






文章目录
一、Hbase编程创建删除表等操作
1.创建maven工程
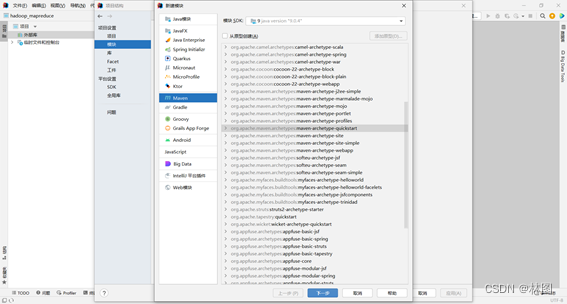
⒉.配置工件坐标
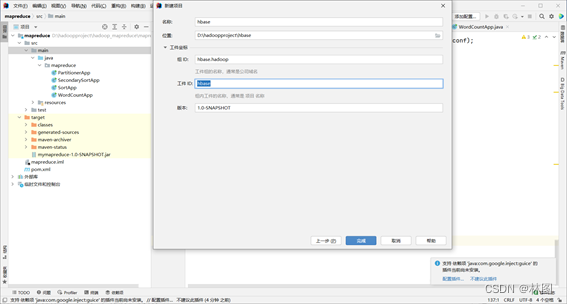
3. 配置pom依赖文件
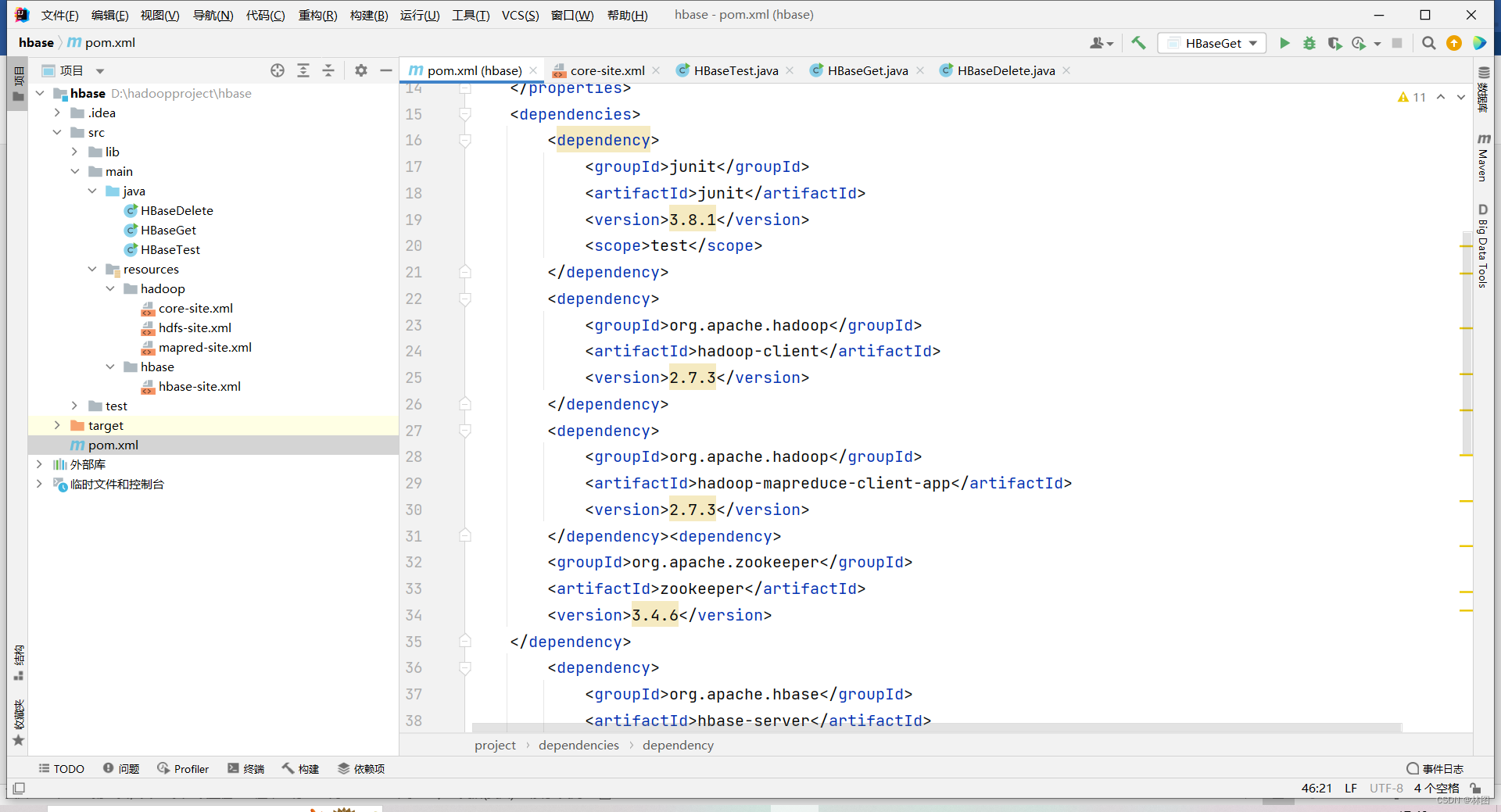
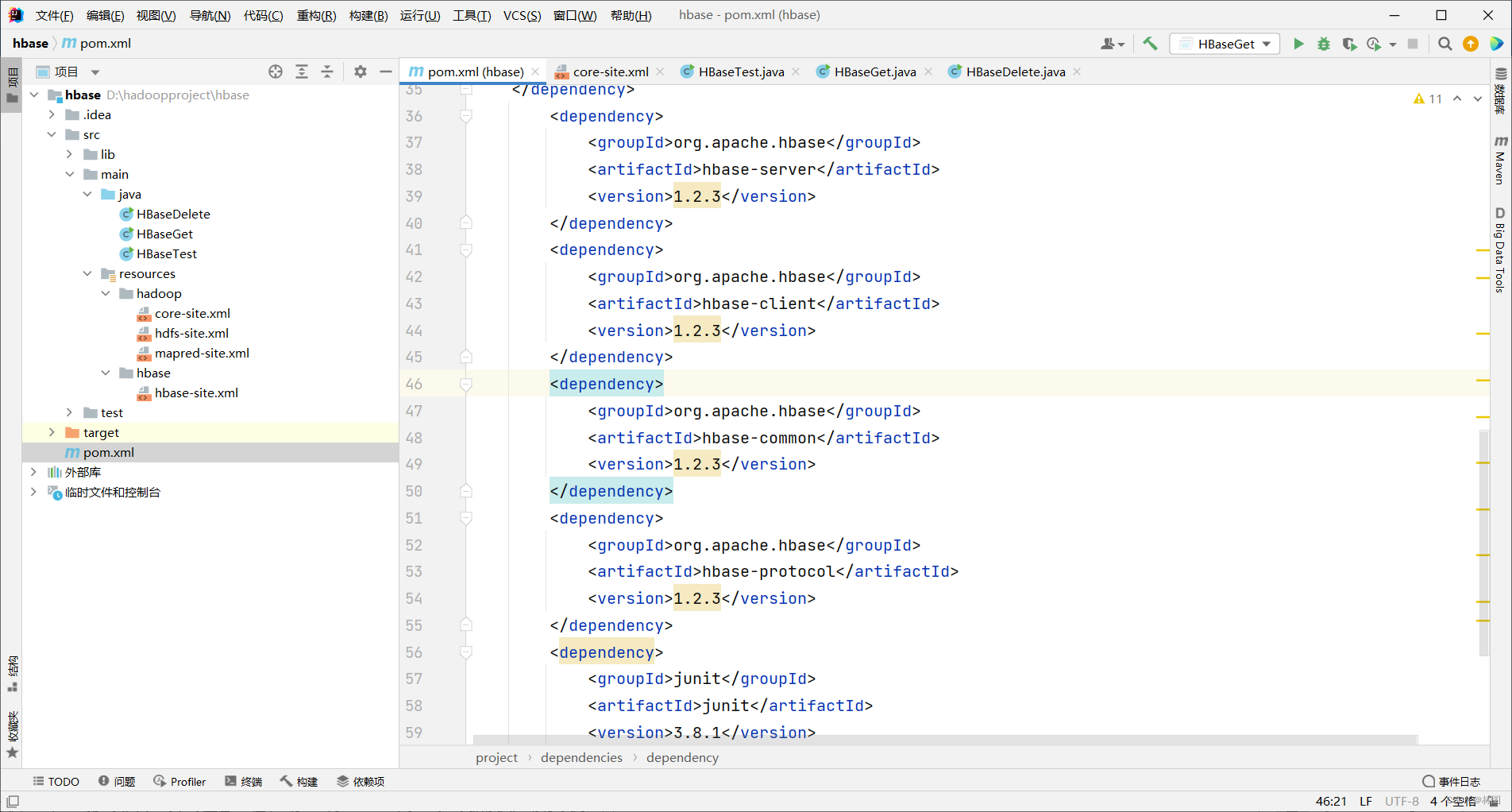
4. 导入Hadoop配置文件
5.导入jar包
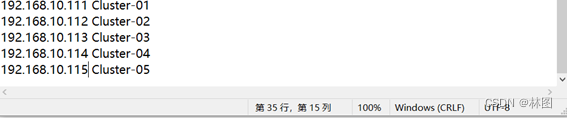
6.修改hosts文件
代码如下
static Configuration cfg = HBaseConfiguration.create();
static {
cfg.set("hbase.zookeeper.quorum","Cluster-01:2181,Cluster-02:2181,Cluster-03:2181,Cluster-04:2181,Cluster-05:2181,");
cfg.set("hbase.zookeeper.property.clientPort","2181");
}
public static void list() throws IOException {
Connection conn = ConnectionFactory.createConnection(cfg);
Admin admin = conn.getAdmin();
System.out.println("----list tables----");
for (TableName tn : admin.listTableNames())
System.out.println(tn);
conn.close();
}
public static void create(String tableName,String... familyNames)
throws IOException {
Connection conn = ConnectionFactory.createConnection(cfg);
Admin admin = conn.getAdmin();
TableName tn = TableName.valueOf(tableName);
if (admin.tableExists(tn)) {
admin.disableTable(tn);
admin.deleteTable(tn);
}
HTableDescriptor htd = new HTableDescriptor(tn);
for (String family : familyNames)
htd.addFamily(new HColumnDescriptor(family));
admin.createTable(htd);
conn.close();
System.out.println("create success !");
}
public static void addColumnFamily(String tableName, String... familyNames)
throws IOException {
Connection conn = ConnectionFactory.createConnection(cfg);
Admin admin = conn.getAdmin();
TableName tn = TableName.valueOf(tableName);
HTableDescriptor htd = admin.getTableDescriptor(tn);
for (String family : familyNames)
htd.addFamily(new HColumnDescriptor(family));admin.modifyTable(tn, htd);
conn.close();
