.util.Iterator;
import java.util.List;
import org.apache.commons.lang.StringUtils;
import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.fs.FileSystem;
import org.apache.hadoop.fs.Path;
import org.apache.hadoop.hbase.Cell;
import org.apache.hadoop.hbase.CellUtil;
import org.apache.hadoop.hbase.HBaseConfiguration;
import org.apache.hadoop.hbase.client.Result;
import org.apache.hadoop.hbase.client.Scan;
import org.apache.hadoop.hbase.io.ImmutableBytesWritable;
import org.apache.hadoop.hbase.mapreduce.TableInputFormat;
import org.apache.hadoop.hbase.mapreduce.TableMapReduceUtil;
import org.apache.hadoop.hbase.mapreduce.TableMapper;
import org.apache.hadoop.hbase.util.Bytes;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Job;
import org.apache.hadoop.mapreduce.lib.output.FileOutputFormat;
import org.apache.hadoop.util.GenericOptionsParser;
public class TableMapperDemo {
public TableMapperDemo() {
}
public static void main(String[] args) throws IOException, ClassNotFoundException, InterruptedException {
Configuration conf = HBaseConfiguration.create();
new GenericOptionsParser(conf, args);
System.out.println("temjars");
conf.set("hbase.mapreduce.inputtable", "music");
conf.set("hbase.mapreduce.scan.columns", "info:name info:gender");
conf.set("hbase.mapreduce.scan.row.start", "music1");
conf.set("hbase.zookeeper.quorum", "Cluster-01:2181,Cluster-02:2181,Cluster-03:2181,Cluster-04:2181,Cluster-05:2181");
conf.set("hbase.zookeeper.property.clientPort", "2181");
conf.set("mapreduce.framework.name", "yarn");
conf.set("yarn.resourcemanager.address", "Cluster-01:8032");
conf.set("yarn.resourcemanager.scheduler.address", "Cluster-01:8030");
conf.addResource("mapred-site.xml");
conf.addResource("core-site.xml");
conf.addResource("hdfs-site.xml");
conf.addResource("yarn-site.xml");
Job job = Job.getInstance(conf, "hbase-mapreduce-api");
job.setJarByClass(TableMapperDemo.class);
job.setInputFormatClass(TableInputFormat.class);
job.setMapperClass(TableMapperDemo.Mapper.class);
job.setMapOutputKeyClass(Text.class);
job.setOutputValueClass(Text.class);
List<String> libjars = new ArrayList();
job.getConfiguration().set("tmpjars", StringUtils.join(libjars, ','));
Path output = new Path("/output2/music2");
if (FileSystem.get(conf).exists(output)) {
FileSystem.get(conf).delete(output, true);