System.out.println("modify success!");
}
public static void removeColumnFamily(String tableName, String... familyNames)
throws IOException {
Connection conn = ConnectionFactory.createConnection(cfg);
Admin admin = conn.getAdmin();
TableName tn = TableName.valueOf(tableName);
HTableDescriptor htd = admin.getTableDescriptor(tn);
for (String family : familyNames)
htd.removeFamily(Bytes.toBytes(family));
admin.modifyTable(tn, htd);
conn.close();
System.out.println("remove success!");
}
public static void describe(String tableName)
throws IOException {
Connection conn = ConnectionFactory.createConnection(cfg);
Admin admin = conn.getAdmin();
TableName tn = TableName.valueOf(tableName);
HTableDescriptor htd = admin.getTableDescriptor(tn);
System.out.println("-—=decribe " + tableName + ";===");
for (HColumnDescriptor hcd : htd.getColumnFamilies()){
System.out.println(hcd.getNameAsString());
}
System.out.println("==================================");
conn.close();
}
static void put() throws IOException{
Connection conn = ConnectionFactory.createConnection(cfg);
Table tb=conn.getTable(TableName.valueOf("scores"));
Put p=new Put(Bytes.toBytes("jason"));
p.addColumn(Bytes.toBytes("grade"),Bytes.toBytes(""), Bytes.toBytes("2"));
p.addColumn(Bytes.toBytes("course"),Bytes.toBytes("math"),Bytes.toBytes("57"));
p.addColumn(Bytes.toBytes("course"),Bytes.toBytes("art"),Bytes.toBytes("87"));
tb.put(p);
p=new Put(Bytes.toBytes("zhangguoqiang"));
p.addColumn(Bytes.toBytes("grade"),Bytes.toBytes(""), Bytes.toBytes("1"));
p.addColumn(Bytes.toBytes("course"),Bytes.toBytes("math"),Bytes.toBytes("89"));
p.addColumn(Bytes.toBytes("course"),Bytes.toBytes("art"),Bytes.toBytes("80"));
tb.put(p);
conn.close();
}