}
FileOutputFormat.setOutputPath(job, output);
Scan scan = new Scan();
scan.addColumn(Bytes.toBytes("info"), Bytes.toBytes("name"));
scan.addColumn(Bytes.toBytes("info"), Bytes.toBytes("gender"));
TableMapReduceUtil.initTableMapperJob("music", scan, TableMapperDemo.Mapper.class, Text.class, (Class)null, job);
job.waitForCompletion(true);
}
static class Mapper extends TableMapper<Text, Text> {
Mapper() {
}
protected void map(ImmutableBytesWritable key, Result value, org.apache.hadoop.mapreduce.Mapper<ImmutableBytesWritable, Result, Text, Text>.Context context) throws IOException, InterruptedException {
List<Cell> cells = value.listCells();
Iterator var6 = cells.iterator();
while(var6.hasNext()) {
Cell cell = (Cell)var6.next();
String outValue = String.format("Rowkey:%s Family:%s Qualifier:%s cellValue:%s", Bytes.toString(key.get()), Bytes.toString(CellUtil.cloneFamily(cell)), Bytes.toString(CellUtil.cloneQualifier(cell)), Bytes.toString(CellUtil.cloneValue(cell)));
context.write(new Text(CellUtil.getCellKeyAsString(cell)), new Text(outValue));
}
}
}
}
2.更改yarn-site.xml文件并发送到各个节点
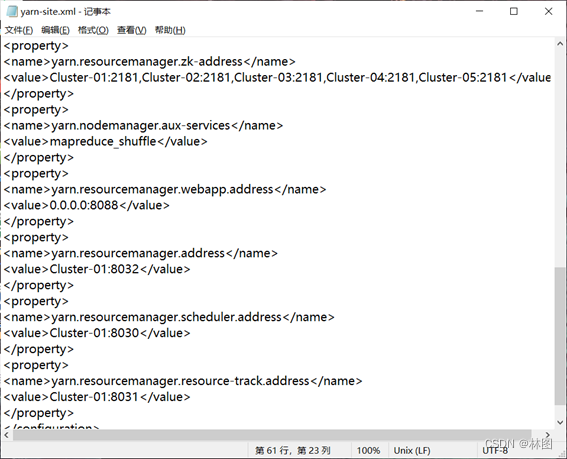
3.将代码打包发送到虚拟机
4.使用hadoop jar+jar包方式运行代码
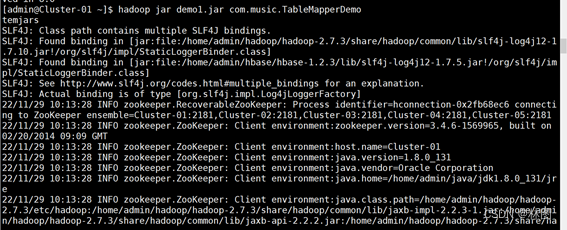
5.运行结果
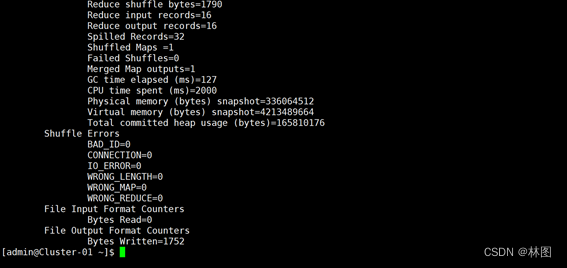
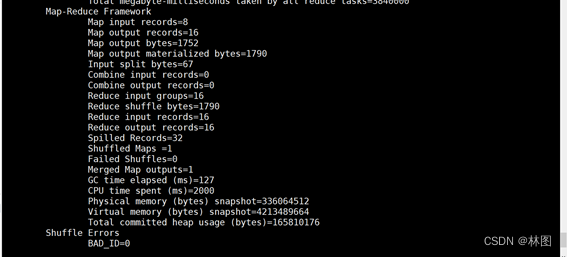
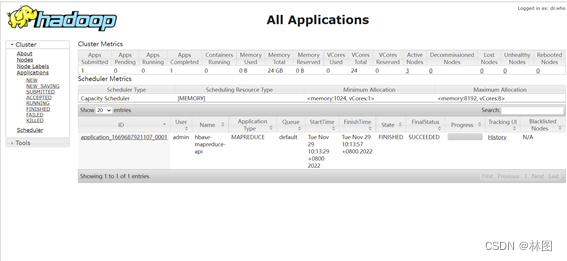
6.在hadoop中查看结果
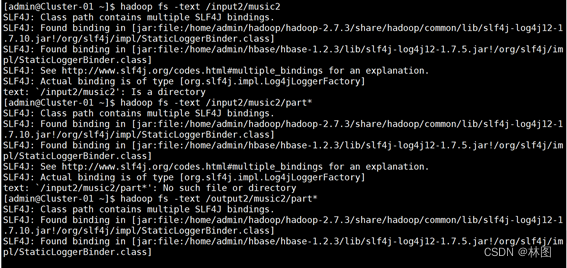
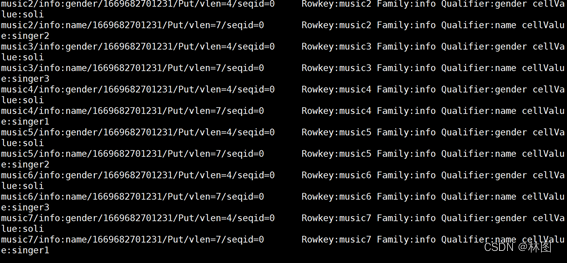
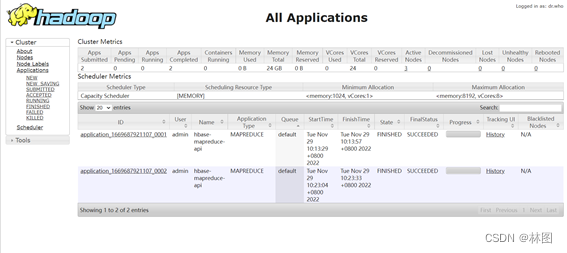
7.访问192.168.10.111:8080/cluster/apps/查看
四、TableMapper数据去重
1.TableMapperDemo2代码编写
//
// Source code recreated from a .class file by IntelliJ IDEA
// (powered by FernFlower decompiler)
//
package com.music;
import java.io.IOException;
import java.util.Iterator;
import java.util.List;
import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.hbase.Cell;
import org.apache.hadoop.hbase.CellUtil;
import org.apache.hadoop.hbase.HBaseConfiguration;
import org.apache.hadoop.hbase.client.Put;
import org.apache.hadoop.hbase.client.Result;
import org.apache.hadoop.hbase.client.Scan;
import org.apache.hadoop.hbase.io.ImmutableBytesWritable;
import org.apache.hadoop.hbase.mapreduce.TableMapReduceUtil;
import org.apache.hadoop.hbase.mapreduce.TableMapper;
import org.apache.hadoop.hbase.mapreduce.TableOutputFormat;