public static void main(String[] args) throws IOException {
create("scores" , "grade", "course");
describe("scores");
addColumnFamily("scores", "f1", "f2");
describe("scores");
removeColumnFamily("scores", "f1 ");
describe("scores");
list();
put();
}
}
二、在HBase的 scores表中,此前jason的course:math成绩为57分,现知补考成绩为63分,请使用put命令增加补考成绩,然后使用scan命令显示jason的course:math成绩的所有版本。
代码如下(示例):
import java.io.IOException;
import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.hbase.HBaseConfiguration;
import org.apache.hadoop.hbase.HColumnDescriptor;
import org.apache.hadoop.hbase.HTableDescriptor;
import org.apache.hadoop.hbase.TableName;
import org.apache.hadoop.hbase.client.*;
import org.apache.hadoop.hbase.util.Bytes;
static void put() throws IOException{
Connection conn = ConnectionFactory.createConnection(cfg);
Table tb=conn.getTable(TableName.valueOf("scores"));
Put p=new Put(Bytes.toBytes("jason"));
p.addColumn(Bytes.toBytes("grade"),Bytes.toBytes(""), Bytes.toBytes("2"));
p.addColumn(Bytes.toBytes("course"),Bytes.toBytes("math"),Bytes.toBytes("63"));
p.addColumn(Bytes.toBytes("course"),Bytes.toBytes("art"),Bytes.toBytes("87"));
tb.put(p);
p=new Put(Bytes.toBytes("zhangguoqiang"));
p.addColumn(Bytes.toBytes("grade"),Bytes.toBytes(""), Bytes.toBytes("1"));
p.addColumn(Bytes.toBytes("course"),Bytes.toBytes("math"),Bytes.toBytes("89"));
p.addColumn(Bytes.toBytes("course"),Bytes.toBytes("art"),Bytes.toBytes("80"));
tb.put(p);
conn.close();
}
public static void main(String[] args) throws IOException {
put();
}
三、观察作业5的输出结果,使用get命令获取jason的math课程第一次考试成绩。
代码如下
import java.io.IOException;
import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.hbase.HBaseConfiguration;
import org.apache.hadoop.hbase.TableName;