import org.apache.hadoop.hbase.util.Bytes;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Job;
import org.apache.hadoop.mapreduce.Mapper;
import org.apache.hadoop.util.GenericOptionsParser;
public class TableMapperDemo2 {
public TableMapperDemo2() {
}
public static void main(String[] args) throws IOException, ClassNotFoundException, InterruptedException {
Configuration conf = HBaseConfiguration.create();
new GenericOptionsParser(conf, args);
conf.set("hbase.zookeeper.quorum", "Cluster-01:2181,Cluster-02:2181,Cluster-03:2181,Cluster-04:2181,Cluster-05:2181");
conf.set("hbase.zookeeper.property.clientPort", "2181");
conf.set("mapreduce.framework.name", "yarn");
conf.set("yarn.resourcemanager.address", "Cluster-01:8032");
conf.set("yarn.resourcemanager.scheduler.address", "Cluster-01:8030");
conf.addResource("mapred-site.xml");
conf.addResource("core-site.xml");
conf.addResource("hdfs-site.xml");
conf.addResource("yarn-site.xml");
Job job = Job.getInstance(conf, "hbase-mapreduce-api");
job.setJarByClass(TableMapperDemo2.class);
job.setOutputFormatClass(TableOutputFormat.class);
job.getConfiguration().set("hbase.mapred.outputtable", "namelist");
Scan scan = new Scan();
scan.addColumn(Bytes.toBytes("info"), Bytes.toBytes("name"));
TableMapReduceUtil.initTableMapperJob("music", scan, TableMapperDemo2.MyMapper.class, Text.class, Put.class, job);
job.waitForCompletion(true);
}
static class MyMapper extends TableMapper<Text, Put> {
MyMapper() {
}
protected void map(ImmutableBytesWritable key, Result value, Mapper<ImmutableBytesWritable, Result, Text, Put>.Context context) throws IOException, InterruptedException {
List<Cell> cells = value.listCells();
Iterator var6 = cells.iterator();
while(var6.hasNext()) {
Cell cell = (Cell)var6.next();
Put put = new Put(CellUtil.cloneValue(cell));
put.addColumn(Bytes.toBytes("details"), Bytes.toBytes("rank"), Bytes.toBytes(0));
context.write(new Text(Bytes.toString(CellUtil.cloneValue(cell))), put);
}
}
}
}
2.先创建namelist表
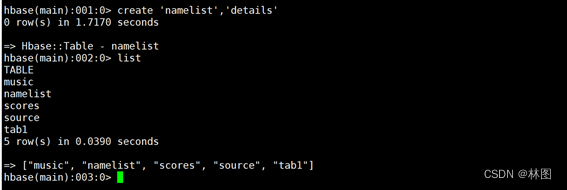
3.打成jar包运行
4.运行结果
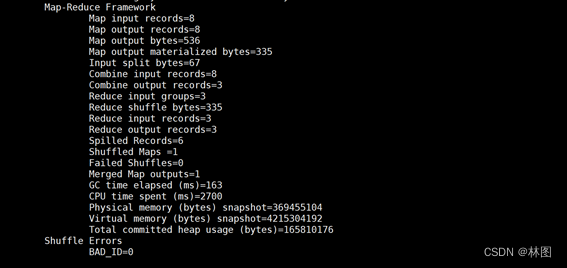
5.进入hbase查看namelist

五、TableReduce统计
1.编写TableReduce代码
//
// Source code recreated from a .class file by IntelliJ IDEA
// (powered by FernFlower decompiler)
//
package com.music;
import java.io.IOException;