import org.apache.hadoop.hbase.client.Connection;
import org.apache.hadoop.hbase.client.ConnectionFactory;
import org.apache.hadoop.hbase.client.Get;
import org.apache.hadoop.hbase.client.Result;
import org.apache.hadoop.hbase.client.ResultScanner;
import org.apache.hadoop.hbase.client.Table;
import org.apache.hadoop.hbase.util.Bytes;
import org.apache.hadoop.hbase.client.Scan;
public class HBaseGet {
static Configuration cfg = HBaseConfiguration.create();
static {
cfg.set("hbase.zookeeper.quorum","Cluster-01:2181,Cluster-02:2181,Cluster-03:2181,Cluster-04:2181,Cluster-05:2181,");
cfg.set("hbase.zookeeper.property.clientPort","2181");
}
static void get(String tableName, String rowKey) throws IOException {
Connection conn = ConnectionFactory.createConnection(cfg);
Table tb = conn.getTable(TableName.valueOf(tableName));
Get g = new Get(Bytes.toBytes(rowKey));
Result result = tb.get(g);
System.out.println(String.format(
"result.value=%s,result.toString():%s",
Bytes.toString(result.value()), result));
conn.close();
}
static void get(String tableName, String rowKey, String family)throws IOException{
Connection conn= ConnectionFactory.createConnection(cfg);
Table tb = conn.getTable(TableName.valueOf(tableName));
Get g = new Get(Bytes.toBytes(rowKey));
g.addFamily(Bytes.toBytes(family));
Result result= tb.get(g);
System.out.println(String.format(
"result.value=%s,result.toString():%s",
Bytes.toString(result.value()), result));
conn.close();
}
static void get(String tableName, String rowKey, String family,String qualifier) throws IOException {
Connection conn = ConnectionFactory.createConnection(cfg);
Table tb = conn.getTable(TableName.valueOf(tableName));
Get g = new Get(Bytes.toBytes(rowKey));
g.addColumn(Bytes.toBytes(family),Bytes.toBytes(qualifier));