import java.util.Iterator;
import java.util.List;
import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.hbase.Cell;
import org.apache.hadoop.hbase.CellUtil;
import org.apache.hadoop.hbase.HBaseConfiguration;
import org.apache.hadoop.hbase.client.Mutation;
import org.apache.hadoop.hbase.client.Put;
import org.apache.hadoop.hbase.client.Result;
import org.apache.hadoop.hbase.client.Scan;
import org.apache.hadoop.hbase.io.ImmutableBytesWritable;
import org.apache.hadoop.hbase.mapreduce.TableMapReduceUtil;
import org.apache.hadoop.hbase.mapreduce.TableMapper;
import org.apache.hadoop.hbase.mapreduce.TableReducer;
import org.apache.hadoop.hbase.util.Bytes;
import org.apache.hadoop.io.IntWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Job;
import org.apache.hadoop.mapreduce.Mapper;
import org.apache.hadoop.mapreduce.Reducer;
import org.apache.hadoop.util.GenericOptionsParser;
public class TableReduceDemo {
public TableReduceDemo() {
}
public static void main(String[] args) throws IOException, ClassNotFoundException, InterruptedException {
Configuration conf = HBaseConfiguration.create();
new GenericOptionsParser(conf, args);
Job job = Job.getInstance(conf, "top-music");
job.setJarByClass(TableReduceDemo.class);
job.setNumReduceTasks(2);
Scan scan = new Scan();
scan.addColumn(Bytes.toBytes("info"), Bytes.toBytes("name"));
TableMapReduceUtil.initTableMapperJob("music", scan, TableReduceDemo.MyMapper.class, Text.class, IntWritable.class, job);
TableMapReduceUtil.initTableReducerJob("namelist", TableReduceDemo.MyReducer.class, job);
job.waitForCompletion(true);
}
static class MyMapper extends TableMapper<Text, IntWritable> {
MyMapper() {
}
protected void map(ImmutableBytesWritable key, Result value, Mapper<ImmutableBytesWritable, Result, Text, IntWritable>.Context context) throws IOException, InterruptedException {
List<Cell> cells = value.listCells();
Iterator var6 = cells.iterator();
while(var6.hasNext()) {
Cell cell = (Cell)var6.next();
context.write(new Text(Bytes.toString(CellUtil.cloneValue(cell))), new IntWritable(1));
}
}
}
static class MyReducer extends TableReducer<Text, IntWritable, Text> {
MyReducer() {
}
protected void reduce(Text key, Iterable<IntWritable> values, Reducer<Text, IntWritable, Text, Mutation>.Context context) throws IOException, InterruptedException {