Result result = tb.get(g);
System.out.println(String.format(
"result.value=%s,result.toString():%s",
Bytes.toString(result.value()), result));
conn.close();
}
public static void main(String[] args) throws IOException {
get("scores", "jason");
get("scores" , "jason", "course");
get("scores", "jason" , "course", "math");
}
}
四、使用 HBase Java API删除scores表中jason的 math 课程成绩。
下面展示一些 内联代码片。
代码如下
import java.io.IOException;
import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.hbase.HBaseConfiguration;
import org.apache.hadoop.hbase.TableName;
import org.apache.hadoop.hbase.client.Connection;
import org.apache.hadoop.hbase.client.ConnectionFactory;
import org.apache.hadoop.hbase.client.Delete;
import org.apache.hadoop.hbase.client.Table;
import org.apache.hadoop.hbase.util.Bytes;
public class HBaseDelete {
static Configuration cfg = HBaseConfiguration.create();
static {
cfg.set("hbase.zookeeper.quorum","Cluster-01:2181,Cluster-02:2181,Cluster-03:2181,Cluster-04:2181,Cluster-05:2181,");
cfg.set("hbase.zookeeper.property.clientPort","2181");
}
public static void main(String[] args) throws IOException{
Connection conn = ConnectionFactory.createConnection(cfg);
Table tb = conn.getTable(TableName.valueOf("scores"));
Delete delete=new Delete(Bytes.toBytes("jason"));
delete.deleteColumn(Bytes.toBytes("course"),Bytes.toBytes("math"));
tb.delete(delete);
conn.close();
}
}
出现的问题与解决方案
问题1: 运行代码出现Exception in thread “main” org.apache.hadoop.hbase.client.RetriesExhaustedException
解决:
1.Hbase版本不一致【服务器上启动的Hbase和Spark导入的Hbase-lib不一致】。
2.hdfs的datanode或namenode宕机。
3.Hbase的Hmaster或者HRegionServer挂了。















 1599
1599











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