int playCount = 0;
IntWritable num;
for(Iterator var6 = values.iterator(); var6.hasNext(); playCount += num.get()) {
num = (IntWritable)var6.next();
}
Put put = new Put(Bytes.toBytes(key.toString()));
put.addColumn(Bytes.toBytes("details"), Bytes.toBytes("rank"), Bytes.toBytes(playCount));
context.write(key, put);
}
}
}
2.打包上传运行
3.查看运行结果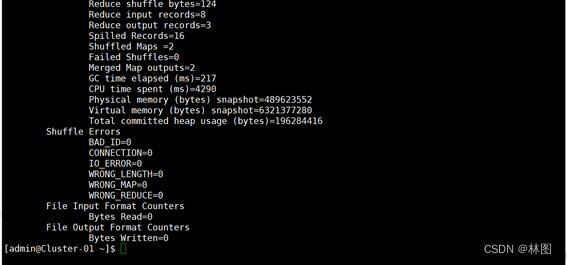
4.进入habse查看表

六、音乐排行榜的实现
1.音乐排行榜代码编写
//
// Source code recreated from a .class file by IntelliJ IDEA
// (powered by FernFlower decompiler)
//
package com.music;
import java.io.IOException;
import java.util.Iterator;
import java.util.List;
import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.fs.FSDataInputStream;
import org.apache.hadoop.fs.FileSystem;
import org.apache.hadoop.fs.Path;
import org.apache.hadoop.hbase.Cell;
import org.apache.hadoop.hbase.CellUtil;
import org.apache.hadoop.hbase.HBaseConfiguration;
import org.apache.hadoop.hbase.client.Mutation;
import org.apache.hadoop.hbase.client.Put;
import org.apache.hadoop.hbase.client.Result;
import org.apache.hadoop.hbase.client.Scan;
import org.apache.hadoop.hbase.io.ImmutableBytesWritable;
import org.apache.hadoop.hbase.mapreduce.TableMapReduceUtil;
import org.apache.hadoop.hbase.mapreduce.TableMapper;
import org.apache.hadoop.hbase.mapreduce.TableReducer;
import org.apache.hadoop.hbase.util.Bytes;
import org.apache.hadoop.io.IOUtils;
import org.apache.hadoop.io.IntWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.io.WritableComparable;
import org.apache.hadoop.io.IntWritable.Comparator;
import org.apache.hadoop.mapreduce.Job;
import org.apache.hadoop.mapreduce.Mapper;
import org.apache.hadoop.mapreduce.Reducer;
import org.apache.hadoop.mapreduce.lib.output.FileOutputFormat;
import org.apache.hadoop.util.GenericOptionsParser;
public class TopMusic {
static final String TABLE_MUSIC = "music";
static final String TABLE_NAMELIST = "namelist";
static final String OUTPUT_PATH = "topmusic";
static Configuration conf = HBaseConfiguration.create();
public TopMusic() {
}
static boolean musicCount(String[] args) throws IOException, ClassNotFoundException, InterruptedException {
Job job = Job.getInstance(conf, "music-count");
job.setJarByClass(TopMusic.class);
job.setNumReduceTasks(2);
Scan scan = new Scan();
scan.addColumn(Bytes.toBytes("info"), Bytes.toBytes("name"));
TableMapReduceUtil.initTableMapperJob("music", scan, TopMusic.ScanMusicMapper.class, Text.class, IntWritable.class, job);
TableMapReduceUtil.initTableReducerJob("namelist", TopMusic.IntNumReducer.class, job);
return job.waitForCompletion(true);
}
static boolean sortMusic(String[] args) throws IOException, ClassNotFoundException, InterruptedException {
Job job = Job.getInstance(conf, "sort-music");
job.setJarByClass(TopMusic.class);
job.setNumReduceTasks(1);
job.setSortComparatorClass(TopMusic.IntWritableDecreaseingComparator.class);
TableMapReduceUtil.initTableMapperJob("namelist", new Scan(), TopMusic.ScanMusicNameMapper.class, IntWritable.class, Text.class, job);
Path output = new Path("topmusic");
if (FileSystem.get(conf).exists(output)) {
FileSystem.get(conf).delete(output, true);
}
FileOutputFormat.setOutputPath(job, output);
return job.waitForCompletion(true);
}
static void showResult() throws IllegalArgumentException, IOException {
FileSystem fs = FileSystem.get(conf);
FSDataInputStream in = null;
try {
in = fs.open(new Path("topmusic/part-r-00000"));
IOUtils.copyBytes(in, System.out, 4096, false);
} finally {
IOUtils.closeStream(in);
}
}
public static void main(String[] args) throws IOException, ClassNotFoundException, InterruptedException {
GenericOptionsParser gop = new GenericOptionsParser(conf, args);
String[] otherArgs = gop.getRemainingArgs();
if (musicCount(otherArgs) && sortMusic(otherArgs)) {
showResult();
}
}
static class IntNumReducer extends TableReducer<Text, IntWritable, Text> {
IntNumReducer() {
}
protected void reduce(Text key, Iterable<IntWritable> values, Reducer<Text, IntWritable, Text, Mutation>.Context context) throws IOException, InterruptedException {
int playCount = 0;
IntWritable num;
for(Iterator var6 = values.iterator(); var6.hasNext(); playCount += num.get()) {
num = (IntWritable)var6.next();
}
Put put = new Put(Bytes.toBytes(key.toString()));
put.addColumn(Bytes.toBytes("details"), Bytes.toBytes("rank"), Bytes.toBytes(playCount));
context.write(key, put);
}
}
private static class IntWritableDecreaseingComparator extends Comparator {
private IntWritableDecreaseingComparator() {
}
public int compare(WritableComparable a, WritableComparable b) {
return -super.compare(a, b);
}
public int compare(byte[] b1, int s1, int l1, byte[] b2, int s2, int l2) {
return -super.compare(b1, s1, l1, b2, s2, l2);
}
}
static class ScanMusicMapper extends TableMapper<Text, IntWritable> {
ScanMusicMapper() {
}
protected void map(ImmutableBytesWritable key, Result value, Mapper<ImmutableBytesWritable, Result, Text, IntWritable>.Context context) throws IOException, InterruptedException {
List<Cell> cells = value.listCells();
Iterator var6 = cells.iterator();
while(var6.hasNext()) {
Cell cell = (Cell)var6.next();
if (Bytes.toString(CellUtil.cloneFamily(cell)).equals("info") && Bytes.toString(CellUtil.cloneQualifier(cell)).equals("name")) {
context.write(new Text(Bytes.toString(CellUtil.cloneValue(cell))), new IntWritable(1));
}
}
}
}
static class ScanMusicNameMapper extends TableMapper<IntWritable, Text> {
ScanMusicNameMapper() {
}
protected void map(ImmutableBytesWritable key, Result value, Mapper<ImmutableBytesWritable, Result, IntWritable, Text>.Context context) throws IOException, InterruptedException {
List<Cell> cells = value.listCells();
Iterator var6 = cells.iterator();
while(var6.hasNext()) {
Cell cell = (Cell)var6.next();
context.write(new IntWritable(Bytes.toInt(CellUtil.cloneValue(cell))), new Text(Bytes.toString(key.get())));
}
}
}
}
2.打包运行
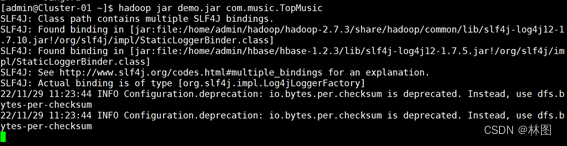
3.查看结果输出
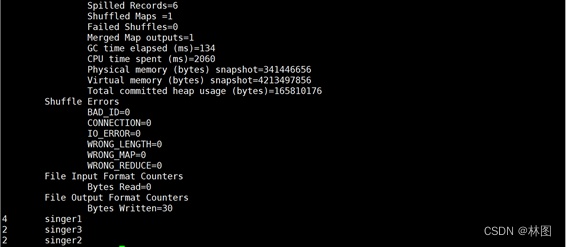
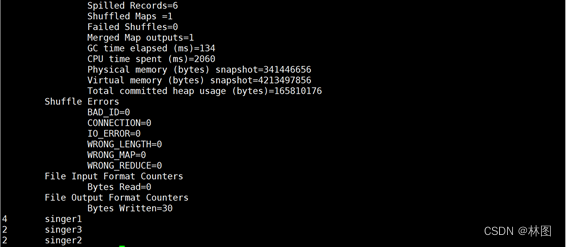
七:sqoop工具的使用
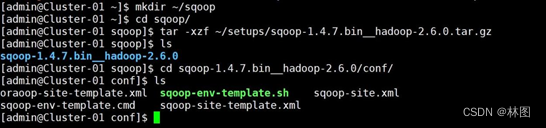
- 安装:将 /root/package/sqoop-1.4.7.bin__hadoop-2.6.0.tar.gz 压缩包解压到/home/admin 目录下并改名
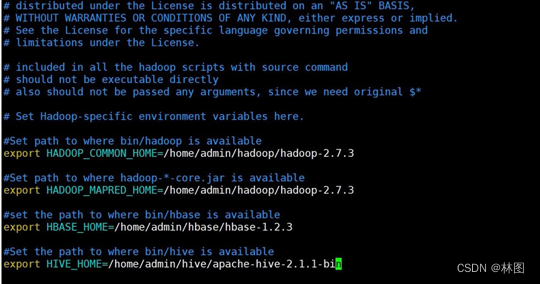
- 配置 Sqoop 环境修改 sqoop-env.sh 文件,添加 Hdoop、Hbase、Hive 等组件的安装路径
- 配置 Linux 系统环境变量,添加 Sqoop 组件的路径

- 测试验证
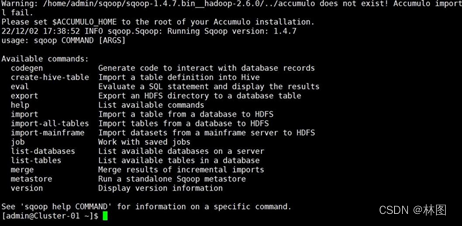
- 测试 Sqoop 是否能够正常连接 MySQL 数据库(需要在lib文件中导入jdbc连接包)
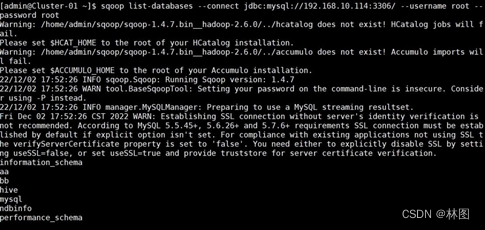
- 创建数据库
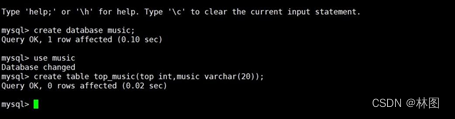
- 实现数据迁移(需要将之前HDFS下生成的名为/topmusic/part-r-00000的包挪到/下)
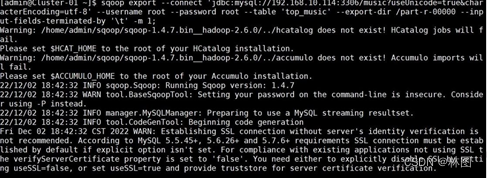
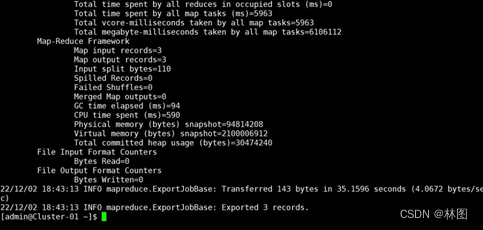
- 迁移成功
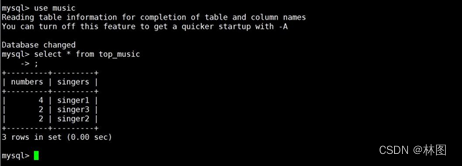
- 查看数据
- 前端网页实现显示数据
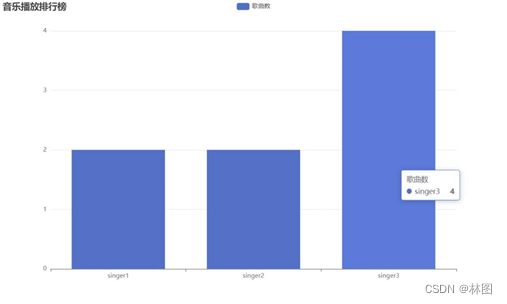
- 网页显示结果
出现的问题与解决方案
1.代码上传运行后若之前有正常突然发现无法运行某节点无法连接
解决:重启所有节点虚拟机,然后查看服务是否未开启
2.MapReduce与Hbase的集成时hbase数据库中必须有scores表不然会报错















 3483
3483











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









